 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiPhys: Multi-Person Physics-aware 3D Motion Estimation
Apr 18, 2024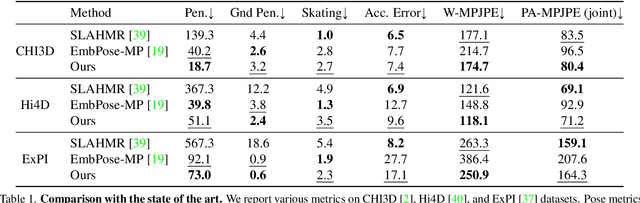

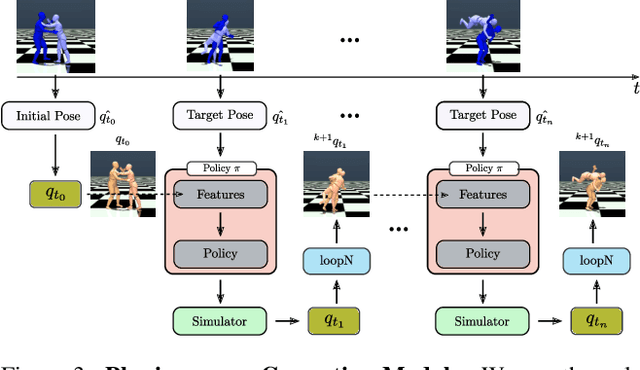
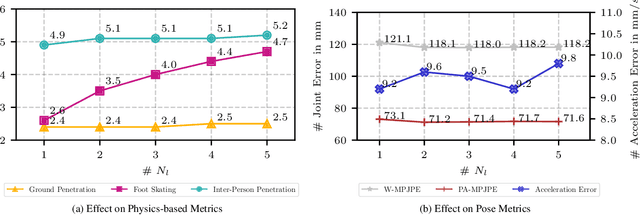
We introduce MultiPhys, a method designed for recovering multi-person motion from monocular videos. Our focus lies in capturing coherent spatial placement between pairs of individuals across varying degrees of engagement. MultiPhys, being physically aware, exhibits robustness to jittering and occlusions, and effectively eliminates penetration issues between the two individuals. We devise a pipeline in which the motion estimated by a kinematic-based method is fed into a physics simulator in an autoregressive manner. We introduce distinct components that enable our model to harness the simulator's properties without compromising the accuracy of the kinematic estimates. This results in final motion estimates that are both kinematically coherent and physically compliant. Extensive evaluations on three challenging datasets characterized by substantial inter-person interaction show that our method significantly reduces errors associated with penetration and foot skating, while performing competitively with the state-of-the-art on motion accuracy and smoothness. Results and code can be found on our project page (http://www.iri.upc.edu/people/nugrinovic/multiphys/).
PhysXNet: A Customizable Approach for LearningCloth Dynamics on Dressed People
Nov 13, 2021
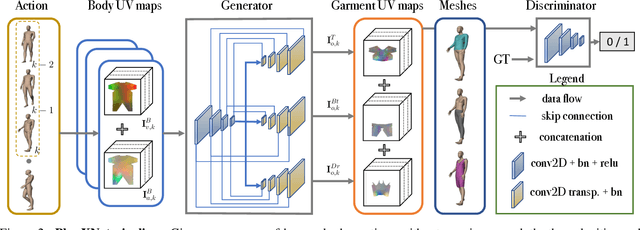

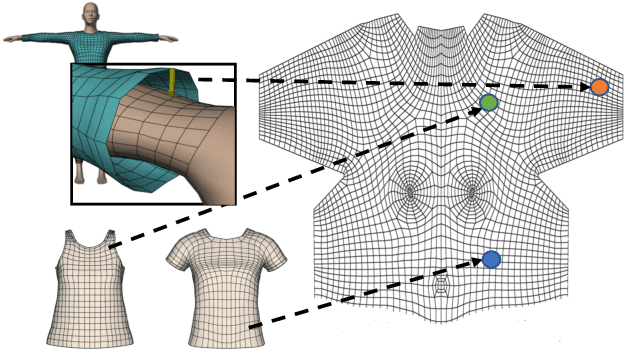
We introduce PhysXNet, a learning-based approach to predict the dynamics of deformable clothes given 3D skeleton motion sequences of humans wearing these clothes. The proposed model is adaptable to a large variety of garments and changing topologies, without need of being retrained. Such simulations are typically carried out by physics engines that require manual human expertise and are subjectto computationally intensive computations. PhysXNet, by contrast, is a fully differentiable deep network that at inference is able to estimate the geometry of dense cloth meshes in a matter of milliseconds, and thus, can be readily deployed as a layer of a larger deep learning architecture. This efficiency is achieved thanks to the specific parameterization of the clothes we consider, based on 3D UV maps encoding spatial garment displacements. The problem is then formulated as a mapping between the human kinematics space (represented also by 3D UV maps of the undressed body mesh) into the clothes displacement UV maps, which we learn using a conditional GAN with a discriminator that enforces feasible deformations. We train simultaneously our model for three garment templates, tops, bottoms and dresses for which we simulate deformations under 50 different human actions. Nevertheless, the UV map representation we consider allows encapsulating many different cloth topologies, and at test we can simulate garments even if we did not specifically train for them. A thorough evaluation demonstrates that PhysXNet delivers cloth deformations very close to those computed with the physical engine, opening the door to be effectively integrated within deeplearning pipelines.
Grasp-Oriented Fine-grained Cloth Segmentation without Real Supervision
Oct 06, 2021


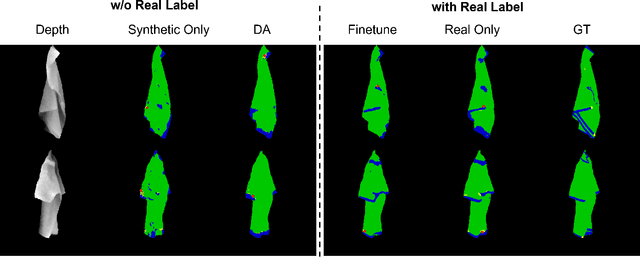
Automatically detecting graspable regions from a single depth image is a key ingredient in cloth manipulation. The large variability of cloth deformations has motivated most of the current approaches to focus on identifying specific grasping points rather than semantic parts, as the appearance and depth variations of local regions are smaller and easier to model than the larger ones. However, tasks like cloth folding or assisted dressing require recognising larger segments, such as semantic edges that carry more information than points. The first goal of this paper is therefore to tackle the problem of fine-grained region detection in deformed clothes using only a depth image. As a proof of concept, we implement an approach for T-shirts, and define up to 6 semantic regions of varying extent, including edges on the neckline, sleeve cuffs, and hem, plus top and bottom grasping points. We introduce a U-net based network to segment and label these parts. The second contribution of our work is concerned with the level of supervision that we require to train the proposed network. While most approaches learn to detect grasping points by combining real and synthetic annotations, in this work we defy the limitations of the synthetic data, and propose a multilayered domain adaptation (DA) strategy that does not use real annotations at all. We thoroughly evaluate our approach on real depth images of a T-shirt annotated with fine-grained labels. We show that training our network solely with synthetic data and the proposed DA yields results competitive with models trained on real data.