 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-RGBX: Video Editing with Accurate Controls over Intrinsic Properties
Dec 12, 2025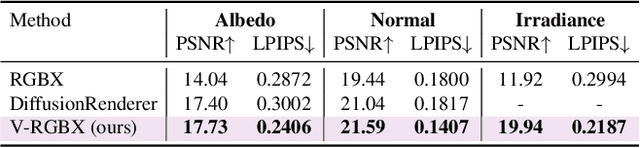
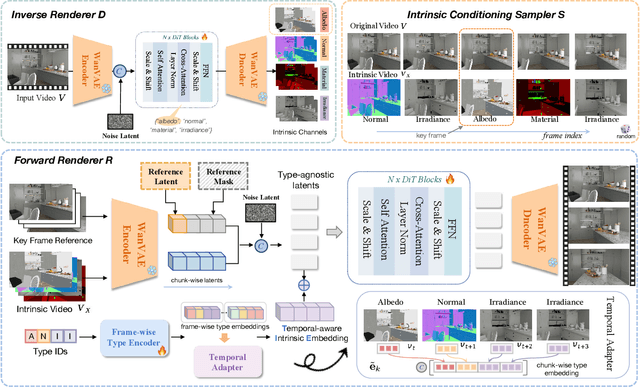
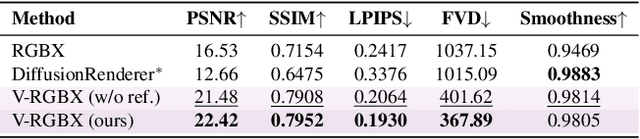

Large-scale video generation models have shown remarkable potential in modeling photorealistic appearance and lighting interactions in real-world scenes. However, a closed-loop framework that jointly understands intrinsic scene properties (e.g., albedo, normal, material, and irradiance), leverages them for video synthesis, and supports editable intrinsic representations remains unexplored. We present V-RGBX, the first end-to-end framework for intrinsic-aware video editing. V-RGBX unifies three key capabilities: (1) video inverse rendering into intrinsic channels, (2) photorealistic video synthesis from these intrinsic representations, and (3) keyframe-based video editing conditioned on intrinsic channels. At the core of V-RGBX is an interleaved conditioning mechanism that enables intuitive, physically grounded video editing through user-selected keyframes, supporting flexible manipulation of any intrinsic modality. Extensive qualitative and quantitative results show that V-RGBX produces temporally consistent, photorealistic videos while propagating keyframe edits across sequences in a physically plausible manner. We demonstrate its effectiveness in diverse applications, including object appearance editing and scene-level relighting, surpassing the performance of prior methods.
Fine-Grained Spatially Varying Material Selection in Images
Jun 11, 2025
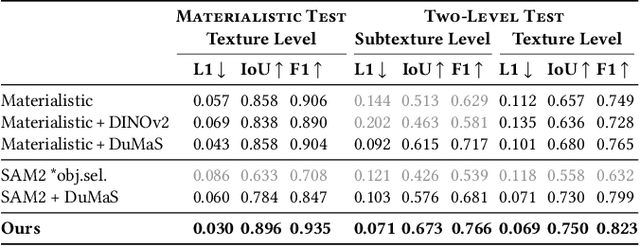

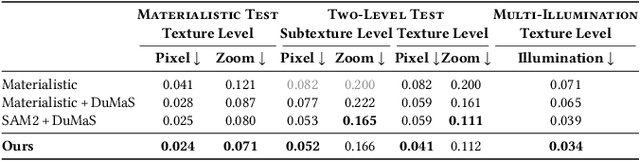
Selection is the first step in many image editing processes, enabling faster and simpler modifications of all pixels sharing a common modality. In this work, we present a method for material selection in images, robust to lighting and reflectance variations, which can be used for downstream editing tasks. We rely on vision transformer (ViT) models and leverage their features for selection, proposing a multi-resolution processing strategy that yields finer and more stable selection results than prior methods. Furthermore, we enable selection at two levels: texture and subtexture, leveraging a new two-level material selection (DuMaS) dataset which includes dense annotations for over 800,000 synthetic images, both on the texture and subtexture levels.
IntrinsicEdit: Precise generative image manipulation in intrinsic space
May 15, 2025



Generative diffusion models have advanced image editing with high-quality results and intuitive interfaces such as prompts and semantic drawing. However, these interfaces lack precise control, and the associated methods typically specialize on a single editing task. We introduce a versatile, generative workflow that operates in an intrinsic-image latent space, enabling semantic, local manipulation with pixel precision for a range of editing operations. Building atop the RGB-X diffusion framework, we address key challenges of identity preservation and intrinsic-channel entanglement. By incorporating exact diffusion inversion and disentangled channel manipulation, we enable precise, efficient editing with automatic resolution of global illumination effects -- all without additional data collection or model fine-tuning. We demonstrate state-of-the-art performance across a variety of tasks on complex images, including color and texture adjustments, object insertion and removal, global relighting, and their combinations.
Mean-Shift Distillation for Diffusion Mode Seeking
Feb 21, 2025We present mean-shift distillation, a novel diffusion distillation technique that provides a provably good proxy for the gradient of the diffusion output distribution. This is derived directly from mean-shift mode seeking on the distribution, and we show that its extrema are aligned with the modes. We further derive an efficient product distribution sampling procedure to evaluate the gradient. Our method is formulated as a drop-in replacement for score distillation sampling (SDS), requiring neither model retraining nor extensive modification of the sampling procedure. We show that it exhibits superior mode alignment as well as improved convergence in both synthetic and practical setups, yielding higher-fidelity results when applied to both text-to-image and text-to-3D applications with Stable Diffusion.
SAMa: Material-aware 3D Selection and Segmentation
Nov 28, 2024
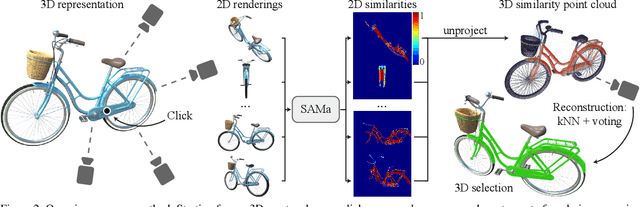
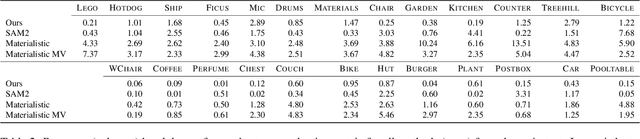
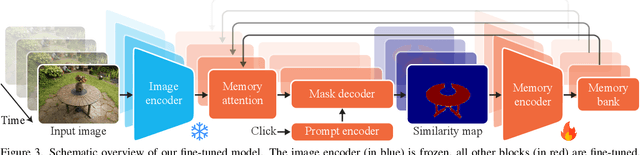
Decomposing 3D assets into material parts is a common task for artists and creators, yet remains a highly manual process. In this work, we introduce Select Any Material (SAMa), a material selection approach for various 3D representations. Building on the recently introduced SAM2 video selection model, we extend its capabilities to the material domain. We leverage the model's cross-view consistency to create a 3D-consistent intermediate material-similarity representation in the form of a point cloud from a sparse set of views. Nearest-neighbour lookups in this similarity cloud allow us to efficiently reconstruct accurate continuous selection masks over objects' surfaces that can be inspected from any view. Our method is multiview-consistent by design, alleviating the need for contrastive learning or feature-field pre-processing, and performs optimization-free selection in seconds. Our approach works on arbitrary 3D representations and outperforms several strong baselines in terms of selection accuracy and multiview consistency. It enables several compelling applications, such as replacing the diffuse-textured materials on a text-to-3D output, or selecting and editing materials on NeRFs and 3D-Gaussians.
PBIR-NIE: Glossy Object Capture under Non-Distant Lighting
Aug 13, 2024



Glossy objects present a significant challenge for 3D reconstruction from multi-view input images under natural lighting. In this paper, we introduce PBIR-NIE, an inverse rendering framework designed to holistically capture the geometry, material attributes, and surrounding illumination of such objects. We propose a novel parallax-aware non-distant environment map as a lightweight and efficient lighting representation, accurately modeling the near-field background of the scene, which is commonly encountered in real-world capture setups. This feature allows our framework to accommodate complex parallax effects beyond the capabilities of standard infinite-distance environment maps. Our method optimizes an underlying signed distance field (SDF) through physics-based differentiable rendering, seamlessly connecting surface gradients between a triangle mesh and the SDF via neural implicit evolution (NIE). To address the intricacies of highly glossy BRDFs in differentiable rendering, we integrate the antithetic sampling algorithm to mitigate variance in the Monte Carlo gradient estimator. Consequently, our framework exhibits robust capabilities in handling glossy object reconstruction, showcasing superior quality in geometry, relighting, and material estimation.
Multiple importance sampling for stochastic gradient estimation
Jul 22, 2024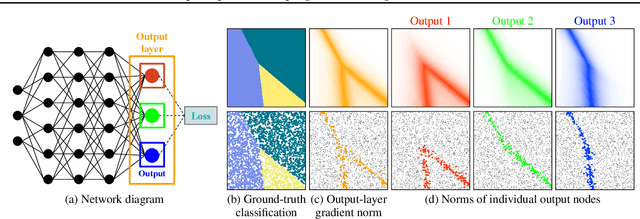
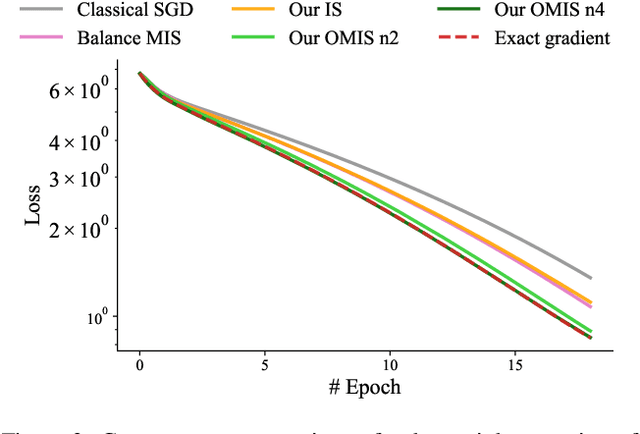
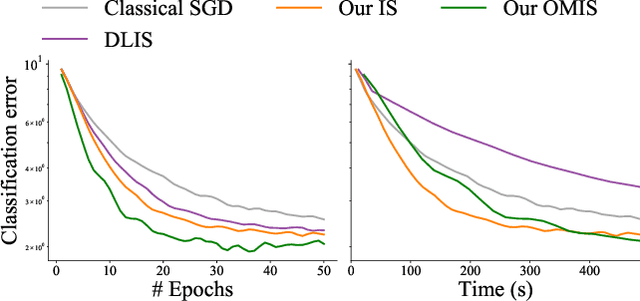
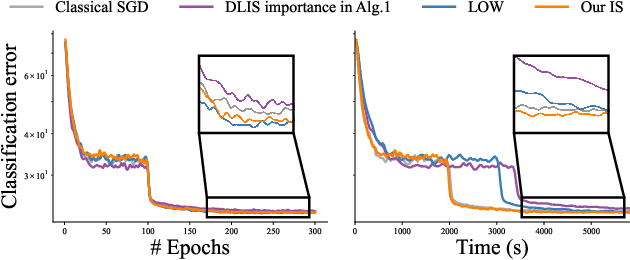
We introduce a theoretical and practical framework for efficient importance sampling of mini-batch samples for gradient estimation from single and multiple probability distributions. To handle noisy gradients, our framework dynamically evolves the importance distribution during training by utilizing a self-adaptive metric. Our framework combines multiple, diverse sampling distributions, each tailored to specific parameter gradients. This approach facilitates the importance sampling of vector-valued gradient estimation. Rather than naively combining multiple distributions, our framework involves optimally weighting data contribution across multiple distributions. This adapted combination of multiple importance yields superior gradient estimates, leading to faster training convergence. We demonstrate the effectiveness of our approach through empirical evaluations across a range of optimization tasks like classification and regression on both image and point cloud datasets.
N-BVH: Neural ray queries with bounding volume hierarchies
May 25, 2024



Neural representations have shown spectacular ability to compress complex signals in a fraction of the raw data size. In 3D computer graphics, the bulk of a scene's memory usage is due to polygons and textures, making them ideal candidates for neural compression. Here, the main challenge lies in finding good trade-offs between efficient compression and cheap inference while minimizing training time. In the context of rendering, we adopt a ray-centric approach to this problem and devise N-BVH, a neural compression architecture designed to answer arbitrary ray queries in 3D. Our compact model is learned from the input geometry and substituted for it whenever a ray intersection is queried by a path-tracing engine. While prior neural compression methods have focused on point queries, ours proposes neural ray queries that integrate seamlessly into standard ray-tracing pipelines. At the core of our method, we employ an adaptive BVH-driven probing scheme to optimize the parameters of a multi-resolution hash grid, focusing its neural capacity on the sparse 3D occupancy swept by the original surfaces. As a result, our N-BVH can serve accurate ray queries from a representation that is more than an order of magnitude more compact, providing faithful approximations of visibility, depth, and appearance attributes. The flexibility of our method allows us to combine and overlap neural and non-neural entities within the same 3D scene and extends to appearance level of detail.
* 10 pages
Neural Directional Encoding for Efficient and Accurate View-Dependent Appearance Modeling
May 23, 2024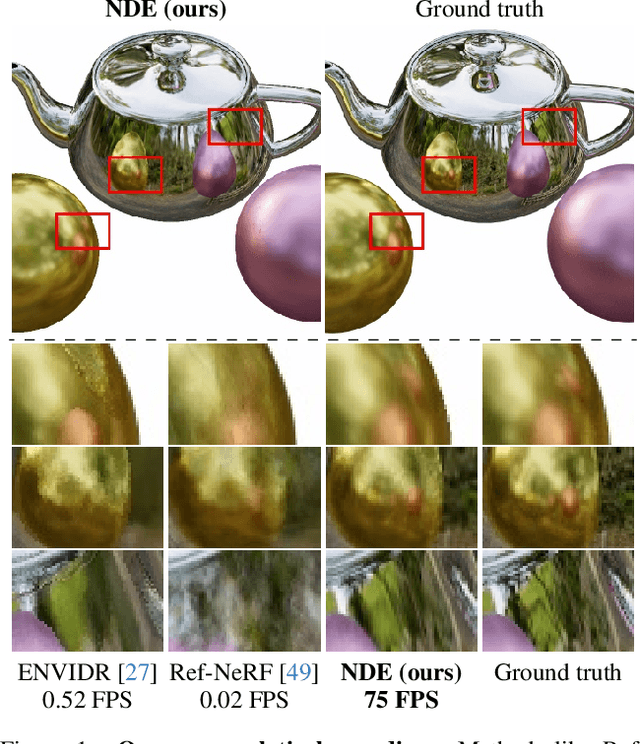
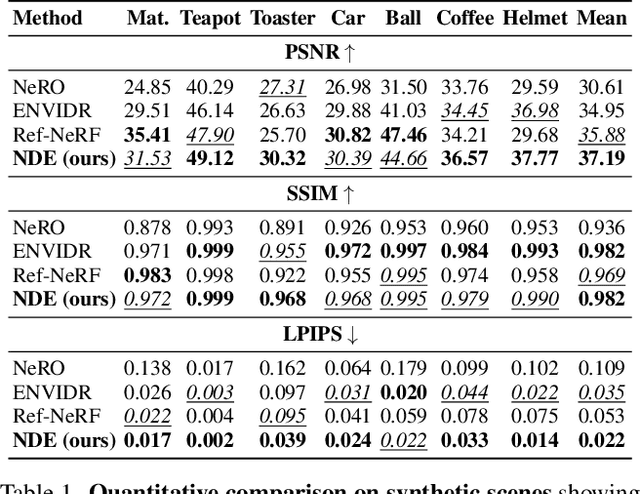
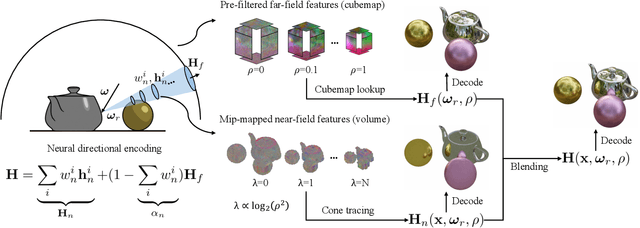
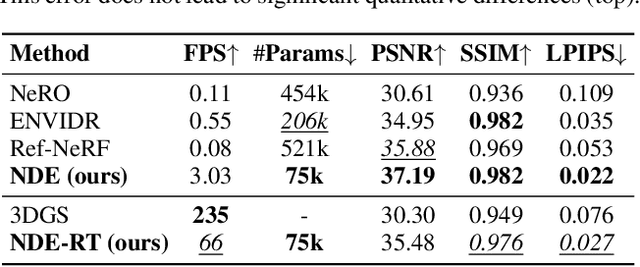
Novel-view synthesis of specular objects like shiny metals or glossy paints remains a significant challenge. Not only the glossy appearance but also global illumination effects, including reflections of other objects in the environment, are critical components to faithfully reproduce a scene. In this paper, we present Neural Directional Encoding (NDE), a view-dependent appearance encoding of neural radiance fields (NeRF) for rendering specular objects. NDE transfers the concept of feature-grid-based spatial encoding to the angular domain, significantly improving the ability to model high-frequency angular signals. In contrast to previous methods that use encoding functions with only angular input, we additionally cone-trace spatial features to obtain a spatially varying directional encoding, which addresses the challenging interreflection effects. Extensive experiments on both synthetic and real datasets show that a NeRF model with NDE (1) outperforms the state of the art on view synthesis of specular objects, and (2) works with small networks to allow fast (real-time) inference. The project webpage and source code are available at: \url{https://lwwu2.github.io/nde/}.
RGB$\leftrightarrow$X: Image decomposition and synthesis using material- and lighting-aware diffusion models
May 01, 2024



The three areas of realistic forward rendering, per-pixel inverse rendering, and generative image synthesis may seem like separate and unrelated sub-fields of graphics and vision. However, recent work has demonstrated improved estimation of per-pixel intrinsic channels (albedo, roughness, metallicity) based on a diffusion architecture; we call this the RGB$\rightarrow$X problem. We further show that the reverse problem of synthesizing realistic images given intrinsic channels, X$\rightarrow$RGB, can also be addressed in a diffusion framework. Focusing on the image domain of interior scenes, we introduce an improved diffusion model for RGB$\rightarrow$X, which also estimates lighting, as well as the first diffusion X$\rightarrow$RGB model capable of synthesizing realistic images from (full or partial) intrinsic channels. Our X$\rightarrow$RGB model explores a middle ground between traditional rendering and generative models: we can specify only certain appearance properties that should be followed, and give freedom to the model to hallucinate a plausible version of the rest. This flexibility makes it possible to use a mix of heterogeneous training datasets, which differ in the available channels. We use multiple existing datasets and extend them with our own synthetic and real data, resulting in a model capable of extracting scene properties better than previous work and of generating highly realistic images of interior scenes.