 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-Adapter: Geometry-Consistent Multi-View Diffusion for High-Quality 3D Generation
Oct 24, 2024
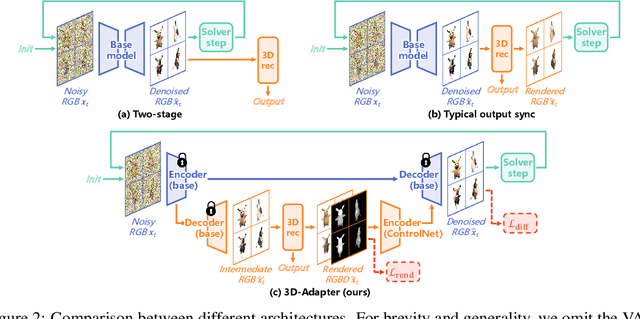
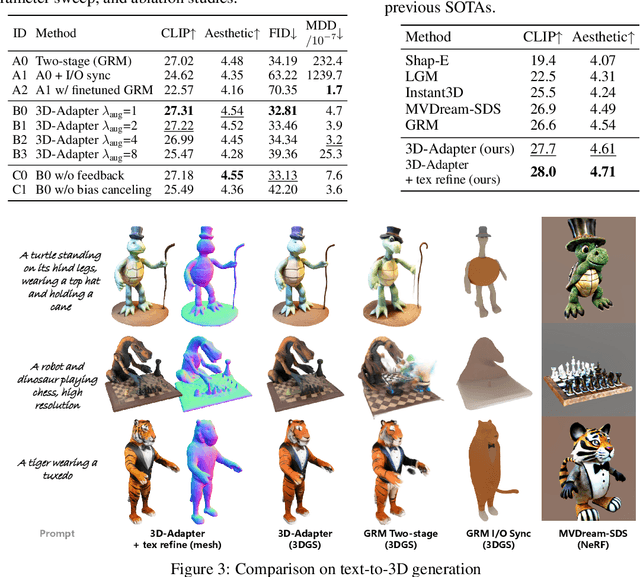
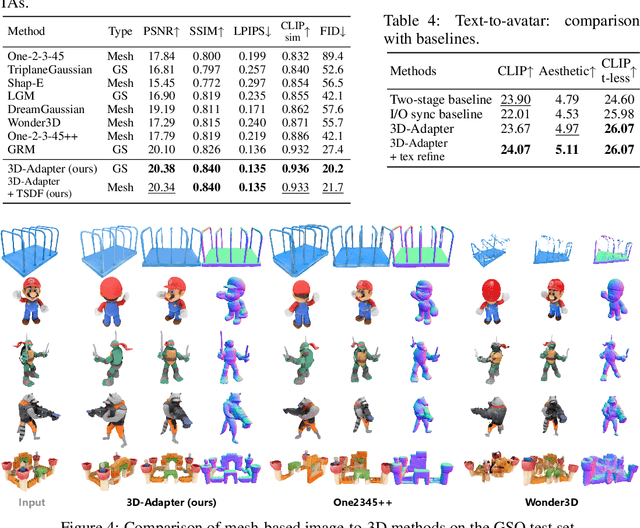
Multi-view image diffusion models have significantly advanced open-domain 3D object generation. However, most existing models rely on 2D network architectures that lack inherent 3D biases, resulting in compromised geometric consistency. To address this challenge, we introduce 3D-Adapter, a plug-in module designed to infuse 3D geometry awareness into pretrained image diffusion models. Central to our approach is the idea of 3D feedback augmentation: for each denoising step in the sampling loop, 3D-Adapter decodes intermediate multi-view features into a coherent 3D representation, then re-encodes the rendered RGBD views to augment the pretrained base model through feature addition. We study two variants of 3D-Adapter: a fast feed-forward version based on Gaussian splatting and a versatile training-free version utilizing neural fields and meshes. Our extensive experiments demonstrate that 3D-Adapter not only greatly enhances the geometry quality of text-to-multi-view models such as Instant3D and Zero123++, but also enables high-quality 3D generation using the plain text-to-image Stable Diffusion. Furthermore, we showcase the broad application potential of 3D-Adapter by presenting high quality results in text-to-3D, image-to-3D, text-to-texture, and text-to-avatar tasks.
MultiPhys: Multi-Person Physics-aware 3D Motion Estimation
Apr 18, 2024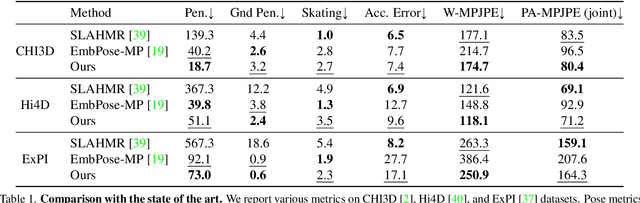

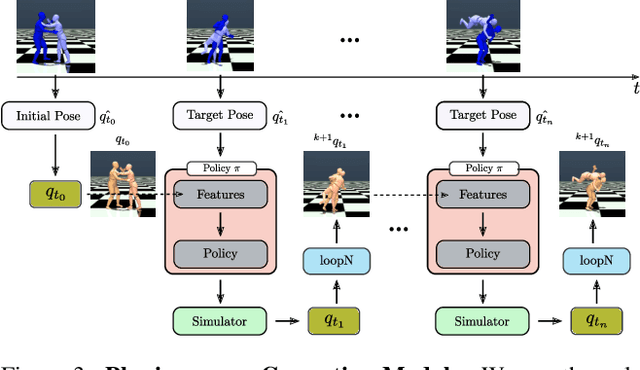
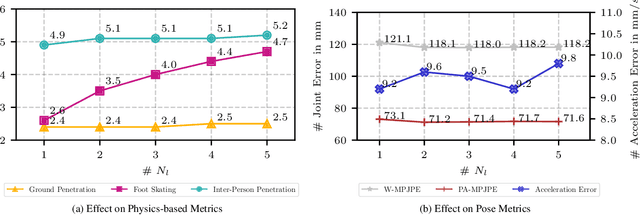
We introduce MultiPhys, a method designed for recovering multi-person motion from monocular videos. Our focus lies in capturing coherent spatial placement between pairs of individuals across varying degrees of engagement. MultiPhys, being physically aware, exhibits robustness to jittering and occlusions, and effectively eliminates penetration issues between the two individuals. We devise a pipeline in which the motion estimated by a kinematic-based method is fed into a physics simulator in an autoregressive manner. We introduce distinct components that enable our model to harness the simulator's properties without compromising the accuracy of the kinematic estimates. This results in final motion estimates that are both kinematically coherent and physically compliant. Extensive evaluations on three challenging datasets characterized by substantial inter-person interaction show that our method significantly reduces errors associated with penetration and foot skating, while performing competitively with the state-of-the-art on motion accuracy and smoothness. Results and code can be found on our project page (http://www.iri.upc.edu/people/nugrinovic/multiphys/).
Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
Mar 19, 2024



Open-domain 3D object synthesis has been lagging behind image synthesis due to limited data and higher computational complexity. To bridge this gap, recent works have investigated multi-view diffusion but often fall short in either 3D consistency, visual quality, or efficiency. This paper proposes MVEdit, which functions as a 3D counterpart of SDEdit, employing ancestral sampling to jointly denoise multi-view images and output high-quality textured meshes. Built on off-the-shelf 2D diffusion models, MVEdit achieves 3D consistency through a training-free 3D Adapter, which lifts the 2D views of the last timestep into a coherent 3D representation, then conditions the 2D views of the next timestep using rendered views, without uncompromising visual quality. With an inference time of only 2-5 minutes, this framework achieves better trade-off between quality and speed than score distillation. MVEdit is highly versatile and extendable, with a wide range of applications including text/image-to-3D generation, 3D-to-3D editing, and high-quality texture synthesis. In particular, evaluations demonstrate state-of-the-art performance in both image-to-3D and text-guided texture generation tasks. Additionally, we introduce a method for fine-tuning 2D latent diffusion models on small 3D datasets with limited resources, enabling fast low-resolution text-to-3D initialization.
CAD: Photorealistic 3D Generation via Adversarial Distillation
Dec 11, 2023



The increased demand for 3D data in AR/VR, robotics and gaming applications, gave rise to powerful generative pipelines capable of synthesizing high-quality 3D objects. Most of these models rely on the Score Distillation Sampling (SDS) algorithm to optimize a 3D representation such that the rendered image maintains a high likelihood as evaluated by a pre-trained diffusion model. However, finding a correct mode in the high-dimensional distribution produced by the diffusion model is challenging and often leads to issues such as over-saturation, over-smoothing, and Janus-like artifacts. In this paper, we propose a novel learning paradigm for 3D synthesis that utilizes pre-trained diffusion models. Instead of focusing on mode-seeking, our method directly models the distribution discrepancy between multi-view renderings and diffusion priors in an adversarial manner, which unlocks the generation of high-fidelity and photorealistic 3D content, conditioned on a single image and prompt. Moreover, by harnessing the latent space of GANs and expressive diffusion model priors, our method facilitates a wide variety of 3D applications including single-view reconstruction, high diversity generation and continuous 3D interpolation in the open domain. The experiments demonstrate the superiority of our pipeline compared to previous works in terms of generation quality and diversity.
SAGE: Bridging Semantic and Actionable Parts for GEneralizable Articulated-Object Manipulation under Language Instructions
Dec 03, 2023Generalizable manipulation of articulated objects remains a challenging problem in many real-world scenarios, given the diverse object structures, functionalities, and goals. In these tasks, both semantic interpretations and physical plausibilities are crucial for a policy to succeed. To address this problem, we propose SAGE, a novel framework that bridges the understanding of semantic and actionable parts of articulated objects to achieve generalizable manipulation under language instructions. Given a manipulation goal specified by natural language, an instruction interpreter with Large Language Models (LLMs) first translates them into programmatic actions on the object's semantic parts. This process also involves a scene context parser for understanding the visual inputs, which is designed to generate scene descriptions with both rich information and accurate interaction-related facts by joining the forces of generalist Visual-Language Models (VLMs) and domain-specialist part perception models. To further convert the action programs into executable policies, a part grounding module then maps the object semantic parts suggested by the instruction interpreter into so-called Generalizable Actionable Parts (GAParts). Finally, an interactive feedback module is incorporated to respond to failures, which greatly increases the robustness of the overall framework. Experiments both in simulation environments and on real robots show that our framework can handle a large variety of articulated objects with diverse language-instructed goals. We also provide a new benchmark for language-guided articulated-object manipulation in realistic scenarios.
Make a Donut: Language-Guided Hierarchical EMD-Space Planning for Zero-shot Deformable Object Manipulation
Nov 05, 2023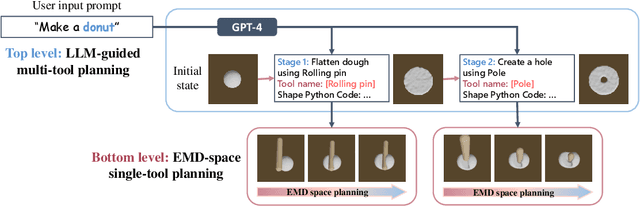
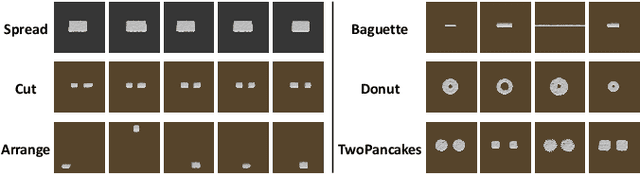
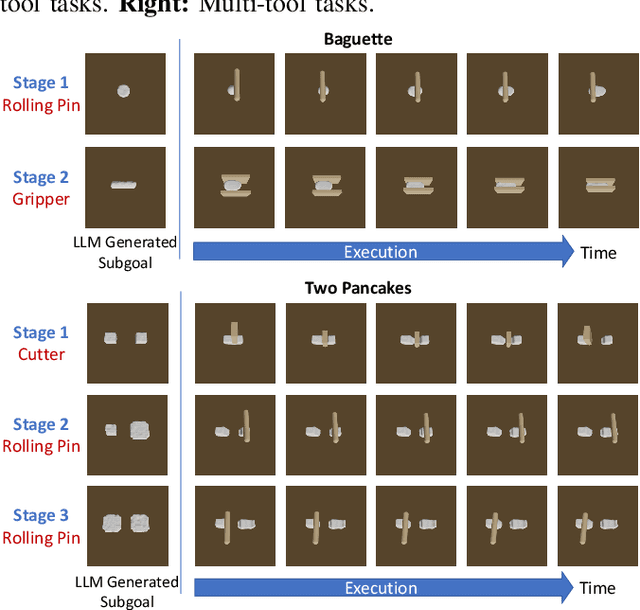
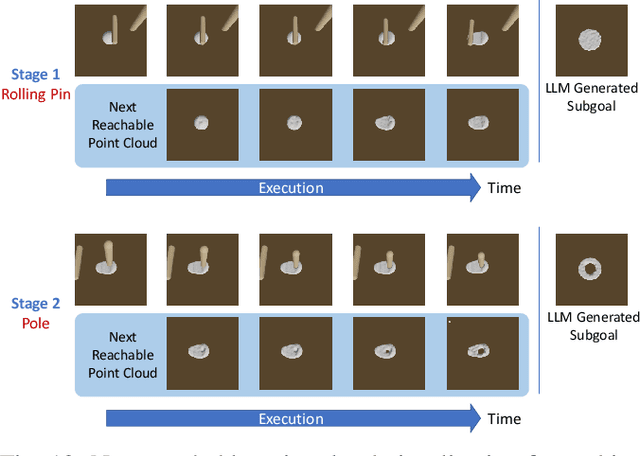
Deformable object manipulation stands as one of the most captivating yet formidable challenges in robotics. While previous techniques have predominantly relied on learning latent dynamics through demonstrations, typically represented as either particles or images, there exists a pertinent limitation: acquiring suitable demonstrations, especially for long-horizon tasks, can be elusive. Moreover, basing learning entirely on demonstrations can hamper the model's ability to generalize beyond the demonstrated tasks. In this work, we introduce a demonstration-free hierarchical planning approach capable of tackling intricate long-horizon tasks without necessitating any training. We employ large language models (LLMs) to articulate a high-level, stage-by-stage plan corresponding to a specified task. For every individual stage, the LLM provides both the tool's name and the Python code to craft intermediate subgoal point clouds. With the tool and subgoal for a particular stage at our disposal, we present a granular closed-loop model predictive control strategy. This leverages Differentiable Physics with Point-to-Point correspondence (DiffPhysics-P2P) loss in the earth mover distance (EMD) space, applied iteratively. Experimental findings affirm that our technique surpasses multiple benchmarks in dough manipulation, spanning both short and long horizons. Remarkably, our model demonstrates robust generalization capabilities to novel and previously unencountered complex tasks without any preliminary demonstrations. We further substantiate our approach with experimental trials on real-world robotic platforms.
PointOdyssey: A Large-Scale Synthetic Dataset for Long-Term Point Tracking
Jul 27, 2023



We introduce PointOdyssey, a large-scale synthetic dataset, and data generation framework, for the training and evaluation of long-term fine-grained tracking algorithms. Our goal is to advance the state-of-the-art by placing emphasis on long videos with naturalistic motion. Toward the goal of naturalism, we animate deformable characters using real-world motion capture data, we build 3D scenes to match the motion capture environments, and we render camera viewpoints using trajectories mined via structure-from-motion on real videos. We create combinatorial diversity by randomizing character appearance, motion profiles, materials, lighting, 3D assets, and atmospheric effects. Our dataset currently includes 104 videos, averaging 2,000 frames long, with orders of magnitude more correspondence annotations than prior work. We show that existing methods can be trained from scratch in our dataset and outperform the published variants. Finally, we introduce modifications to the PIPs point tracking method, greatly widening its temporal receptive field, which improves its performance on PointOdyssey as well as on two real-world benchmarks. Our data and code are publicly available at: https://pointodyssey.com
Banana: Banach Fixed-Point Network for Pointcloud Segmentation with Inter-Part Equivariance
May 26, 2023Equivariance has gained strong interest as a desirable network property that inherently ensures robust generalization. However, when dealing with complex systems such as articulated objects or multi-object scenes, effectively capturing inter-part transformations poses a challenge, as it becomes entangled with the overall structure and local transformations. The interdependence of part assignment and per-part group action necessitates a novel equivariance formulation that allows for their co-evolution. In this paper, we present Banana, a Banach fixed-point network for equivariant segmentation with inter-part equivariance by construction. Our key insight is to iteratively solve a fixed-point problem, where point-part assignment labels and per-part SE(3)-equivariance co-evolve simultaneously. We provide theoretical derivations of both per-step equivariance and global convergence, which induces an equivariant final convergent state. Our formulation naturally provides a strict definition of inter-part equivariance that generalizes to unseen inter-part configurations. Through experiments conducted on both articulated objects and multi-object scans, we demonstrate the efficacy of our approach in achieving strong generalization under inter-part transformations, even when confronted with substantial changes in pointcloud geometry and topology.
NAP: Neural 3D Articulation Prior
May 25, 2023We propose Neural 3D Articulation Prior (NAP), the first 3D deep generative model to synthesize 3D articulated object models. Despite the extensive research on generating 3D objects, compositions, or scenes, there remains a lack of focus on capturing the distribution of articulated objects, a common object category for human and robot interaction. To generate articulated objects, we first design a novel articulation tree/graph parameterization and then apply a diffusion-denoising probabilistic model over this representation where articulated objects can be generated via denoising from random complete graphs. In order to capture both the geometry and the motion structure whose distribution will affect each other, we design a graph-attention denoising network for learning the reverse diffusion process. We propose a novel distance that adapts widely used 3D generation metrics to our novel task to evaluate generation quality, and experiments demonstrate our high performance in articulated object generation. We also demonstrate several conditioned generation applications, including Part2Motion, PartNet-Imagination, Motion2Part, and GAPart2Object.
GINA-3D: Learning to Generate Implicit Neural Assets in the Wild
Apr 04, 2023



Modeling the 3D world from sensor data for simulation is a scalable way of developing testing and validation environments for robotic learning problems such as autonomous driving. However, manually creating or re-creating real-world-like environments is difficult, expensive, and not scalable. Recent generative model techniques have shown promising progress to address such challenges by learning 3D assets using only plentiful 2D images -- but still suffer limitations as they leverage either human-curated image datasets or renderings from manually-created synthetic 3D environments. In this paper, we introduce GINA-3D, a generative model that uses real-world driving data from camera and LiDAR sensors to create realistic 3D implicit neural assets of diverse vehicles and pedestrians. Compared to the existing image datasets, the real-world driving setting poses new challenges due to occlusions, lighting-variations and long-tail distributions. GINA-3D tackles these challenges by decoupling representation learning and generative modeling into two stages with a learned tri-plane latent structure, inspired by recent advances in generative modeling of images. To evaluate our approach, we construct a large-scale object-centric dataset containing over 520K images of vehicles and pedestrians from the Waymo Open Dataset, and a new set of 80K images of long-tail instances such as construction equipment, garbage trucks, and cable cars. We compare our model with existing approaches and demonstrate that it achieves state-of-the-art performance in quality and diversity for both generated images and geometries.