 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuetSVG: Unified Multimodal SVG Generation with Internal Visual Guidance
Dec 11, 2025Recent vision-language model (VLM)-based approaches have achieved impressive results on SVG generation. However, because they generate only text and lack visual signals during decoding, they often struggle with complex semantics and fail to produce visually appealing or geometrically coherent SVGs. We introduce DuetSVG, a unified multimodal model that jointly generates image tokens and corresponding SVG tokens in an end-to-end manner. DuetSVG is trained on both image and SVG datasets. At inference, we apply a novel test-time scaling strategy that leverages the model's native visual predictions as guidance to improve SVG decoding quality. Extensive experiments show that our method outperforms existing methods, producing visually faithful, semantically aligned, and syntactically clean SVGs across a wide range of applications.
Diffusion Transformer-to-Mamba Distillation for High-Resolution Image Generation
Jun 23, 2025
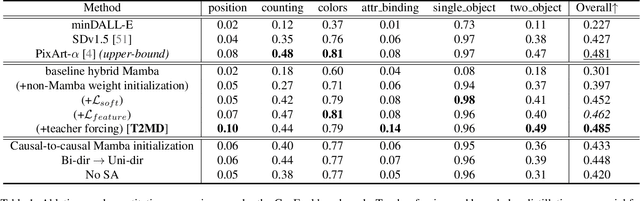
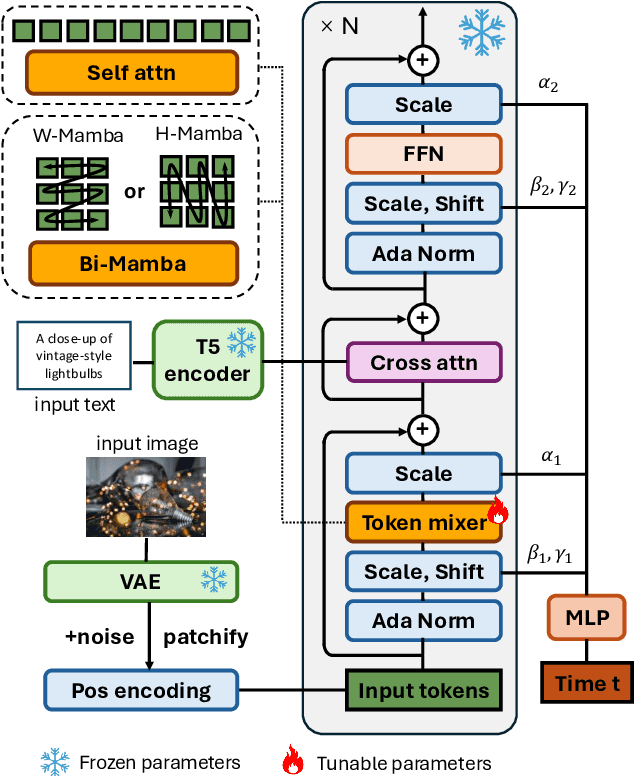
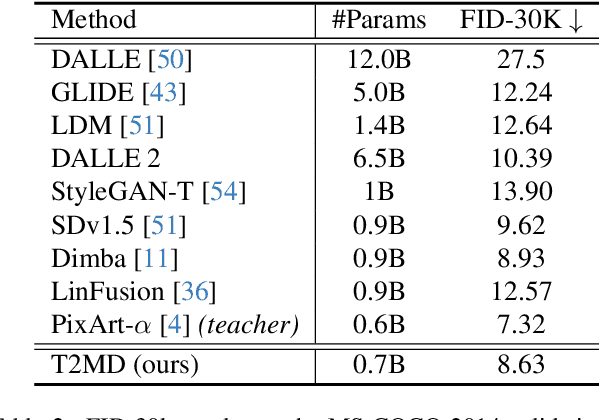
The quadratic computational complexity of self-attention in diffusion transformers (DiT) introduces substantial computational costs in high-resolution image generation. While the linear-complexity Mamba model emerges as a potential alternative, direct Mamba training remains empirically challenging. To address this issue, this paper introduces diffusion transformer-to-mamba distillation (T2MD), forming an efficient training pipeline that facilitates the transition from the self-attention-based transformer to the linear complexity state-space model Mamba. We establish a diffusion self-attention and Mamba hybrid model that simultaneously achieves efficiency and global dependencies. With the proposed layer-level teacher forcing and feature-based knowledge distillation, T2MD alleviates the training difficulty and high cost of a state space model from scratch. Starting from the distilled 512$\times$512 resolution base model, we push the generation towards 2048$\times$2048 images via lightweight adaptation and high-resolution fine-tuning. Experiments demonstrate that our training path leads to low overhead but high-quality text-to-image generation. Importantly, our results also justify the feasibility of using sequential and causal Mamba models for generating non-causal visual output, suggesting the potential for future exploration.
Visual Persona: Foundation Model for Full-Body Human Customization
Mar 19, 2025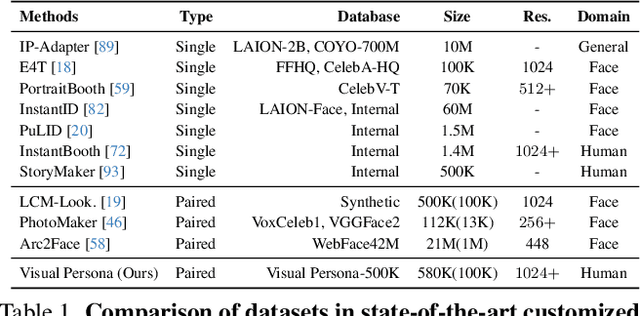



We introduce Visual Persona, a foundation model for text-to-image full-body human customization that, given a single in-the-wild human image, generates diverse images of the individual guided by text descriptions. Unlike prior methods that focus solely on preserving facial identity, our approach captures detailed full-body appearance, aligning with text descriptions for body structure and scene variations. Training this model requires large-scale paired human data, consisting of multiple images per individual with consistent full-body identities, which is notoriously difficult to obtain. To address this, we propose a data curation pipeline leveraging vision-language models to evaluate full-body appearance consistency, resulting in Visual Persona-500K, a dataset of 580k paired human images across 100k unique identities. For precise appearance transfer, we introduce a transformer encoder-decoder architecture adapted to a pre-trained text-to-image diffusion model, which augments the input image into distinct body regions, encodes these regions as local appearance features, and projects them into dense identity embeddings independently to condition the diffusion model for synthesizing customized images. Visual Persona consistently surpasses existing approaches, generating high-quality, customized images from in-the-wild inputs. Extensive ablation studies validate design choices, and we demonstrate the versatility of Visual Persona across various downstream tasks.
VEGGIE: Instructional Editing and Reasoning of Video Concepts with Grounded Generation
Mar 19, 2025Recent video diffusion models have enhanced video editing, but it remains challenging to handle instructional editing and diverse tasks (e.g., adding, removing, changing) within a unified framework. In this paper, we introduce VEGGIE, a Video Editor with Grounded Generation from Instructions, a simple end-to-end framework that unifies video concept editing, grounding, and reasoning based on diverse user instructions. Specifically, given a video and text query, VEGGIE first utilizes an MLLM to interpret user intentions in instructions and ground them to the video contexts, generating frame-specific grounded task queries for pixel-space responses. A diffusion model then renders these plans and generates edited videos that align with user intent. To support diverse tasks and complex instructions, we employ a curriculum learning strategy: first aligning the MLLM and video diffusion model with large-scale instructional image editing data, followed by end-to-end fine-tuning on high-quality multitask video data. Additionally, we introduce a novel data synthesis pipeline to generate paired instructional video editing data for model training. It transforms static image data into diverse, high-quality video editing samples by leveraging Image-to-Video models to inject dynamics. VEGGIE shows strong performance in instructional video editing with different editing skills, outperforming the best instructional baseline as a versatile model, while other models struggle with multi-tasking. VEGGIE also excels in video object grounding and reasoning segmentation, where other baselines fail. We further reveal how the multiple tasks help each other and highlight promising applications like zero-shot multimodal instructional and in-context video editing.
How to Train Your Dragon: Automatic Diffusion-Based Rigging for Characters with Diverse Topologies
Mar 19, 2025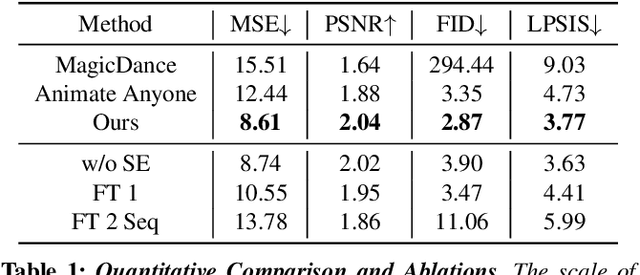
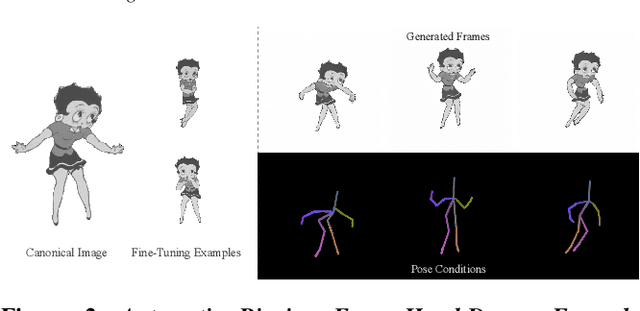
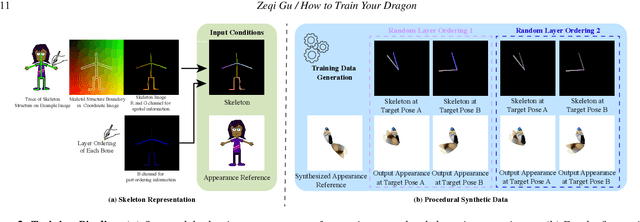
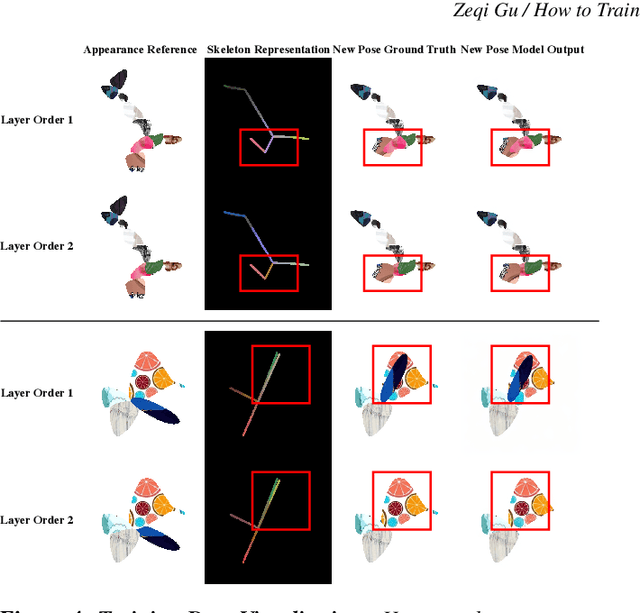
Recent diffusion-based methods have achieved impressive results on animating images of human subjects. However, most of that success has built on human-specific body pose representations and extensive training with labeled real videos. In this work, we extend the ability of such models to animate images of characters with more diverse skeletal topologies. Given a small number (3-5) of example frames showing the character in different poses with corresponding skeletal information, our model quickly infers a rig for that character that can generate images corresponding to new skeleton poses. We propose a procedural data generation pipeline that efficiently samples training data with diverse topologies on the fly. We use it, along with a novel skeleton representation, to train our model on articulated shapes spanning a large space of textures and topologies. Then during fine-tuning, our model rapidly adapts to unseen target characters and generalizes well to rendering new poses, both for realistic and more stylized cartoon appearances. To better evaluate performance on this novel and challenging task, we create the first 2D video dataset that contains both humanoid and non-humanoid subjects with per-frame keypoint annotations. With extensive experiments, we demonstrate the superior quality of our results. Project page: https://traindragondiffusion.github.io/
Mean-Shift Distillation for Diffusion Mode Seeking
Feb 21, 2025We present mean-shift distillation, a novel diffusion distillation technique that provides a provably good proxy for the gradient of the diffusion output distribution. This is derived directly from mean-shift mode seeking on the distribution, and we show that its extrema are aligned with the modes. We further derive an efficient product distribution sampling procedure to evaluate the gradient. Our method is formulated as a drop-in replacement for score distillation sampling (SDS), requiring neither model retraining nor extensive modification of the sampling procedure. We show that it exhibits superior mode alignment as well as improved convergence in both synthetic and practical setups, yielding higher-fidelity results when applied to both text-to-image and text-to-3D applications with Stable Diffusion.
DOLLAR: Few-Step Video Generation via Distillation and Latent Reward Optimization
Dec 20, 2024Diffusion probabilistic models have shown significant progress in video generation; however, their computational efficiency is limited by the large number of sampling steps required. Reducing sampling steps often compromises video quality or generation diversity. In this work, we introduce a distillation method that combines variational score distillation and consistency distillation to achieve few-step video generation, maintaining both high quality and diversity. We also propose a latent reward model fine-tuning approach to further enhance video generation performance according to any specified reward metric. This approach reduces memory usage and does not require the reward to be differentiable. Our method demonstrates state-of-the-art performance in few-step generation for 10-second videos (128 frames at 12 FPS). The distilled student model achieves a score of 82.57 on VBench, surpassing the teacher model as well as baseline models Gen-3, T2V-Turbo, and Kling. One-step distillation accelerates the teacher model's diffusion sampling by up to 278.6 times, enabling near real-time generation. Human evaluations further validate the superior performance of our 4-step student models compared to teacher model using 50-step DDIM sampling.
Move-in-2D: 2D-Conditioned Human Motion Generation
Dec 17, 2024



Generating realistic human videos remains a challenging task, with the most effective methods currently relying on a human motion sequence as a control signal. Existing approaches often use existing motion extracted from other videos, which restricts applications to specific motion types and global scene matching. We propose Move-in-2D, a novel approach to generate human motion sequences conditioned on a scene image, allowing for diverse motion that adapts to different scenes. Our approach utilizes a diffusion model that accepts both a scene image and text prompt as inputs, producing a motion sequence tailored to the scene. To train this model, we collect a large-scale video dataset featuring single-human activities, annotating each video with the corresponding human motion as the target output. Experiments demonstrate that our method effectively predicts human motion that aligns with the scene image after projection. Furthermore, we show that the generated motion sequence improves human motion quality in video synthesis tasks.
HARIVO: Harnessing Text-to-Image Models for Video Generation
Oct 10, 2024



We present a method to create diffusion-based video models from pretrained Text-to-Image (T2I) models. Recently, AnimateDiff proposed freezing the T2I model while only training temporal layers. We advance this method by proposing a unique architecture, incorporating a mapping network and frame-wise tokens, tailored for video generation while maintaining the diversity and creativity of the original T2I model. Key innovations include novel loss functions for temporal smoothness and a mitigating gradient sampling technique, ensuring realistic and temporally consistent video generation despite limited public video data. We have successfully integrated video-specific inductive biases into the architecture and loss functions. Our method, built on the frozen StableDiffusion model, simplifies training processes and allows for seamless integration with off-the-shelf models like ControlNet and DreamBooth. project page: https://kwonminki.github.io/HARIVO
Progressive Autoregressive Video Diffusion Models
Oct 10, 2024Current frontier video diffusion models have demonstrated remarkable results at generating high-quality videos. However, they can only generate short video clips, normally around 10 seconds or 240 frames, due to computation limitations during training. In this work, we show that existing models can be naturally extended to autoregressive video diffusion models without changing the architectures. Our key idea is to assign the latent frames with progressively increasing noise levels rather than a single noise level, which allows for fine-grained condition among the latents and large overlaps between the attention windows. Such progressive video denoising allows our models to autoregressively generate video frames without quality degradation or abrupt scene changes. We present state-of-the-art results on long video generation at 1 minute (1440 frames at 24 FPS). Videos from this paper are available at https://desaixie.github.io/pa-vdm/.