 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Train Your Dragon: Automatic Diffusion-Based Rigging for Characters with Diverse Topologies
Paper and Code
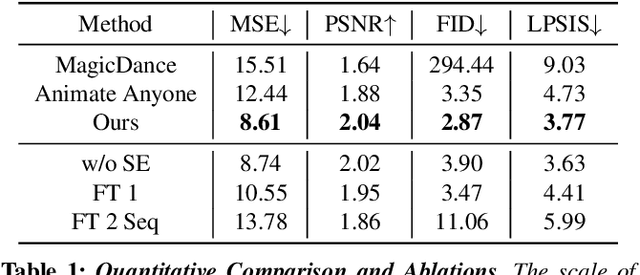
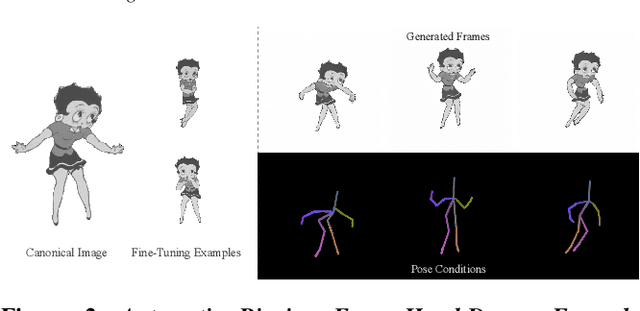
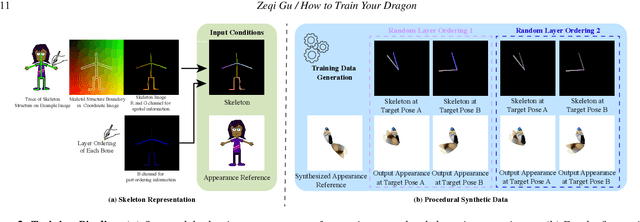
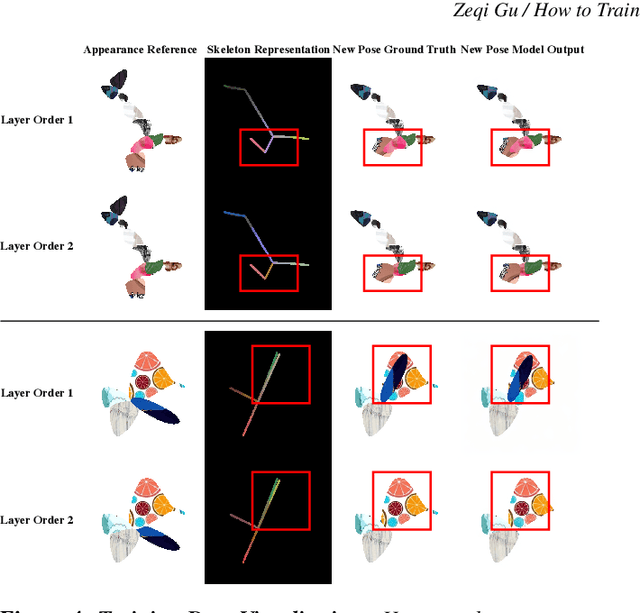
Recent diffusion-based methods have achieved impressive results on animating images of human subjects. However, most of that success has built on human-specific body pose representations and extensive training with labeled real videos. In this work, we extend the ability of such models to animate images of characters with more diverse skeletal topologies. Given a small number (3-5) of example frames showing the character in different poses with corresponding skeletal information, our model quickly infers a rig for that character that can generate images corresponding to new skeleton poses. We propose a procedural data generation pipeline that efficiently samples training data with diverse topologies on the fly. We use it, along with a novel skeleton representation, to train our model on articulated shapes spanning a large space of textures and topologies. Then during fine-tuning, our model rapidly adapts to unseen target characters and generalizes well to rendering new poses, both for realistic and more stylized cartoon appearances. To better evaluate performance on this novel and challenging task, we create the first 2D video dataset that contains both humanoid and non-humanoid subjects with per-frame keypoint annotations. With extensive experiments, we demonstrate the superior quality of our results. Project page: https://traindragondiffusion.github.io/