 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRGi: View-dependent Instant Recoloring of 3D Gaussians Splats
Mar 03, 20263D Gaussian Splatting (3DGS) has recently transformed the fields of novel view synthesis and 3D reconstruction due to its ability to accurately model complex 3D scenes and its unprecedented rendering performance. However, a significant challenge persists: the absence of an efficient and photorealistic method for editing the appearance of the scene's content. In this paper we introduce VIRGi, a novel approach for rapidly editing the color of scenes modeled by 3DGS while preserving view-dependent effects such as specular highlights. Key to our method are a novel architecture that separates color into diffuse and view-dependent components, and a multi-view training strategy that integrates image patches from multiple viewpoints. Improving over the conventional single-view batch training, our 3DGS representation provides more accurate reconstruction and serves as a solid representation for the recoloring task. For 3DGS recoloring, we then introduce a rapid scheme requiring only one manually edited image of the scene from the end-user. By fine-tuning the weights of a single MLP, alongside a module for single-shot segmentation of the editable area, the color edits are seamlessly propagated to the entire scene in just two seconds, facilitating real-time interaction and providing control over the strength of the view-dependent effects. An exhaustive validation on diverse datasets demonstrates significant quantitative and qualitative advancements over competitors based on Neural Radiance Fields representations.
PLACID: Identity-Preserving Multi-Object Compositing via Video Diffusion with Synthetic Trajectories
Jan 30, 2026Recent advances in generative AI have dramatically improved photorealistic image synthesis, yet they fall short for studio-level multi-object compositing. This task demands simultaneous (i) near-perfect preservation of each item's identity, (ii) precise background and color fidelity, (iii) layout and design elements control, and (iv) complete, appealing displays showcasing all objects. However, current state-of-the-art models often alter object details, omit or duplicate objects, and produce layouts with incorrect relative sizing or inconsistent item presentations. To bridge this gap, we introduce PLACID, a framework that transforms a collection of object images into an appealing multi-object composite. Our approach makes two main contributions. First, we leverage a pretrained image-to-video (I2V) diffusion model with text control to preserve objects consistency, identities, and background details by exploiting temporal priors from videos. Second, we propose a novel data curation strategy that generates synthetic sequences where randomly placed objects smoothly move to their target positions. This synthetic data aligns with the video model's temporal priors during training. At inference, objects initialized at random positions consistently converge into coherent layouts guided by text, with the final frame serving as the composite image. Extensive quantitative evaluations and user studies demonstrate that PLACID surpasses state-of-the-art methods in multi-object compositing, achieving superior identity, background, and color preservation, with less omitted objects and visually appealing results.
InstantGeoAvatar: Effective Geometry and Appearance Modeling of Animatable Avatars from Monocular Video
Nov 03, 2024



We present InstantGeoAvatar, a method for efficient and effective learning from monocular video of detailed 3D geometry and appearance of animatable implicit human avatars. Our key observation is that the optimization of a hash grid encoding to represent a signed distance function (SDF) of the human subject is fraught with instabilities and bad local minima. We thus propose a principled geometry-aware SDF regularization scheme that seamlessly fits into the volume rendering pipeline and adds negligible computational overhead. Our regularization scheme significantly outperforms previous approaches for training SDFs on hash grids. We obtain competitive results in geometry reconstruction and novel view synthesis in as little as five minutes of training time, a significant reduction from the several hours required by previous work. InstantGeoAvatar represents a significant leap forward towards achieving interactive reconstruction of virtual avatars.
TranSPORTmer: A Holistic Approach to Trajectory Understanding in Multi-Agent Sports
Oct 23, 2024Understanding trajectories in multi-agent scenarios requires addressing various tasks, including predicting future movements, imputing missing observations, inferring the status of unseen agents, and classifying different global states. Traditional data-driven approaches often handle these tasks separately with specialized models. We introduce TranSPORTmer, a unified transformer-based framework capable of addressing all these tasks, showcasing its application to the intricate dynamics of multi-agent sports scenarios like soccer and basketball. Using Set Attention Blocks, TranSPORTmer effectively captures temporal dynamics and social interactions in an equivariant manner. The model's tasks are guided by an input mask that conceals missing or yet-to-be-predicted observations. Additionally, we introduce a CLS extra agent to classify states along soccer trajectories, including passes, possessions, uncontrolled states, and out-of-play intervals, contributing to an enhancement in modeling trajectories. Evaluations on soccer and basketball datasets show that TranSPORTmer outperforms state-of-the-art task-specific models in player forecasting, player forecasting-imputation, ball inference, and ball imputation. https://youtu.be/8VtSRm8oGoE
PoseEmbroider: Towards a 3D, Visual, Semantic-aware Human Pose Representation
Sep 10, 2024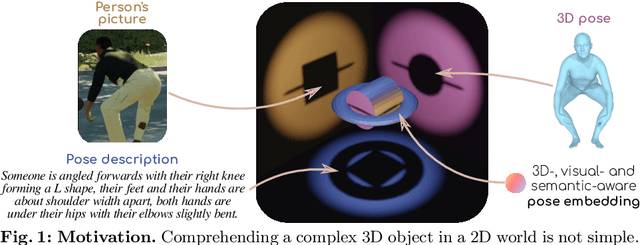
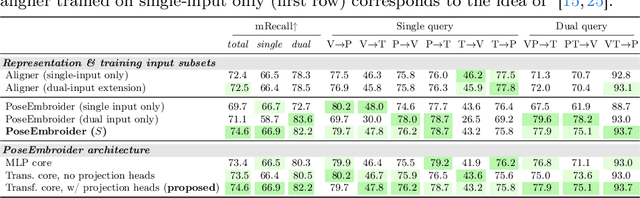
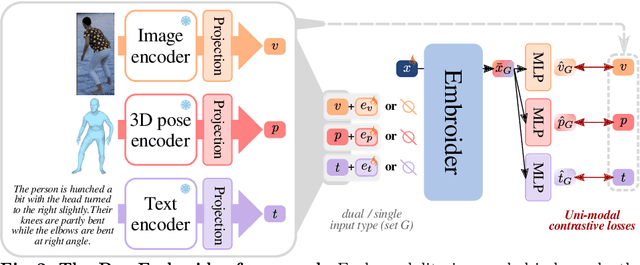
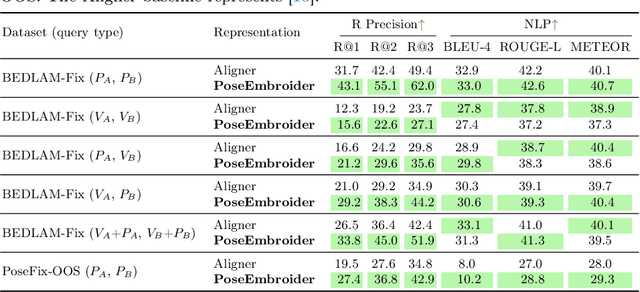
Aligning multiple modalities in a latent space, such as images and texts, has shown to produce powerful semantic visual representations, fueling tasks like image captioning, text-to-image generation, or image grounding. In the context of human-centric vision, albeit CLIP-like representations encode most standard human poses relatively well (such as standing or sitting), they lack sufficient acuteness to discern detailed or uncommon ones. Actually, while 3D human poses have been often associated with images (e.g. to perform pose estimation or pose-conditioned image generation), or more recently with text (e.g. for text-to-pose generation), they have seldom been paired with both. In this work, we combine 3D poses, person's pictures and textual pose descriptions to produce an enhanced 3D-, visual- and semantic-aware human pose representation. We introduce a new transformer-based model, trained in a retrieval fashion, which can take as input any combination of the aforementioned modalities. When composing modalities, it outperforms a standard multi-modal alignment retrieval model, making it possible to sort out partial information (e.g. image with the lower body occluded). We showcase the potential of such an embroidered pose representation for (1) SMPL regression from image with optional text cue; and (2) on the task of fine-grained instruction generation, which consists in generating a text that describes how to move from one 3D pose to another (as a fitness coach). Unlike prior works, our model can take any kind of input (image and/or pose) without retraining.
FootBots: A Transformer-based Architecture for Motion Prediction in Soccer
Jun 28, 2024Motion prediction in soccer involves capturing complex dynamics from player and ball interactions. We present FootBots, an encoder-decoder transformer-based architecture addressing motion prediction and conditioned motion prediction through equivariance properties. FootBots captures temporal and social dynamics using set attention blocks and multi-attention block decoder. Our evaluation utilizes two datasets: a real soccer dataset and a tailored synthetic one. Insights from the synthetic dataset highlight the effectiveness of FootBots' social attention mechanism and the significance of conditioned motion prediction. Empirical results on real soccer data demonstrate that FootBots outperforms baselines in motion prediction and excels in conditioned tasks, such as predicting the players based on the ball position, predicting the offensive (defensive) team based on the ball and the defensive (offensive) team, and predicting the ball position based on all players. Our evaluation connects quantitative and qualitative findings. https://youtu.be/9kaEkfzG3L8
IReNe: Instant Recoloring of Neural Radiance Fields
Jun 10, 2024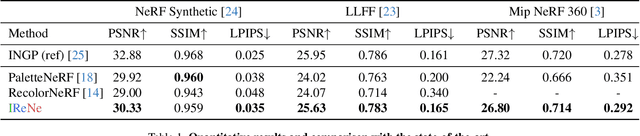
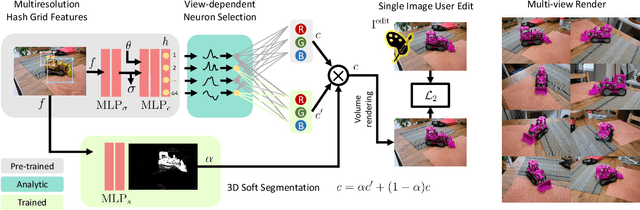
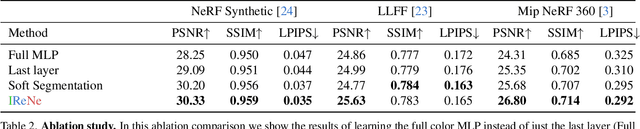

Advances in NERFs have allowed for 3D scene reconstructions and novel view synthesis. Yet, efficiently editing these representations while retaining photorealism is an emerging challenge. Recent methods face three primary limitations: they're slow for interactive use, lack precision at object boundaries, and struggle to ensure multi-view consistency. We introduce IReNe to address these limitations, enabling swift, near real-time color editing in NeRF. Leveraging a pre-trained NeRF model and a single training image with user-applied color edits, IReNe swiftly adjusts network parameters in seconds. This adjustment allows the model to generate new scene views, accurately representing the color changes from the training image while also controlling object boundaries and view-specific effects. Object boundary control is achieved by integrating a trainable segmentation module into the model. The process gains efficiency by retraining only the weights of the last network layer. We observed that neurons in this layer can be classified into those responsible for view-dependent appearance and those contributing to diffuse appearance. We introduce an automated classification approach to identify these neuron types and exclusively fine-tune the weights of the diffuse neurons. This further accelerates training and ensures consistent color edits across different views. A thorough validation on a new dataset, with edited object colors, shows significant quantitative and qualitative advancements over competitors, accelerating speeds by 5x to 500x.
IReNe: Instant Recoloring in Neural Radiance Fields
May 30, 2024Advances in NERFs have allowed for 3D scene reconstructions and novel view synthesis. Yet, efficiently editing these representations while retaining photorealism is an emerging challenge. Recent methods face three primary limitations: they're slow for interactive use, lack precision at object boundaries, and struggle to ensure multi-view consistency. We introduce IReNe to address these limitations, enabling swift, near real-time color editing in NeRF. Leveraging a pre-trained NeRF model and a single training image with user-applied color edits, IReNe swiftly adjusts network parameters in seconds. This adjustment allows the model to generate new scene views, accurately representing the color changes from the training image while also controlling object boundaries and view-specific effects. Object boundary control is achieved by integrating a trainable segmentation module into the model. The process gains efficiency by retraining only the weights of the last network layer. We observed that neurons in this layer can be classified into those responsible for view-dependent appearance and those contributing to diffuse appearance. We introduce an automated classification approach to identify these neuron types and exclusively fine-tune the weights of the diffuse neurons. This further accelerates training and ensures consistent color edits across different views. A thorough validation on a new dataset, with edited object colors, shows significant quantitative and qualitative advancements over competitors, accelerating speeds by 5x to 500x.
MEGA: Masked Generative Autoencoder for Human Mesh Recovery
May 29, 2024Human Mesh Recovery (HMR) from a single RGB image is a highly ambiguous problem, as similar 2D projections can correspond to multiple 3D interpretations. Nevertheless, most HMR methods overlook this ambiguity and make a single prediction without accounting for the associated uncertainty. A few approaches generate a distribution of human meshes, enabling the sampling of multiple predictions; however, none of them is competitive with the latest single-output model when making a single prediction. This work proposes a new approach based on masked generative modeling. By tokenizing the human pose and shape, we formulate the HMR task as generating a sequence of discrete tokens conditioned on an input image. We introduce MEGA, a MaskEd Generative Autoencoder trained to recover human meshes from images and partial human mesh token sequences. Given an image, our flexible generation scheme allows us to predict a single human mesh in deterministic mode or to generate multiple human meshes in stochastic mode. MEGA enables us to propose multiple outputs and to evaluate the uncertainty of the predictions. Experiments on in-the-wild benchmarks show that MEGA achieves state-of-the-art performance in deterministic and stochastic modes, outperforming single-output and multi-output approaches.
Purposer: Putting Human Motion Generation in Context
Apr 19, 2024We present a novel method to generate human motion to populate 3D indoor scenes. It can be controlled with various combinations of conditioning signals such as a path in a scene, target poses, past motions, and scenes represented as 3D point clouds. State-of-the-art methods are either models specialized to one single setting, require vast amounts of high-quality and diverse training data, or are unconditional models that do not integrate scene or other contextual information. As a consequence, they have limited applicability and rely on costly training data. To address these limitations, we propose a new method ,dubbed Purposer, based on neural discrete representation learning. Our model is capable of exploiting, in a flexible manner, different types of information already present in open access large-scale datasets such as AMASS. First, we encode unconditional human motion into a discrete latent space. Second, an autoregressive generative model, conditioned with key contextual information, either with prompting or additive tokens, and trained for next-step prediction in this space, synthesizes sequences of latent indices. We further design a novel conditioning block to handle future conditioning information in such a causal model by using a network with two branches to compute separate stacks of features. In this manner, Purposer can generate realistic motion sequences in diverse test scenes. Through exhaustive evaluation, we demonstrate that our multi-contextual solution outperforms existing specialized approaches for specific contextual information, both in terms of quality and diversity. Our model is trained with short sequences, but a byproduct of being able to use various conditioning signals is that at test time different combinations can be used to chain short sequences together and generate long motions within a context scene.