 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMASHRIMP: Automatic White Shrimp (Penaeus vannamei) Biometrical Analysis from Laboratory Images Using Computer Vision and Deep Learning
Jul 03, 2025This paper introduces IMASHRIMP, an adapted system for the automated morphological analysis of white shrimp (Penaeus vannamei}, aimed at optimizing genetic selection tasks in aquaculture. Existing deep learning and computer vision techniques were modified to address the specific challenges of shrimp morphology analysis from RGBD images. IMASHRIMP incorporates two discrimination modules, based on a modified ResNet-50 architecture, to classify images by the point of view and determine rostrum integrity. It is proposed a "two-factor authentication (human and IA)" system, it reduces human error in view classification from 0.97% to 0% and in rostrum detection from 12.46% to 3.64%. Additionally, a pose estimation module was adapted from VitPose to predict 23 key points on the shrimp's skeleton, with separate networks for lateral and dorsal views. A morphological regression module, using a Support Vector Machine (SVM) model, was integrated to convert pixel measurements to centimeter units. Experimental results show that the system effectively reduces human error, achieving a mean average precision (mAP) of 97.94% for pose estimation and a pixel-to-centimeter conversion error of 0.07 (+/- 0.1) cm. IMASHRIMP demonstrates the potential to automate and accelerate shrimp morphological analysis, enhancing the efficiency of genetic selection and contributing to more sustainable aquaculture practices.The code are available at https://github.com/AbiamRemacheGonzalez/ImaShrimp-public
IReNe: Instant Recoloring of Neural Radiance Fields
Jun 10, 2024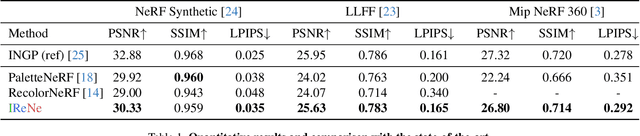
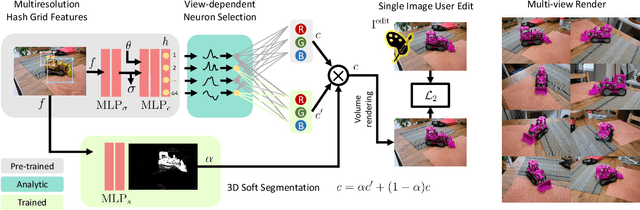
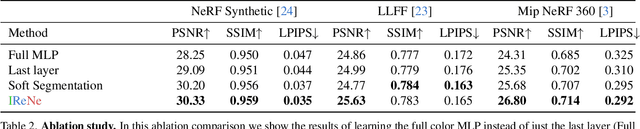

Advances in NERFs have allowed for 3D scene reconstructions and novel view synthesis. Yet, efficiently editing these representations while retaining photorealism is an emerging challenge. Recent methods face three primary limitations: they're slow for interactive use, lack precision at object boundaries, and struggle to ensure multi-view consistency. We introduce IReNe to address these limitations, enabling swift, near real-time color editing in NeRF. Leveraging a pre-trained NeRF model and a single training image with user-applied color edits, IReNe swiftly adjusts network parameters in seconds. This adjustment allows the model to generate new scene views, accurately representing the color changes from the training image while also controlling object boundaries and view-specific effects. Object boundary control is achieved by integrating a trainable segmentation module into the model. The process gains efficiency by retraining only the weights of the last network layer. We observed that neurons in this layer can be classified into those responsible for view-dependent appearance and those contributing to diffuse appearance. We introduce an automated classification approach to identify these neuron types and exclusively fine-tune the weights of the diffuse neurons. This further accelerates training and ensures consistent color edits across different views. A thorough validation on a new dataset, with edited object colors, shows significant quantitative and qualitative advancements over competitors, accelerating speeds by 5x to 500x.
IReNe: Instant Recoloring in Neural Radiance Fields
May 30, 2024Advances in NERFs have allowed for 3D scene reconstructions and novel view synthesis. Yet, efficiently editing these representations while retaining photorealism is an emerging challenge. Recent methods face three primary limitations: they're slow for interactive use, lack precision at object boundaries, and struggle to ensure multi-view consistency. We introduce IReNe to address these limitations, enabling swift, near real-time color editing in NeRF. Leveraging a pre-trained NeRF model and a single training image with user-applied color edits, IReNe swiftly adjusts network parameters in seconds. This adjustment allows the model to generate new scene views, accurately representing the color changes from the training image while also controlling object boundaries and view-specific effects. Object boundary control is achieved by integrating a trainable segmentation module into the model. The process gains efficiency by retraining only the weights of the last network layer. We observed that neurons in this layer can be classified into those responsible for view-dependent appearance and those contributing to diffuse appearance. We introduce an automated classification approach to identify these neuron types and exclusively fine-tune the weights of the diffuse neurons. This further accelerates training and ensures consistent color edits across different views. A thorough validation on a new dataset, with edited object colors, shows significant quantitative and qualitative advancements over competitors, accelerating speeds by 5x to 500x.
Real-time LIDAR localization in natural and urban environments
Jan 31, 2023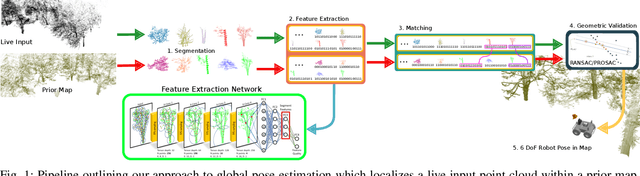
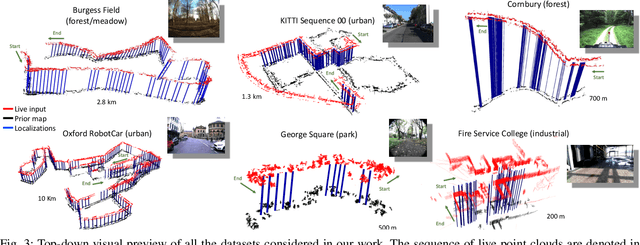

Localization is a key challenge in many robotics applications. In this work we explore LIDAR-based global localization in both urban and natural environments and develop a method suitable for online application. Our approach leverages efficient deep learning architecture capable of learning compact point cloud descriptors directly from 3D data. The method uses an efficient feature space representation of a set of segmented point clouds to match between the current scene and the prior map. We show that down-sampling in the inner layers of the network can significantly reduce computation time without sacrificing performance. We present substantial evaluation of LIDAR-based global localization methods on nine scenarios from six datasets varying between urban, park, forest, and industrial environments. Part of which includes post-processed data from 30 sequences of the Oxford RobotCar dataset, which we make publicly available. Our experiments demonstrate a factor of three reduction of computation, 70% lower memory consumption with marginal loss in localization frequency. The proposed method allows the full pipeline to run on robots with limited computation payload such as drones, quadrupeds, and UGVs as it does not require a GPU at run time.
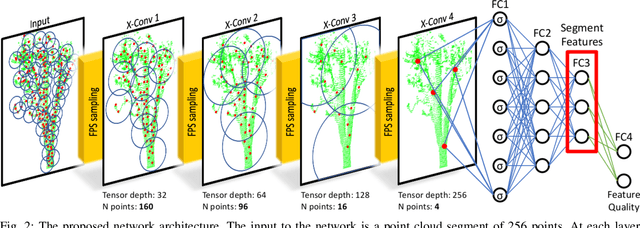
SKD: Unsupervised Keypoint Detecting for Point Clouds using Embedded Saliency Estimation
Dec 10, 2019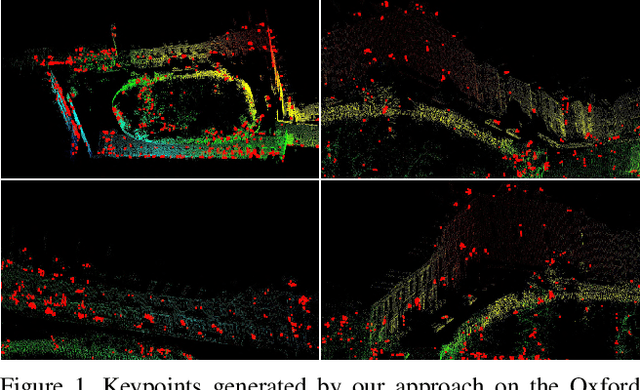
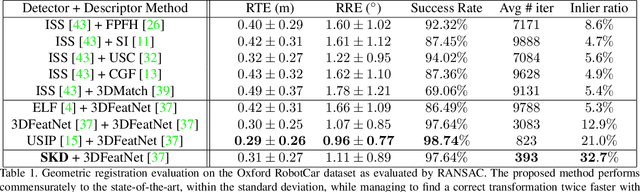
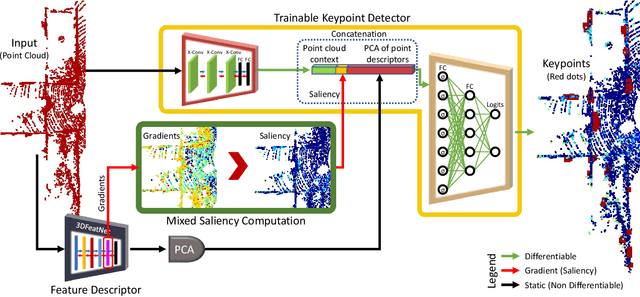

In this work we present a novel keypoint detector that uses saliency to determine the best candidates from point clouds. The approach can be applied to any differentiable deep learning descriptor by using the gradients of that descriptor with respect to the input to estimate an initial set of candidate keypoints. By using a neural network over the set of candidates we further learn to refine the point selection until the actual keypoints are obtained. The key intuition behind this approach is that keypoints need to be determined based on how the descriptor behaves and not just on the geometry that surrounds a point. To improve the performance of the learned keypoint descriptor we combine the saliency, the feature signal and geometric information from the point cloud to allow the network to select good keypoint candidates. The approach was evaluated on the two largest LIDAR datasets - the Oxford RobotCar dataset and the KITTI dataset, where we obtain up to 50% improvement over the state-of-the-art in both matchability score and repeatability.
Learning to See the Wood for the Trees: Deep Laser Localization in Urban and Natural Environments on a CPU
Feb 26, 2019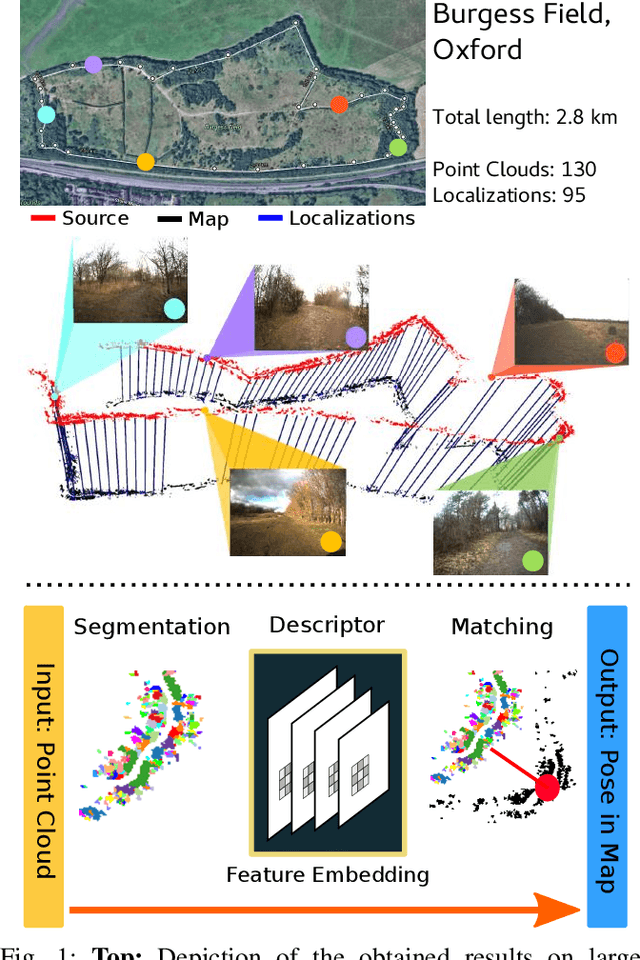
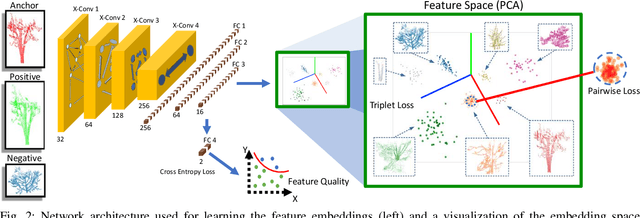
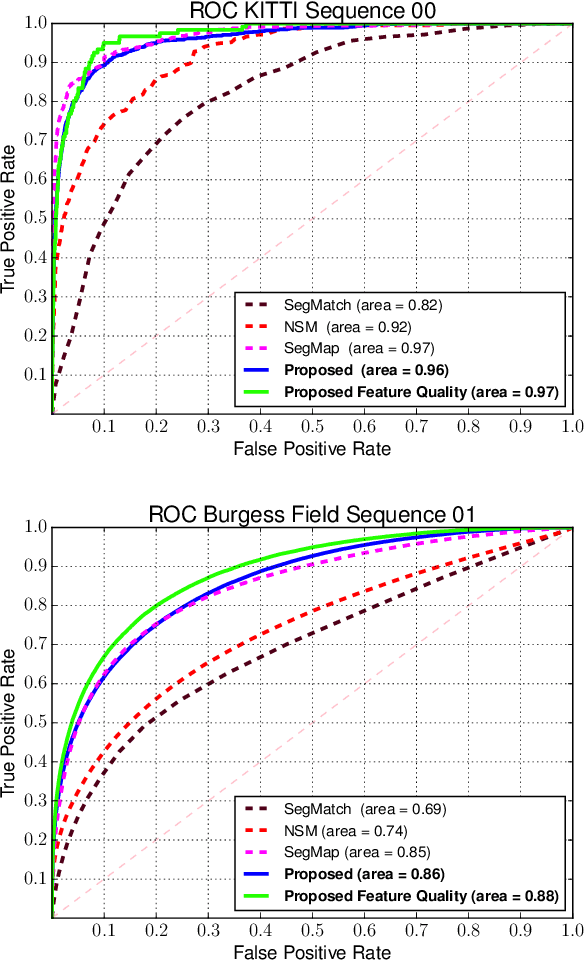
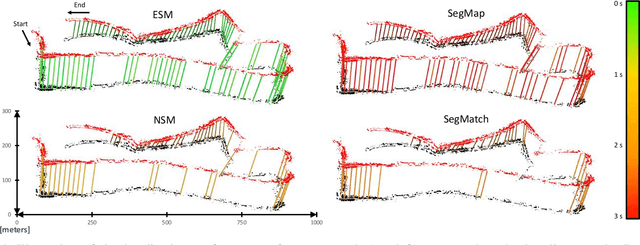
Localization in challenging, natural environments such as forests or woodlands is an important capability for many applications from guiding a robot navigating along a forest trail to monitoring vegetation growth with handheld sensors. In this work we explore laser-based localization in both urban and natural environments, which is suitable for online applications. We propose a deep learning approach capable of learning meaningful descriptors directly from 3D point clouds by comparing triplets (anchor, positive and negative examples). The approach learns a feature space representation for a set of segmented point clouds that are matched between a current and previous observations. Our learning method is tailored towards loop closure detection resulting in a small model which can be deployed using only a CPU. The proposed learning method would allow the full pipeline to run on robots with limited computational payload such as drones, quadrupeds or UGVs.
3D Pick & Mix: Object Part Blending in Joint Shape and Image Manifolds
Nov 02, 2018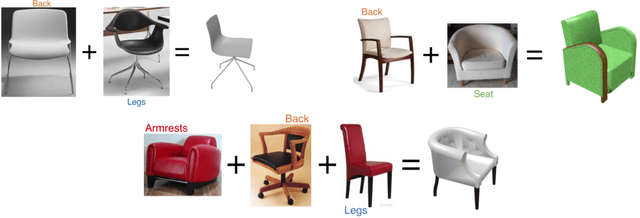
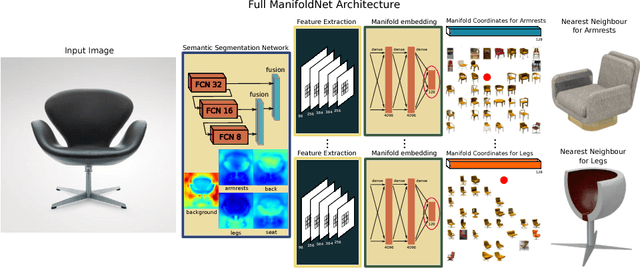

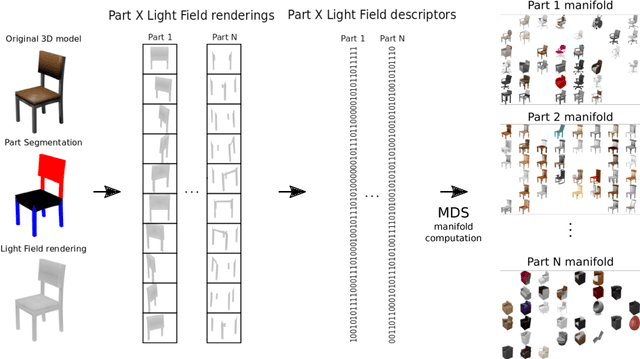
We present 3D Pick & Mix, a new 3D shape retrieval system that provides users with a new level of freedom to explore 3D shape and Internet image collections by introducing the ability to reason about objects at the level of their constituent parts. While classic retrieval systems can only formulate simple searches such as "find the 3D model that is most similar to the input image" our new approach can formulate advanced and semantically meaningful search queries such as: "find me the 3D model that best combines the design of the legs of the chair in image 1 but with no armrests, like the chair in image 2". Many applications could benefit from such rich queries, users could browse through catalogues of furniture and pick and mix parts, combining for example the legs of a chair from one shop and the armrests from another shop.