 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdeas in Inference-time Scaling can Benefit Generative Pre-training Algorithms
Mar 11, 2025
Recent years have seen significant advancements in foundation models through generative pre-training, yet algorithmic innovation in this space has largely stagnated around autoregressive models for discrete signals and diffusion models for continuous signals. This stagnation creates a bottleneck that prevents us from fully unlocking the potential of rich multi-modal data, which in turn limits the progress on multimodal intelligence. We argue that an inference-first perspective, which prioritizes scaling efficiency during inference time across sequence length and refinement steps, can inspire novel generative pre-training algorithms. Using Inductive Moment Matching (IMM) as a concrete example, we demonstrate how addressing limitations in diffusion models' inference process through targeted modifications yields a stable, single-stage algorithm that achieves superior sample quality with over an order of magnitude greater inference efficiency.
Inductive Moment Matching
Mar 11, 2025
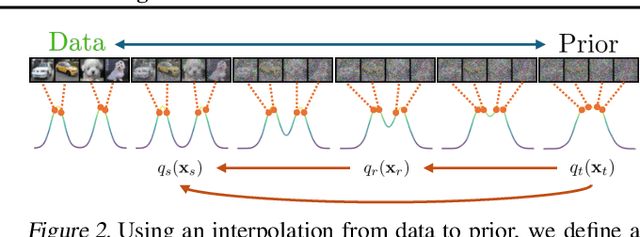


Diffusion models and Flow Matching generate high-quality samples but are slow at inference, and distilling them into few-step models often leads to instability and extensive tuning. To resolve these trade-offs, we propose Inductive Moment Matching (IMM), a new class of generative models for one- or few-step sampling with a single-stage training procedure. Unlike distillation, IMM does not require pre-training initialization and optimization of two networks; and unlike Consistency Models, IMM guarantees distribution-level convergence and remains stable under various hyperparameters and standard model architectures. IMM surpasses diffusion models on ImageNet-256x256 with 1.99 FID using only 8 inference steps and achieves state-of-the-art 2-step FID of 1.98 on CIFAR-10 for a model trained from scratch.
Personalized Preference Fine-tuning of Diffusion Models
Jan 11, 2025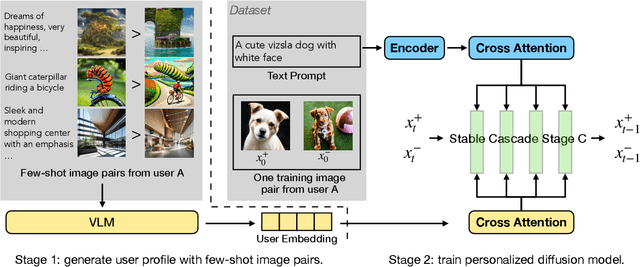
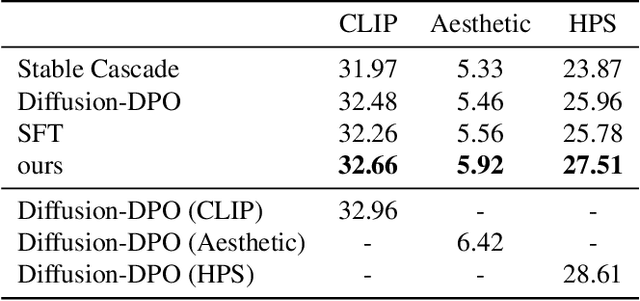
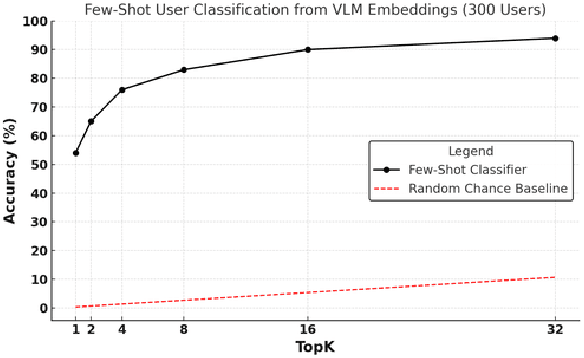

RLHF techniques like DPO can significantly improve the generation quality of text-to-image diffusion models. However, these methods optimize for a single reward that aligns model generation with population-level preferences, neglecting the nuances of individual users' beliefs or values. This lack of personalization limits the efficacy of these models. To bridge this gap, we introduce PPD, a multi-reward optimization objective that aligns diffusion models with personalized preferences. With PPD, a diffusion model learns the individual preferences of a population of users in a few-shot way, enabling generalization to unseen users. Specifically, our approach (1) leverages a vision-language model (VLM) to extract personal preference embeddings from a small set of pairwise preference examples, and then (2) incorporates the embeddings into diffusion models through cross attention. Conditioning on user embeddings, the text-to-image models are fine-tuned with the DPO objective, simultaneously optimizing for alignment with the preferences of multiple users. Empirical results demonstrate that our method effectively optimizes for multiple reward functions and can interpolate between them during inference. In real-world user scenarios, with as few as four preference examples from a new user, our approach achieves an average win rate of 76\% over Stable Cascade, generating images that more accurately reflect specific user preferences.
3D-Adapter: Geometry-Consistent Multi-View Diffusion for High-Quality 3D Generation
Oct 24, 2024
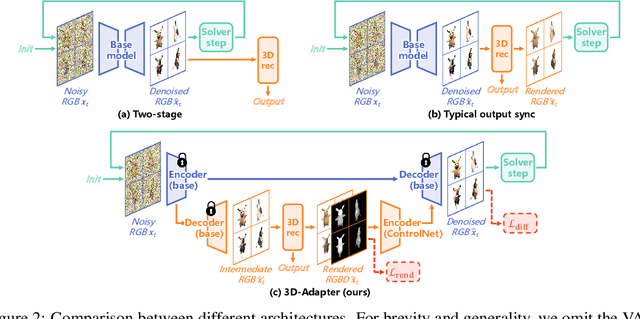
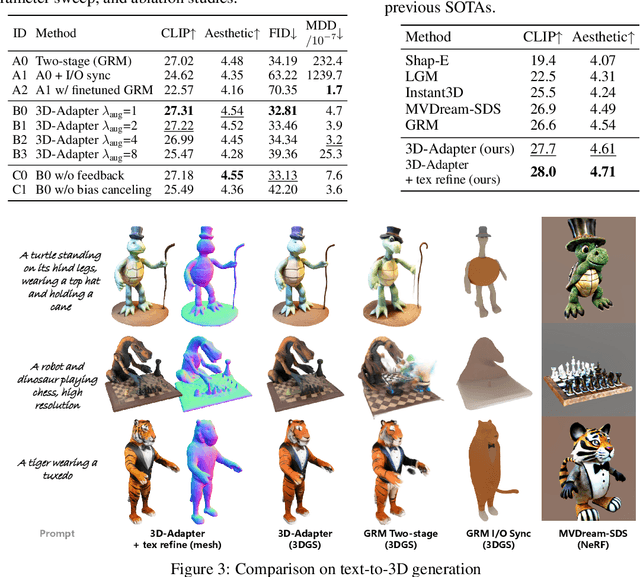
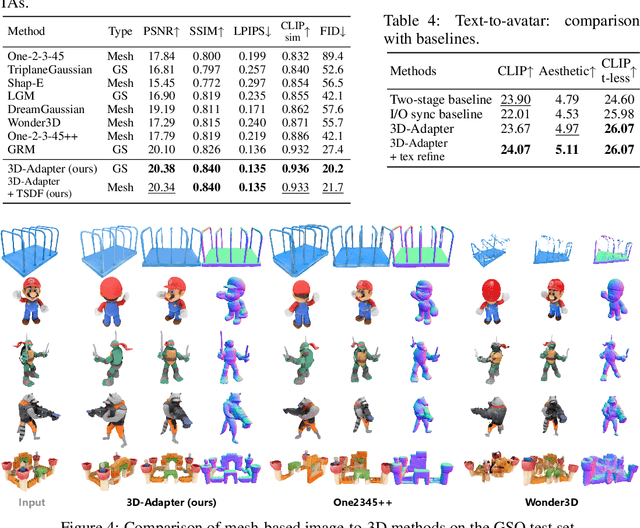
Multi-view image diffusion models have significantly advanced open-domain 3D object generation. However, most existing models rely on 2D network architectures that lack inherent 3D biases, resulting in compromised geometric consistency. To address this challenge, we introduce 3D-Adapter, a plug-in module designed to infuse 3D geometry awareness into pretrained image diffusion models. Central to our approach is the idea of 3D feedback augmentation: for each denoising step in the sampling loop, 3D-Adapter decodes intermediate multi-view features into a coherent 3D representation, then re-encodes the rendered RGBD views to augment the pretrained base model through feature addition. We study two variants of 3D-Adapter: a fast feed-forward version based on Gaussian splatting and a versatile training-free version utilizing neural fields and meshes. Our extensive experiments demonstrate that 3D-Adapter not only greatly enhances the geometry quality of text-to-multi-view models such as Instant3D and Zero123++, but also enables high-quality 3D generation using the plain text-to-image Stable Diffusion. Furthermore, we showcase the broad application potential of 3D-Adapter by presenting high quality results in text-to-3D, image-to-3D, text-to-texture, and text-to-avatar tasks.
Consistency Policy: Accelerated Visuomotor Policies via Consistency Distillation
May 13, 2024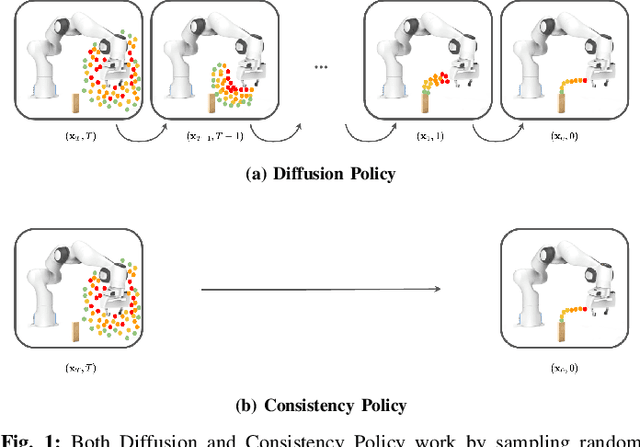
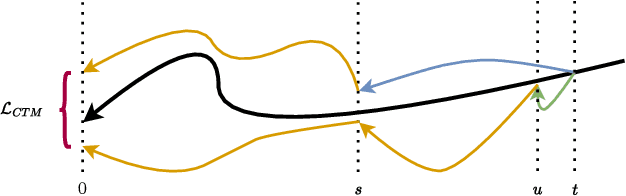


Many robotic systems, such as mobile manipulators or quadrotors, cannot be equipped with high-end GPUs due to space, weight, and power constraints. These constraints prevent these systems from leveraging recent developments in visuomotor policy architectures that require high-end GPUs to achieve fast policy inference. In this paper, we propose Consistency Policy, a faster and similarly powerful alternative to Diffusion Policy for learning visuomotor robot control. By virtue of its fast inference speed, Consistency Policy can enable low latency decision making in resource-constrained robotic setups. A Consistency Policy is distilled from a pretrained Diffusion Policy by enforcing self-consistency along the Diffusion Policy's learned trajectories. We compare Consistency Policy with Diffusion Policy and other related speed-up methods across 6 simulation tasks as well as two real-world tasks where we demonstrate inference on a laptop GPU. For all these tasks, Consistency Policy speeds up inference by an order of magnitude compared to the fastest alternative method and maintains competitive success rates. We also show that the Conistency Policy training procedure is robust to the pretrained Diffusion Policy's quality, a useful result that helps practioners avoid extensive testing of the pretrained model. Key design decisions that enabled this performance are the choice of consistency objective, reduced initial sample variance, and the choice of preset chaining steps. Code and training details will be released publicly.
DiffusionSat: A Generative Foundation Model for Satellite Imagery
Dec 06, 2023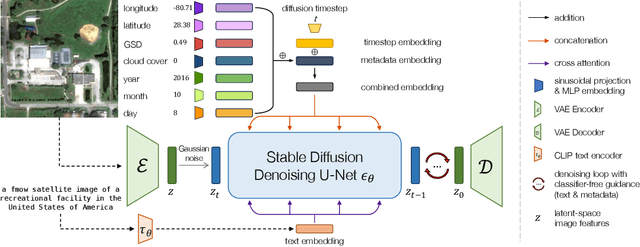
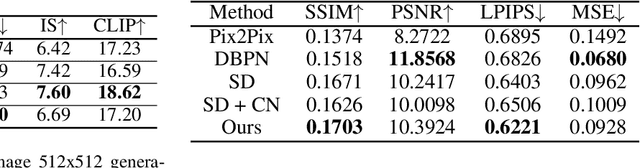
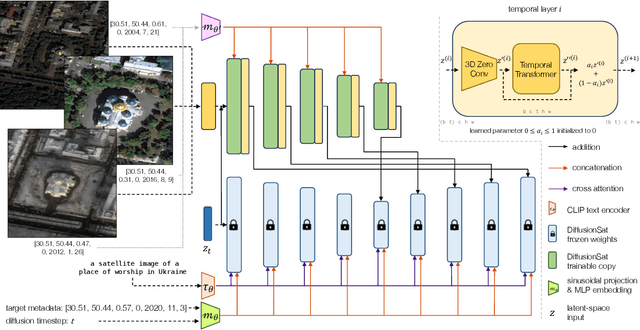

Diffusion models have achieved state-of-the-art results on many modalities including images, speech, and video. However, existing models are not tailored to support remote sensing data, which is widely used in important applications including environmental monitoring and crop-yield prediction. Satellite images are significantly different from natural images -- they can be multi-spectral, irregularly sampled across time -- and existing diffusion models trained on images from the Web do not support them. Furthermore, remote sensing data is inherently spatio-temporal, requiring conditional generation tasks not supported by traditional methods based on captions or images. In this paper, we present DiffusionSat, to date the largest generative foundation model trained on a collection of publicly available large, high-resolution remote sensing datasets. As text-based captions are sparsely available for satellite images, we incorporate the associated metadata such as geolocation as conditioning information. Our method produces realistic samples and can be used to solve multiple generative tasks including temporal generation, superresolution given multi-spectral inputs and in-painting. Our method outperforms previous state-of-the-art methods for satellite image generation and is the first large-scale $\textit{generative}$ foundation model for satellite imagery.
DreamPropeller: Supercharge Text-to-3D Generation with Parallel Sampling
Dec 06, 2023



Recent methods such as Score Distillation Sampling (SDS) and Variational Score Distillation (VSD) using 2D diffusion models for text-to-3D generation have demonstrated impressive generation quality. However, the long generation time of such algorithms significantly degrades the user experience. To tackle this problem, we propose DreamPropeller, a drop-in acceleration algorithm that can be wrapped around any existing text-to-3D generation pipeline based on score distillation. Our framework generalizes Picard iterations, a classical algorithm for parallel sampling an ODE path, and can account for non-ODE paths such as momentum-based gradient updates and changes in dimensions during the optimization process as in many cases of 3D generation. We show that our algorithm trades parallel compute for wallclock time and empirically achieves up to 4.7x speedup with a negligible drop in generation quality for all tested frameworks.
Diffusion Model Alignment Using Direct Preference Optimization
Nov 21, 2023



Large language models (LLMs) are fine-tuned using human comparison data with Reinforcement Learning from Human Feedback (RLHF) methods to make them better aligned with users' preferences. In contrast to LLMs, human preference learning has not been widely explored in text-to-image diffusion models; the best existing approach is to fine-tune a pretrained model using carefully curated high quality images and captions to improve visual appeal and text alignment. We propose Diffusion-DPO, a method to align diffusion models to human preferences by directly optimizing on human comparison data. Diffusion-DPO is adapted from the recently developed Direct Preference Optimization (DPO), a simpler alternative to RLHF which directly optimizes a policy that best satisfies human preferences under a classification objective. We re-formulate DPO to account for a diffusion model notion of likelihood, utilizing the evidence lower bound to derive a differentiable objective. Using the Pick-a-Pic dataset of 851K crowdsourced pairwise preferences, we fine-tune the base model of the state-of-the-art Stable Diffusion XL (SDXL)-1.0 model with Diffusion-DPO. Our fine-tuned base model significantly outperforms both base SDXL-1.0 and the larger SDXL-1.0 model consisting of an additional refinement model in human evaluation, improving visual appeal and prompt alignment. We also develop a variant that uses AI feedback and has comparable performance to training on human preferences, opening the door for scaling of diffusion model alignment methods.
AO-Grasp: Articulated Object Grasp Generation
Oct 24, 2023



We introduce AO-Grasp, a grasp proposal method that generates stable and actionable 6 degree-of-freedom grasps for articulated objects. Our generated grasps enable robots to interact with articulated objects, such as opening and closing cabinets and appliances. Given a segmented partial point cloud of a single articulated object, AO-Grasp predicts the best grasp points on the object with a novel Actionable Grasp Point Predictor model and then finds corresponding grasp orientations for each point by leveraging a state-of-the-art rigid object grasping method. We train AO-Grasp on our new AO-Grasp Dataset, which contains 48K actionable parallel-jaw grasps on synthetic articulated objects. In simulation, AO-Grasp achieves higher grasp success rates than existing rigid object grasping and articulated object interaction baselines on both train and test categories. Additionally, we evaluate AO-Grasp on 120 realworld scenes of objects with varied geometries, articulation axes, and joint states, where AO-Grasp produces successful grasps on 67.5% of scenes, while the baseline only produces successful grasps on 33.3% of scenes.
Denoising Diffusion Bridge Models
Sep 29, 2023



Diffusion models are powerful generative models that map noise to data using stochastic processes. However, for many applications such as image editing, the model input comes from a distribution that is not random noise. As such, diffusion models must rely on cumbersome methods like guidance or projected sampling to incorporate this information in the generative process. In our work, we propose Denoising Diffusion Bridge Models (DDBMs), a natural alternative to this paradigm based on diffusion bridges, a family of processes that interpolate between two paired distributions given as endpoints. Our method learns the score of the diffusion bridge from data and maps from one endpoint distribution to the other by solving a (stochastic) differential equation based on the learned score. Our method naturally unifies several classes of generative models, such as score-based diffusion models and OT-Flow-Matching, allowing us to adapt existing design and architectural choices to our more general problem. Empirically, we apply DDBMs to challenging image datasets in both pixel and latent space. On standard image translation problems, DDBMs achieve significant improvement over baseline methods, and, when we reduce the problem to image generation by setting the source distribution to random noise, DDBMs achieve comparable FID scores to state-of-the-art methods despite being built for a more general task.