 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeΦeat: Physically-Grounded Feature Representation
Nov 14, 2025Foundation models have emerged as effective backbones for many vision tasks. However, current self-supervised features entangle high-level semantics with low-level physical factors, such as geometry and illumination, hindering their use in tasks requiring explicit physical reasoning. In this paper, we introduce $Φ$eat, a novel physically-grounded visual backbone that encourages a representation sensitive to material identity, including reflectance cues and geometric mesostructure. Our key idea is to employ a pretraining strategy that contrasts spatial crops and physical augmentations of the same material under varying shapes and lighting conditions. While similar data have been used in high-end supervised tasks such as intrinsic decomposition or material estimation, we demonstrate that a pure self-supervised training strategy, without explicit labels, already provides a strong prior for tasks requiring robust features invariant to external physical factors. We evaluate the learned representations through feature similarity analysis and material selection, showing that $Φ$eat captures physically-grounded structure beyond semantic grouping. These findings highlight the promise of unsupervised physical feature learning as a foundation for physics-aware perception in vision and graphics. These findings highlight the promise of unsupervised physical feature learning as a foundation for physics-aware perception in vision and graphics.
Fine-Grained Spatially Varying Material Selection in Images
Jun 11, 2025
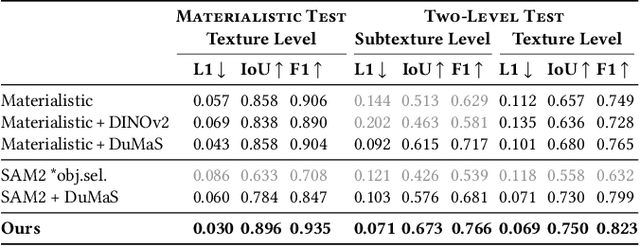

Selection is the first step in many image editing processes, enabling faster and simpler modifications of all pixels sharing a common modality. In this work, we present a method for material selection in images, robust to lighting and reflectance variations, which can be used for downstream editing tasks. We rely on vision transformer (ViT) models and leverage their features for selection, proposing a multi-resolution processing strategy that yields finer and more stable selection results than prior methods. Furthermore, we enable selection at two levels: texture and subtexture, leveraging a new two-level material selection (DuMaS) dataset which includes dense annotations for over 800,000 synthetic images, both on the texture and subtexture levels.
Single-image Reflectance and Transmittance Estimation from Any Flatbed Scanner
Feb 20, 2025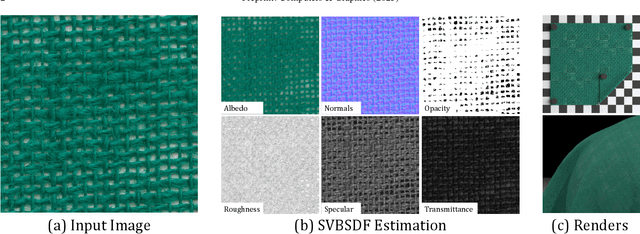

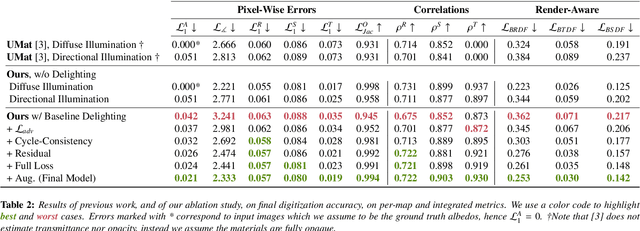
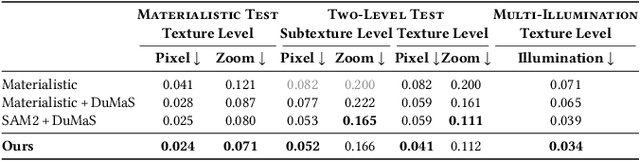
Flatbed scanners have emerged as promising devices for high-resolution, single-image material capture. However, existing approaches assume very specific conditions, such as uniform diffuse illumination, which are only available in certain high-end devices, hindering their scalability and cost. In contrast, in this work, we introduce a method inspired by intrinsic image decomposition, which accurately removes both shading and specularity, effectively allowing captures with any flatbed scanner. Further, we extend previous work on single-image material reflectance capture with the estimation of opacity and transmittance, critical components of full material appearance (SVBSDF), improving the results for any material captured with a flatbed scanner, at a very high resolution and accuracy
IReNe: Instant Recoloring of Neural Radiance Fields
Jun 10, 2024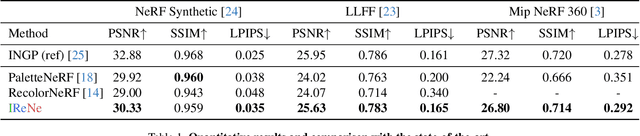
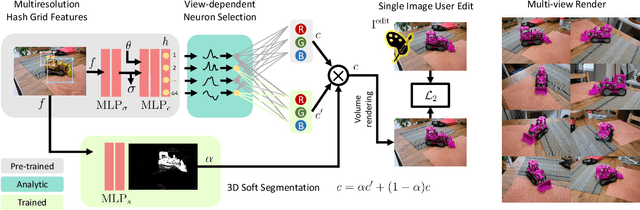
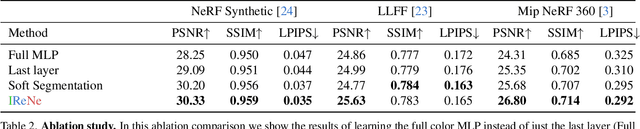

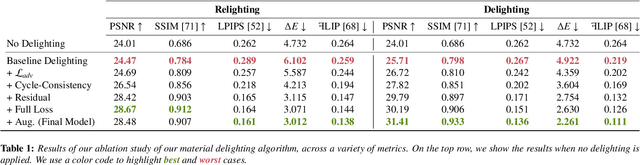
Advances in NERFs have allowed for 3D scene reconstructions and novel view synthesis. Yet, efficiently editing these representations while retaining photorealism is an emerging challenge. Recent methods face three primary limitations: they're slow for interactive use, lack precision at object boundaries, and struggle to ensure multi-view consistency. We introduce IReNe to address these limitations, enabling swift, near real-time color editing in NeRF. Leveraging a pre-trained NeRF model and a single training image with user-applied color edits, IReNe swiftly adjusts network parameters in seconds. This adjustment allows the model to generate new scene views, accurately representing the color changes from the training image while also controlling object boundaries and view-specific effects. Object boundary control is achieved by integrating a trainable segmentation module into the model. The process gains efficiency by retraining only the weights of the last network layer. We observed that neurons in this layer can be classified into those responsible for view-dependent appearance and those contributing to diffuse appearance. We introduce an automated classification approach to identify these neuron types and exclusively fine-tune the weights of the diffuse neurons. This further accelerates training and ensures consistent color edits across different views. A thorough validation on a new dataset, with edited object colors, shows significant quantitative and qualitative advancements over competitors, accelerating speeds by 5x to 500x.
IReNe: Instant Recoloring in Neural Radiance Fields
May 30, 2024Advances in NERFs have allowed for 3D scene reconstructions and novel view synthesis. Yet, efficiently editing these representations while retaining photorealism is an emerging challenge. Recent methods face three primary limitations: they're slow for interactive use, lack precision at object boundaries, and struggle to ensure multi-view consistency. We introduce IReNe to address these limitations, enabling swift, near real-time color editing in NeRF. Leveraging a pre-trained NeRF model and a single training image with user-applied color edits, IReNe swiftly adjusts network parameters in seconds. This adjustment allows the model to generate new scene views, accurately representing the color changes from the training image while also controlling object boundaries and view-specific effects. Object boundary control is achieved by integrating a trainable segmentation module into the model. The process gains efficiency by retraining only the weights of the last network layer. We observed that neurons in this layer can be classified into those responsible for view-dependent appearance and those contributing to diffuse appearance. We introduce an automated classification approach to identify these neuron types and exclusively fine-tune the weights of the diffuse neurons. This further accelerates training and ensures consistent color edits across different views. A thorough validation on a new dataset, with edited object colors, shows significant quantitative and qualitative advancements over competitors, accelerating speeds by 5x to 500x.
TexTile: A Differentiable Metric for Texture Tileability
Mar 19, 2024
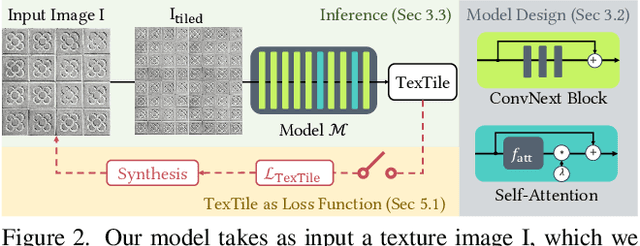
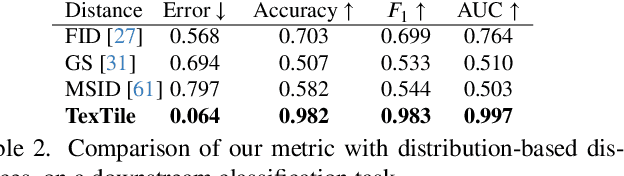

We introduce TexTile, a novel differentiable metric to quantify the degree upon which a texture image can be concatenated with itself without introducing repeating artifacts (i.e., the tileability). Existing methods for tileable texture synthesis focus on general texture quality, but lack explicit analysis of the intrinsic repeatability properties of a texture. In contrast, our TexTile metric effectively evaluates the tileable properties of a texture, opening the door to more informed synthesis and analysis of tileable textures. Under the hood, TexTile is formulated as a binary classifier carefully built from a large dataset of textures of different styles, semantics, regularities, and human annotations.Key to our method is a set of architectural modifications to baseline pre-train image classifiers to overcome their shortcomings at measuring tileability, along with a custom data augmentation and training regime aimed at increasing robustness and accuracy. We demonstrate that TexTile can be plugged into different state-of-the-art texture synthesis methods, including diffusion-based strategies, and generate tileable textures while keeping or even improving the overall texture quality. Furthermore, we show that TexTile can objectively evaluate any tileable texture synthesis method, whereas the current mix of existing metrics produces uncorrelated scores which heavily hinders progress in the field.
NeuBTF: Neural fields for BTF encoding and transfer
Jul 03, 2023



Neural material representations are becoming a popular way to represent materials for rendering. They are more expressive than analytic models and occupy less memory than tabulated BTFs. However, existing neural materials are immutable, meaning that their output for a certain query of UVs, camera, and light vector is fixed once they are trained. While this is practical when there is no need to edit the material, it can become very limiting when the fragment of the material used for training is too small or not tileable, which frequently happens when the material has been captured with a gonioreflectometer. In this paper, we propose a novel neural material representation which jointly tackles the problems of BTF compression, tiling, and extrapolation. At test time, our method uses a guidance image as input to condition the neural BTF to the structural features of this input image. Then, the neural BTF can be queried as a regular BTF using UVs, camera, and light vectors. Every component in our framework is purposefully designed to maximize BTF encoding quality at minimal parameter count and computational complexity, achieving competitive compression rates compared with previous work. We demonstrate the results of our method on a variety of synthetic and captured materials, showing its generality and capacity to learn to represent many optical properties.
* 9 pages, 7 figures. Accepted to Computers & Graphics (Special Section on CEIG 2023). Project Website: https://carlosrodriguezpardo.es/projects/NeuBTF/
UMat: Uncertainty-Aware Single Image High Resolution Material Capture
May 25, 2023



We propose a learning-based method to recover normals, specularity, and roughness from a single diffuse image of a material, using microgeometry appearance as our primary cue. Previous methods that work on single images tend to produce over-smooth outputs with artifacts, operate at limited resolution, or train one model per class with little room for generalization. Previous methods that work on single images tend to produce over-smooth outputs with artifacts, operate at limited resolution, or train one model per class with little room for generalization. In contrast, in this work, we propose a novel capture approach that leverages a generative network with attention and a U-Net discriminator, which shows outstanding performance integrating global information at reduced computational complexity. We showcase the performance of our method with a real dataset of digitized textile materials and show that a commodity flatbed scanner can produce the type of diffuse illumination required as input to our method. Additionally, because the problem might be illposed -more than a single diffuse image might be needed to disambiguate the specular reflection- or because the training dataset is not representative enough of the real distribution, we propose a novel framework to quantify the model's confidence about its prediction at test time. Our method is the first one to deal with the problem of modeling uncertainty in material digitization, increasing the trustworthiness of the process and enabling more intelligent strategies for dataset creation, as we demonstrate with an active learning experiment.
How Will It Drape Like? Capturing Fabric Mechanics from Depth Images
Apr 13, 2023We propose a method to estimate the mechanical parameters of fabrics using a casual capture setup with a depth camera. Our approach enables to create mechanically-correct digital representations of real-world textile materials, which is a fundamental step for many interactive design and engineering applications. As opposed to existing capture methods, which typically require expensive setups, video sequences, or manual intervention, our solution can capture at scale, is agnostic to the optical appearance of the textile, and facilitates fabric arrangement by non-expert operators. To this end, we propose a sim-to-real strategy to train a learning-based framework that can take as input one or multiple images and outputs a full set of mechanical parameters. Thanks to carefully designed data augmentation and transfer learning protocols, our solution generalizes to real images despite being trained only on synthetic data, hence successfully closing the sim-to-real loop.Key in our work is to demonstrate that evaluating the regression accuracy based on the similarity at parameter space leads to an inaccurate distances that do not match the human perception. To overcome this, we propose a novel metric for fabric drape similarity that operates on the image domain instead on the parameter space, allowing us to evaluate our estimation within the context of a similarity rank. We show that out metric correlates with human judgments about the perception of drape similarity, and that our model predictions produce perceptually accurate results compared to the ground truth parameters.
SeamlessGAN: Self-Supervised Synthesis of Tileable Texture Maps
Jan 13, 2022

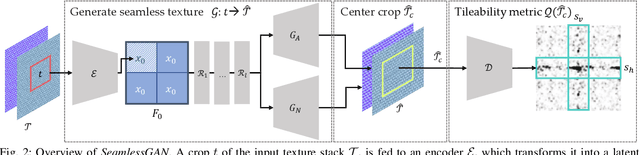
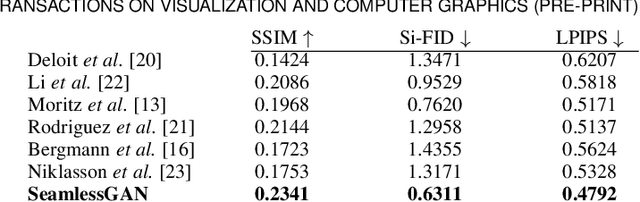
We present SeamlessGAN, a method capable of automatically generating tileable texture maps from a single input exemplar. In contrast to most existing methods, focused solely on solving the synthesis problem, our work tackles both problems, synthesis and tileability, simultaneously. Our key idea is to realize that tiling a latent space within a generative network trained using adversarial expansion techniques produces outputs with continuity at the seam intersection that can be then be turned into tileable images by cropping the central area. Since not every value of the latent space is valid to produce high-quality outputs, we leverage the discriminator as a perceptual error metric capable of identifying artifact-free textures during a sampling process. Further, in contrast to previous work on deep texture synthesis, our model is designed and optimized to work with multi-layered texture representations, enabling textures composed of multiple maps such as albedo, normals, etc. We extensively test our design choices for the network architecture, loss function and sampling parameters. We show qualitatively and quantitatively that our approach outperforms previous methods and works for textures of different types.