 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasp-Oriented Fine-grained Cloth Segmentation without Real Supervision
Oct 06, 2021


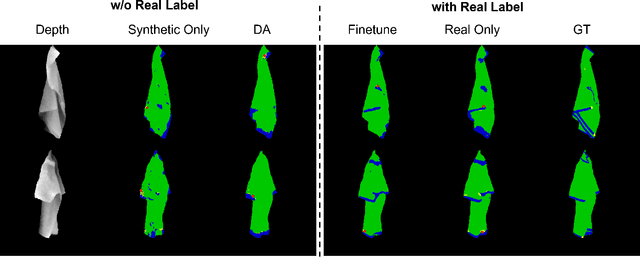
Automatically detecting graspable regions from a single depth image is a key ingredient in cloth manipulation. The large variability of cloth deformations has motivated most of the current approaches to focus on identifying specific grasping points rather than semantic parts, as the appearance and depth variations of local regions are smaller and easier to model than the larger ones. However, tasks like cloth folding or assisted dressing require recognising larger segments, such as semantic edges that carry more information than points. The first goal of this paper is therefore to tackle the problem of fine-grained region detection in deformed clothes using only a depth image. As a proof of concept, we implement an approach for T-shirts, and define up to 6 semantic regions of varying extent, including edges on the neckline, sleeve cuffs, and hem, plus top and bottom grasping points. We introduce a U-net based network to segment and label these parts. The second contribution of our work is concerned with the level of supervision that we require to train the proposed network. While most approaches learn to detect grasping points by combining real and synthetic annotations, in this work we defy the limitations of the synthetic data, and propose a multilayered domain adaptation (DA) strategy that does not use real annotations at all. We thoroughly evaluate our approach on real depth images of a T-shirt annotated with fine-grained labels. We show that training our network solely with synthetic data and the proposed DA yields results competitive with models trained on real data.