 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuetSVG: Unified Multimodal SVG Generation with Internal Visual Guidance
Dec 11, 2025Recent vision-language model (VLM)-based approaches have achieved impressive results on SVG generation. However, because they generate only text and lack visual signals during decoding, they often struggle with complex semantics and fail to produce visually appealing or geometrically coherent SVGs. We introduce DuetSVG, a unified multimodal model that jointly generates image tokens and corresponding SVG tokens in an end-to-end manner. DuetSVG is trained on both image and SVG datasets. At inference, we apply a novel test-time scaling strategy that leverages the model's native visual predictions as guidance to improve SVG decoding quality. Extensive experiments show that our method outperforms existing methods, producing visually faithful, semantically aligned, and syntactically clean SVGs across a wide range of applications.
How to Train Your Dragon: Automatic Diffusion-Based Rigging for Characters with Diverse Topologies
Mar 19, 2025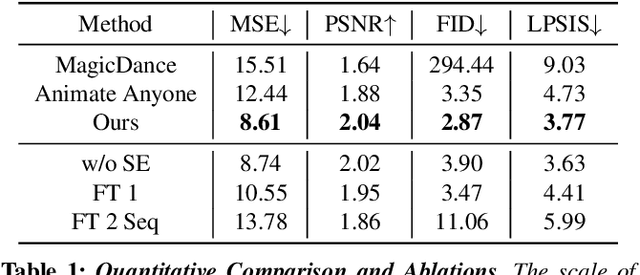
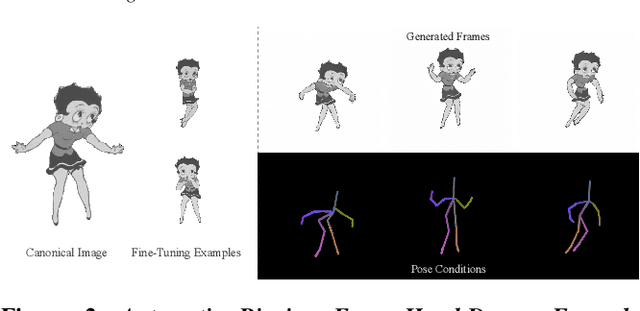
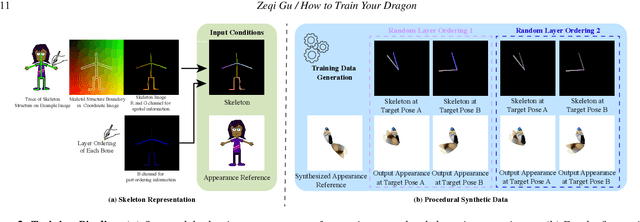
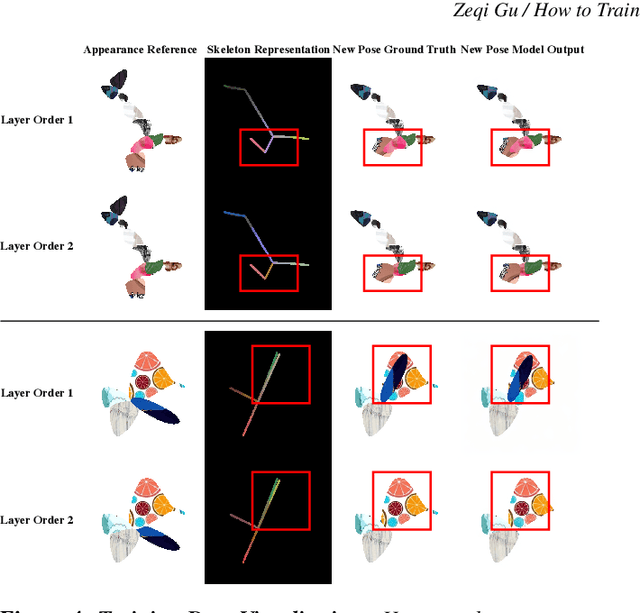
Recent diffusion-based methods have achieved impressive results on animating images of human subjects. However, most of that success has built on human-specific body pose representations and extensive training with labeled real videos. In this work, we extend the ability of such models to animate images of characters with more diverse skeletal topologies. Given a small number (3-5) of example frames showing the character in different poses with corresponding skeletal information, our model quickly infers a rig for that character that can generate images corresponding to new skeleton poses. We propose a procedural data generation pipeline that efficiently samples training data with diverse topologies on the fly. We use it, along with a novel skeleton representation, to train our model on articulated shapes spanning a large space of textures and topologies. Then during fine-tuning, our model rapidly adapts to unseen target characters and generalizes well to rendering new poses, both for realistic and more stylized cartoon appearances. To better evaluate performance on this novel and challenging task, we create the first 2D video dataset that contains both humanoid and non-humanoid subjects with per-frame keypoint annotations. With extensive experiments, we demonstrate the superior quality of our results. Project page: https://traindragondiffusion.github.io/
Mean-Shift Distillation for Diffusion Mode Seeking
Feb 21, 2025We present mean-shift distillation, a novel diffusion distillation technique that provides a provably good proxy for the gradient of the diffusion output distribution. This is derived directly from mean-shift mode seeking on the distribution, and we show that its extrema are aligned with the modes. We further derive an efficient product distribution sampling procedure to evaluate the gradient. Our method is formulated as a drop-in replacement for score distillation sampling (SDS), requiring neither model retraining nor extensive modification of the sampling procedure. We show that it exhibits superior mode alignment as well as improved convergence in both synthetic and practical setups, yielding higher-fidelity results when applied to both text-to-image and text-to-3D applications with Stable Diffusion.
ShapeShifter: 3D Variations Using Multiscale and Sparse Point-Voxel Diffusion
Feb 04, 2025



This paper proposes ShapeShifter, a new 3D generative model that learns to synthesize shape variations based on a single reference model. While generative methods for 3D objects have recently attracted much attention, current techniques often lack geometric details and/or require long training times and large resources. Our approach remedies these issues by combining sparse voxel grids and point, normal, and color sampling within a multiscale neural architecture that can be trained efficiently and in parallel. We show that our resulting variations better capture the fine details of their original input and can handle more general types of surfaces than previous SDF-based methods. Moreover, we offer interactive generation of 3D shape variants, allowing more human control in the design loop if needed.
DMesh++: An Efficient Differentiable Mesh for Complex Shapes
Dec 21, 2024



Recent probabilistic methods for 3D triangular meshes capture diverse shapes by differentiable mesh connectivity, but face high computational costs with increased shape details. We introduce a new differentiable mesh processing method in 2D and 3D that addresses this challenge and efficiently handles meshes with intricate structures. Additionally, we present an algorithm that adapts the mesh resolution to local geometry in 2D for efficient representation. We demonstrate the effectiveness of our approach on 2D point cloud and 3D multi-view reconstruction tasks. Visit our project page (https://sonsang.github.io/dmesh2-project) for source code and supplementary material.
Pattern Analogies: Learning to Perform Programmatic Image Edits by Analogy
Dec 17, 2024Pattern images are everywhere in the digital and physical worlds, and tools to edit them are valuable. But editing pattern images is tricky: desired edits are often programmatic: structure-aware edits that alter the underlying program which generates the pattern. One could attempt to infer this underlying program, but current methods for doing so struggle with complex images and produce unorganized programs that make editing tedious. In this work, we introduce a novel approach to perform programmatic edits on pattern images. By using a pattern analogy -- a pair of simple patterns to demonstrate the intended edit -- and a learning-based generative model to execute these edits, our method allows users to intuitively edit patterns. To enable this paradigm, we introduce SplitWeave, a domain-specific language that, combined with a framework for sampling synthetic pattern analogies, enables the creation of a large, high-quality synthetic training dataset. We also present TriFuser, a Latent Diffusion Model (LDM) designed to overcome critical issues that arise when naively deploying LDMs to this task. Extensive experiments on real-world, artist-sourced patterns reveals that our method faithfully performs the demonstrated edit while also generalizing to related pattern styles beyond its training distribution.
Temporal Residual Jacobians For Rig-free Motion Transfer
Jul 20, 2024We introduce Temporal Residual Jacobians as a novel representation to enable data-driven motion transfer. Our approach does not assume access to any rigging or intermediate shape keyframes, produces geometrically and temporally consistent motions, and can be used to transfer long motion sequences. Central to our approach are two coupled neural networks that individually predict local geometric and temporal changes that are subsequently integrated, spatially and temporally, to produce the final animated meshes. The two networks are jointly trained, complement each other in producing spatial and temporal signals, and are supervised directly with 3D positional information. During inference, in the absence of keyframes, our method essentially solves a motion extrapolation problem. We test our setup on diverse meshes (synthetic and scanned shapes) to demonstrate its superiority in generating realistic and natural-looking animations on unseen body shapes against SoTA alternatives. Supplemental video and code are available at https://temporaljacobians.github.io/ .
NIVeL: Neural Implicit Vector Layers for Text-to-Vector Generation
May 24, 2024



The success of denoising diffusion models in representing rich data distributions over 2D raster images has prompted research on extending them to other data representations, such as vector graphics. Unfortunately due to their variable structure and scarcity of vector training data, directly applying diffusion models on this domain remains a challenging problem. Using workarounds like optimization via Score Distillation Sampling (SDS) is also fraught with difficulty, as vector representations are non trivial to directly optimize and tend to result in implausible geometries such as redundant or self-intersecting shapes. NIVeL addresses these challenges by reinterpreting the problem on an alternative, intermediate domain which preserves the desirable properties of vector graphics -- mainly sparsity of representation and resolution-independence. This alternative domain is based on neural implicit fields expressed in a set of decomposable, editable layers. Based on our experiments, NIVeL produces text-to-vector graphics results of significantly better quality than the state-of-the-art.
Personalized Residuals for Concept-Driven Text-to-Image Generation
May 21, 2024
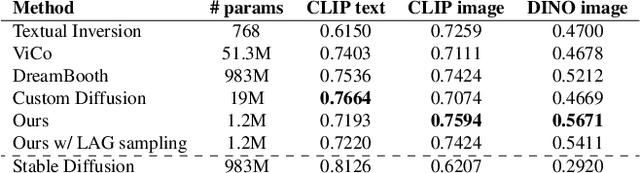
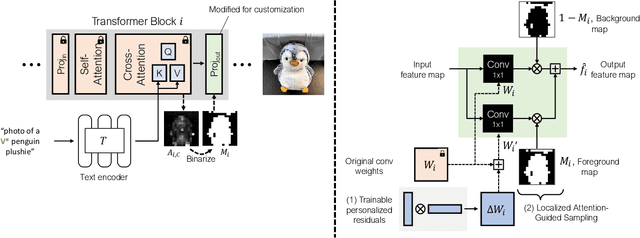
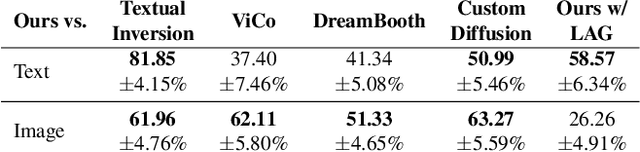
We present personalized residuals and localized attention-guided sampling for efficient concept-driven generation using text-to-image diffusion models. Our method first represents concepts by freezing the weights of a pretrained text-conditioned diffusion model and learning low-rank residuals for a small subset of the model's layers. The residual-based approach then directly enables application of our proposed sampling technique, which applies the learned residuals only in areas where the concept is localized via cross-attention and applies the original diffusion weights in all other regions. Localized sampling therefore combines the learned identity of the concept with the existing generative prior of the underlying diffusion model. We show that personalized residuals effectively capture the identity of a concept in ~3 minutes on a single GPU without the use of regularization images and with fewer parameters than previous models, and localized sampling allows using the original model as strong prior for large parts of the image.
Learning Continuous 3D Words for Text-to-Image Generation
Feb 13, 2024Current controls over diffusion models (e.g., through text or ControlNet) for image generation fall short in recognizing abstract, continuous attributes like illumination direction or non-rigid shape change. In this paper, we present an approach for allowing users of text-to-image models to have fine-grained control of several attributes in an image. We do this by engineering special sets of input tokens that can be transformed in a continuous manner -- we call them Continuous 3D Words. These attributes can, for example, be represented as sliders and applied jointly with text prompts for fine-grained control over image generation. Given only a single mesh and a rendering engine, we show that our approach can be adopted to provide continuous user control over several 3D-aware attributes, including time-of-day illumination, bird wing orientation, dollyzoom effect, and object poses. Our method is capable of conditioning image creation with multiple Continuous 3D Words and text descriptions simultaneously while adding no overhead to the generative process. Project Page: https://ttchengab.github.io/continuous_3d_words