 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Long-Term Electricity Market Design for Ambitious Decarbonization Targets using Multi-Agent Reinforcement Learning
Dec 19, 2025



Electricity systems are key to transforming today's society into a carbon-free economy. Long-term electricity market mechanisms, including auctions, support schemes, and other policy instruments, are critical in shaping the electricity generation mix. In light of the need for more advanced tools to support policymakers and other stakeholders in designing, testing, and evaluating long-term markets, this work presents a multi-agent reinforcement learning model capable of capturing the key features of decarbonizing energy systems. Profit-maximizing generation companies make investment decisions in the wholesale electricity market, responding to system needs, competitive dynamics, and policy signals. The model employs independent proximal policy optimization, which was selected for suitability to the decentralized and competitive environment. Nevertheless, given the inherent challenges of independent learning in multi-agent settings, an extensive hyperparameter search ensures that decentralized training yields market outcomes consistent with competitive behavior. The model is applied to a stylized version of the Italian electricity system and tested under varying levels of competition, market designs, and policy scenarios. Results highlight the critical role of market design for decarbonizing the electricity sector and avoiding price volatility. The proposed framework allows assessing long-term electricity markets in which multiple policy and market mechanisms interact simultaneously, with market participants responding and adapting to decarbonization pathways.
Neural Conditional Transport Maps
May 21, 2025We present a neural framework for learning conditional optimal transport (OT) maps between probability distributions. Our approach introduces a conditioning mechanism capable of processing both categorical and continuous conditioning variables simultaneously. At the core of our method lies a hypernetwork that generates transport layer parameters based on these inputs, creating adaptive mappings that outperform simpler conditioning methods. Comprehensive ablation studies demonstrate the superior performance of our method over baseline configurations. Furthermore, we showcase an application to global sensitivity analysis, offering high performance in computing OT-based sensitivity indices. This work advances the state-of-the-art in conditional optimal transport, enabling broader application of optimal transport principles to complex, high-dimensional domains such as generative modeling and black-box model explainability.
Net-Zero: A Comparative Study on Neural Network Design for Climate-Economic PDEs Under Uncertainty
May 19, 2025Climate-economic modeling under uncertainty presents significant computational challenges that may limit policymakers' ability to address climate change effectively. This paper explores neural network-based approaches for solving high-dimensional optimal control problems arising from models that incorporate ambiguity aversion in climate mitigation decisions. We develop a continuous-time endogenous-growth economic model that accounts for multiple mitigation pathways, including emission-free capital and carbon intensity reductions. Given the inherent complexity and high dimensionality of these models, traditional numerical methods become computationally intractable. We benchmark several neural network architectures against finite-difference generated solutions, evaluating their ability to capture the dynamic interactions between uncertainty, technology transitions, and optimal climate policy. Our findings demonstrate that appropriate neural architecture selection significantly impacts both solution accuracy and computational efficiency when modeling climate-economic systems under uncertainty. These methodological advances enable more sophisticated modeling of climate policy decisions, allowing for better representation of technology transitions and uncertainty-critical elements for developing effective mitigation strategies in the face of climate change.
Single-image Reflectance and Transmittance Estimation from Any Flatbed Scanner
Feb 20, 2025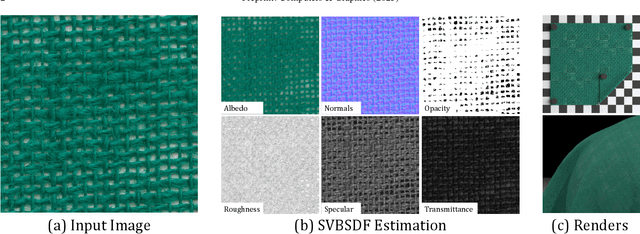
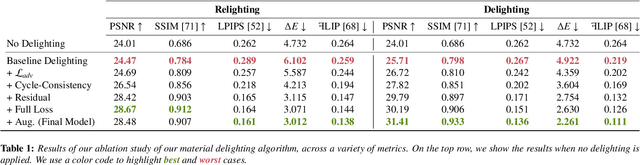

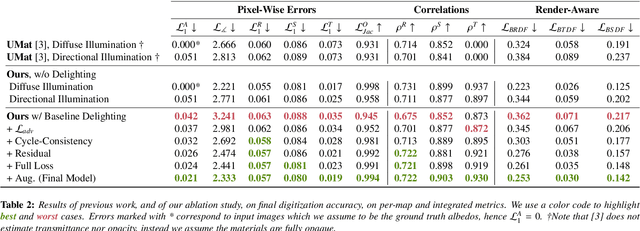
Flatbed scanners have emerged as promising devices for high-resolution, single-image material capture. However, existing approaches assume very specific conditions, such as uniform diffuse illumination, which are only available in certain high-end devices, hindering their scalability and cost. In contrast, in this work, we introduce a method inspired by intrinsic image decomposition, which accurately removes both shading and specularity, effectively allowing captures with any flatbed scanner. Further, we extend previous work on single-image material reflectance capture with the estimation of opacity and transmittance, critical components of full material appearance (SVBSDF), improving the results for any material captured with a flatbed scanner, at a very high resolution and accuracy
TexTile: A Differentiable Metric for Texture Tileability
Mar 19, 2024
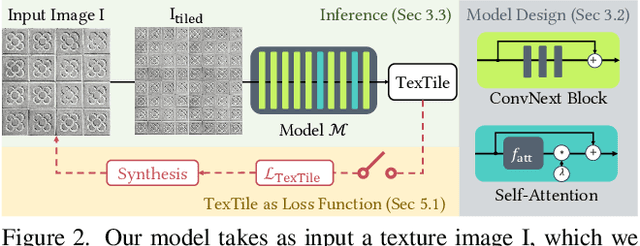
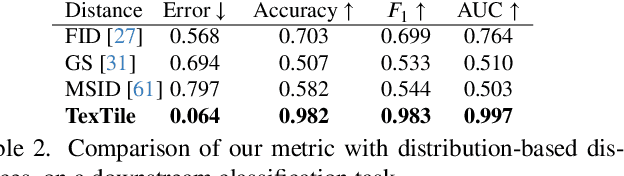

We introduce TexTile, a novel differentiable metric to quantify the degree upon which a texture image can be concatenated with itself without introducing repeating artifacts (i.e., the tileability). Existing methods for tileable texture synthesis focus on general texture quality, but lack explicit analysis of the intrinsic repeatability properties of a texture. In contrast, our TexTile metric effectively evaluates the tileable properties of a texture, opening the door to more informed synthesis and analysis of tileable textures. Under the hood, TexTile is formulated as a binary classifier carefully built from a large dataset of textures of different styles, semantics, regularities, and human annotations.Key to our method is a set of architectural modifications to baseline pre-train image classifiers to overcome their shortcomings at measuring tileability, along with a custom data augmentation and training regime aimed at increasing robustness and accuracy. We demonstrate that TexTile can be plugged into different state-of-the-art texture synthesis methods, including diffusion-based strategies, and generate tileable textures while keeping or even improving the overall texture quality. Furthermore, we show that TexTile can objectively evaluate any tileable texture synthesis method, whereas the current mix of existing metrics produces uncorrelated scores which heavily hinders progress in the field.
NeuBTF: Neural fields for BTF encoding and transfer
Jul 03, 2023



Neural material representations are becoming a popular way to represent materials for rendering. They are more expressive than analytic models and occupy less memory than tabulated BTFs. However, existing neural materials are immutable, meaning that their output for a certain query of UVs, camera, and light vector is fixed once they are trained. While this is practical when there is no need to edit the material, it can become very limiting when the fragment of the material used for training is too small or not tileable, which frequently happens when the material has been captured with a gonioreflectometer. In this paper, we propose a novel neural material representation which jointly tackles the problems of BTF compression, tiling, and extrapolation. At test time, our method uses a guidance image as input to condition the neural BTF to the structural features of this input image. Then, the neural BTF can be queried as a regular BTF using UVs, camera, and light vectors. Every component in our framework is purposefully designed to maximize BTF encoding quality at minimal parameter count and computational complexity, achieving competitive compression rates compared with previous work. We demonstrate the results of our method on a variety of synthetic and captured materials, showing its generality and capacity to learn to represent many optical properties.
* 9 pages, 7 figures. Accepted to Computers & Graphics (Special Section on CEIG 2023). Project Website: https://carlosrodriguezpardo.es/projects/NeuBTF/
UMat: Uncertainty-Aware Single Image High Resolution Material Capture
May 25, 2023



We propose a learning-based method to recover normals, specularity, and roughness from a single diffuse image of a material, using microgeometry appearance as our primary cue. Previous methods that work on single images tend to produce over-smooth outputs with artifacts, operate at limited resolution, or train one model per class with little room for generalization. Previous methods that work on single images tend to produce over-smooth outputs with artifacts, operate at limited resolution, or train one model per class with little room for generalization. In contrast, in this work, we propose a novel capture approach that leverages a generative network with attention and a U-Net discriminator, which shows outstanding performance integrating global information at reduced computational complexity. We showcase the performance of our method with a real dataset of digitized textile materials and show that a commodity flatbed scanner can produce the type of diffuse illumination required as input to our method. Additionally, because the problem might be illposed -more than a single diffuse image might be needed to disambiguate the specular reflection- or because the training dataset is not representative enough of the real distribution, we propose a novel framework to quantify the model's confidence about its prediction at test time. Our method is the first one to deal with the problem of modeling uncertainty in material digitization, increasing the trustworthiness of the process and enabling more intelligent strategies for dataset creation, as we demonstrate with an active learning experiment.
How Will It Drape Like? Capturing Fabric Mechanics from Depth Images
Apr 13, 2023We propose a method to estimate the mechanical parameters of fabrics using a casual capture setup with a depth camera. Our approach enables to create mechanically-correct digital representations of real-world textile materials, which is a fundamental step for many interactive design and engineering applications. As opposed to existing capture methods, which typically require expensive setups, video sequences, or manual intervention, our solution can capture at scale, is agnostic to the optical appearance of the textile, and facilitates fabric arrangement by non-expert operators. To this end, we propose a sim-to-real strategy to train a learning-based framework that can take as input one or multiple images and outputs a full set of mechanical parameters. Thanks to carefully designed data augmentation and transfer learning protocols, our solution generalizes to real images despite being trained only on synthetic data, hence successfully closing the sim-to-real loop.Key in our work is to demonstrate that evaluating the regression accuracy based on the similarity at parameter space leads to an inaccurate distances that do not match the human perception. To overcome this, we propose a novel metric for fabric drape similarity that operates on the image domain instead on the parameter space, allowing us to evaluate our estimation within the context of a similarity rank. We show that out metric correlates with human judgments about the perception of drape similarity, and that our model predictions produce perceptually accurate results compared to the ground truth parameters.
SeamlessGAN: Self-Supervised Synthesis of Tileable Texture Maps
Jan 13, 2022

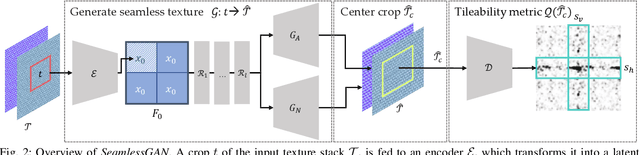
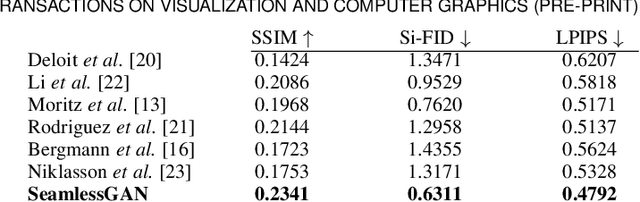
We present SeamlessGAN, a method capable of automatically generating tileable texture maps from a single input exemplar. In contrast to most existing methods, focused solely on solving the synthesis problem, our work tackles both problems, synthesis and tileability, simultaneously. Our key idea is to realize that tiling a latent space within a generative network trained using adversarial expansion techniques produces outputs with continuity at the seam intersection that can be then be turned into tileable images by cropping the central area. Since not every value of the latent space is valid to produce high-quality outputs, we leverage the discriminator as a perceptual error metric capable of identifying artifact-free textures during a sampling process. Further, in contrast to previous work on deep texture synthesis, our model is designed and optimized to work with multi-layered texture representations, enabling textures composed of multiple maps such as albedo, normals, etc. We extensively test our design choices for the network architecture, loss function and sampling parameters. We show qualitatively and quantitatively that our approach outperforms previous methods and works for textures of different types.
A Survey on Intrinsic Images: Delving Deep Into Lambert and Beyond
Dec 07, 2021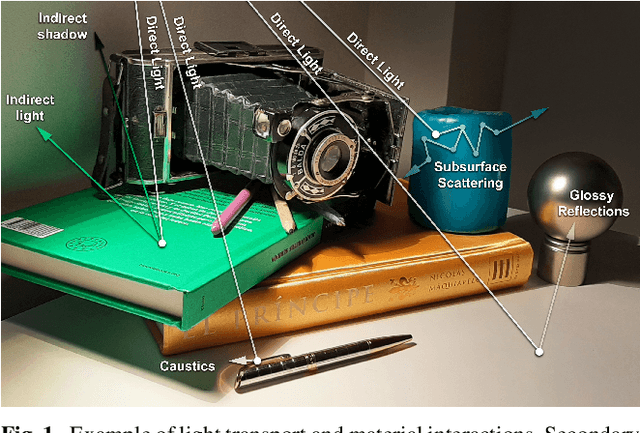
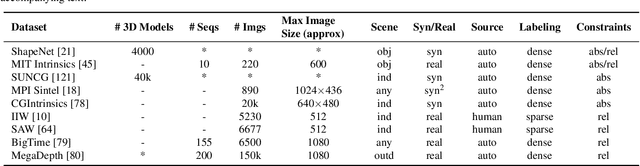
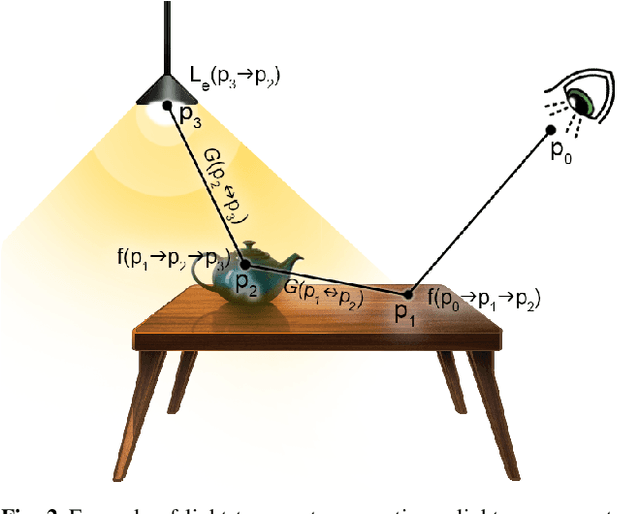
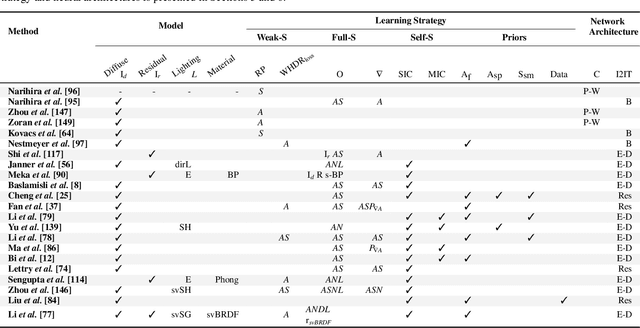
Intrinsic imaging or intrinsic image decomposition has traditionally been described as the problem of decomposing an image into two layers: a reflectance, the albedo invariant color of the material; and a shading, produced by the interaction between light and geometry. Deep learning techniques have been broadly applied in recent years to increase the accuracy of those separations. In this survey, we overview those results in context of well-known intrinsic image data sets and relevant metrics used in the literature, discussing their suitability to predict a desirable intrinsic image decomposition. Although the Lambertian assumption is still a foundational basis for many methods, we show that there is increasing awareness on the potential of more sophisticated physically-principled components of the image formation process, that is, optically accurate material models and geometry, and more complete inverse light transport estimations. We classify these methods in terms of the type of decomposition, considering the priors and models used, as well as the learning architecture and methodology driving the decomposition process. We also provide insights about future directions for research, given the recent advances in neural, inverse and differentiable rendering techniques.