 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Train Your Dragon: Automatic Diffusion-Based Rigging for Characters with Diverse Topologies
Mar 19, 2025
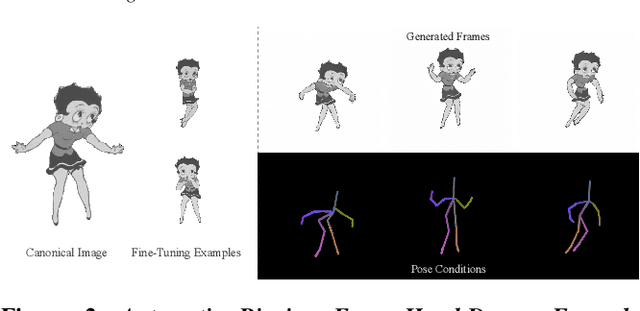
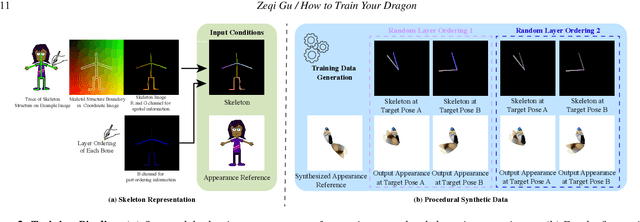
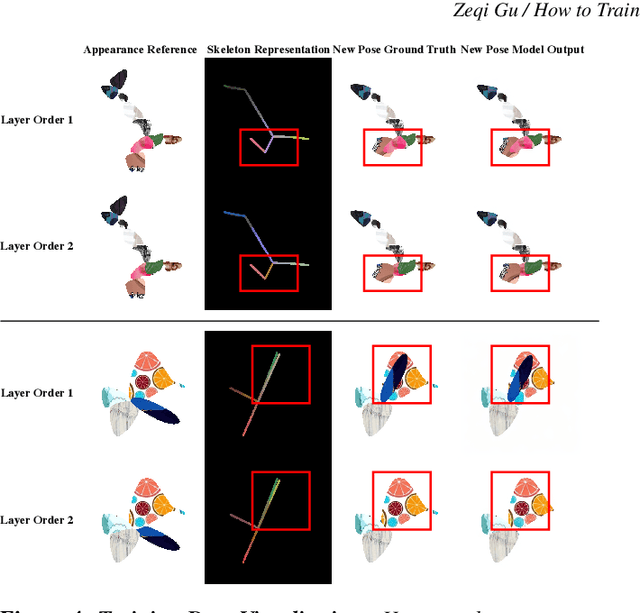
Recent diffusion-based methods have achieved impressive results on animating images of human subjects. However, most of that success has built on human-specific body pose representations and extensive training with labeled real videos. In this work, we extend the ability of such models to animate images of characters with more diverse skeletal topologies. Given a small number (3-5) of example frames showing the character in different poses with corresponding skeletal information, our model quickly infers a rig for that character that can generate images corresponding to new skeleton poses. We propose a procedural data generation pipeline that efficiently samples training data with diverse topologies on the fly. We use it, along with a novel skeleton representation, to train our model on articulated shapes spanning a large space of textures and topologies. Then during fine-tuning, our model rapidly adapts to unseen target characters and generalizes well to rendering new poses, both for realistic and more stylized cartoon appearances. To better evaluate performance on this novel and challenging task, we create the first 2D video dataset that contains both humanoid and non-humanoid subjects with per-frame keypoint annotations. With extensive experiments, we demonstrate the superior quality of our results. Project page: https://traindragondiffusion.github.io/
Filtered-Guided Diffusion: Fast Filter Guidance for Black-Box Diffusion Models
Jun 29, 2023


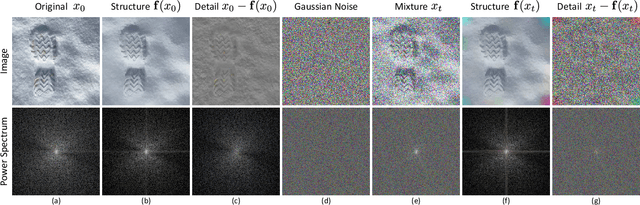
Recent advances in diffusion-based generative models have shown incredible promise for Image-to-Image translation and editing. Most recent work in this space relies on additional training or architecture-specific adjustments to the diffusion process. In this work, we show that much of this low-level control can be achieved without additional training or any access to features of the diffusion model. Our method simply applies a filter to the input of each diffusion step based on the output of the previous step in an adaptive manner. Notably, this approach does not depend on any specific architecture or sampler and can be done without access to internal features of the network, making it easy to combine with other techniques, samplers, and diffusion architectures. Furthermore, it has negligible cost to performance, and allows for more continuous adjustment of guidance strength than other approaches. We show FGD offers a fast and strong baseline that is competitive with recent architecture-dependent approaches. Furthermore, FGD can also be used as a simple add-on to enhance the structural guidance of other state-of-the-art I2I methods. Finally, our derivation of this method helps to understand the impact of self attention, a key component of other recent architecture-specific I2I approaches, in a more architecture-independent way. Project page: https://github.com/jaclyngu/FilteredGuidedDiffusion
Ray Conditioning: Trading Photo-consistency for Photo-realism in Multi-view Image Generation
Apr 26, 2023



Multi-view image generation attracts particular attention these days due to its promising 3D-related applications, e.g., image viewpoint editing. Most existing methods follow a paradigm where a 3D representation is first synthesized, and then rendered into 2D images to ensure photo-consistency across viewpoints. However, such explicit bias for photo-consistency sacrifices photo-realism, causing geometry artifacts and loss of fine-scale details when these methods are applied to edit real images. To address this issue, we propose ray conditioning, a geometry-free alternative that relaxes the photo-consistency constraint. Our method generates multi-view images by conditioning a 2D GAN on a light field prior. With explicit viewpoint control, state-of-the-art photo-realism and identity consistency, our method is particularly suited for the viewpoint editing task.
FactorMatte: Redefining Video Matting for Re-Composition Tasks
Nov 03, 2022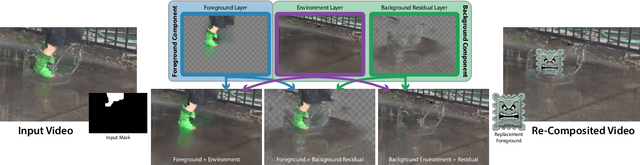

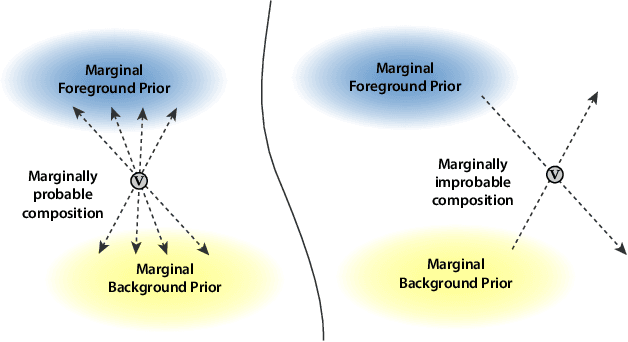

We propose "factor matting", an alternative formulation of the video matting problem in terms of counterfactual video synthesis that is better suited for re-composition tasks. The goal of factor matting is to separate the contents of video into independent components, each visualizing a counterfactual version of the scene where contents of other components have been removed. We show that factor matting maps well to a more general Bayesian framing of the matting problem that accounts for complex conditional interactions between layers. Based on this observation, we present a method for solving the factor matting problem that produces useful decompositions even for video with complex cross-layer interactions like splashes, shadows, and reflections. Our method is trained per-video and requires neither pre-training on external large datasets, nor knowledge about the 3D structure of the scene. We conduct extensive experiments, and show that our method not only can disentangle scenes with complex interactions, but also outperforms top methods on existing tasks such as classical video matting and background subtraction. In addition, we demonstrate the benefits of our approach on a range of downstream tasks. Please refer to our project webpage for more details: https://factormatte.github.io
Crowdsampling the Plenoptic Function
Jul 30, 2020
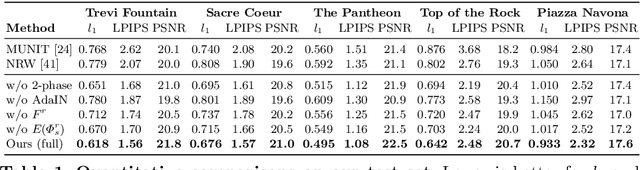


Many popular tourist landmarks are captured in a multitude of online, public photos. These photos represent a sparse and unstructured sampling of the plenoptic function for a particular scene. In this paper,we present a new approach to novel view synthesis under time-varying illumination from such data. Our approach builds on the recent multi-plane image (MPI) format for representing local light fields under fixed viewing conditions. We introduce a new DeepMPI representation, motivated by observations on the sparsity structure of the plenoptic function, that allows for real-time synthesis of photorealistic views that are continuous in both space and across changes in lighting. Our method can synthesize the same compelling parallax and view-dependent effects as previous MPI methods, while simultaneously interpolating along changes in reflectance and illumination with time. We show how to learn a model of these effects in an unsupervised way from an unstructured collection of photos without temporal registration, demonstrating significant improvements over recent work in neural rendering. More information can be found crowdsampling.io.
Visual Chirality
Jun 16, 2020


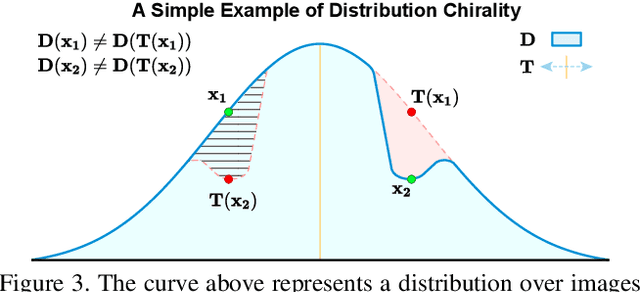
How can we tell whether an image has been mirrored? While we understand the geometry of mirror reflections very well, less has been said about how it affects distributions of imagery at scale, despite widespread use for data augmentation in computer vision. In this paper, we investigate how the statistics of visual data are changed by reflection. We refer to these changes as "visual chirality", after the concept of geometric chirality - the notion of objects that are distinct from their mirror image. Our analysis of visual chirality reveals surprising results, including low-level chiral signals pervading imagery stemming from image processing in cameras, to the ability to discover visual chirality in images of people and faces. Our work has implications for data augmentation, self-supervised learning, and image forensics.
* Published at CVPR 2020, Best Paper Nomination, Oral Presentation. Project Page: https://linzhiqiu.github.io/papers/chirality/