 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVOID: Video Object and Interaction Deletion
Apr 02, 2026Existing video object removal methods excel at inpainting content "behind" the object and correcting appearance-level artifacts such as shadows and reflections. However, when the removed object has more significant interactions, such as collisions with other objects, current models fail to correct them and produce implausible results. We present VOID, a video object removal framework designed to perform physically-plausible inpainting in these complex scenarios. To train the model, we generate a new paired dataset of counterfactual object removals using Kubric and HUMOTO, where removing an object requires altering downstream physical interactions. During inference, a vision-language model identifies regions of the scene affected by the removed object. These regions are then used to guide a video diffusion model that generates physically consistent counterfactual outcomes. Experiments on both synthetic and real data show that our approach better preserves consistent scene dynamics after object removal compared to prior video object removal methods. We hope this framework sheds light on how to make video editing models better simulators of the world through high-level causal reasoning.
MARBLE: Material Recomposition and Blending in CLIP-Space
Jun 05, 2025



Editing materials of objects in images based on exemplar images is an active area of research in computer vision and graphics. We propose MARBLE, a method for performing material blending and recomposing fine-grained material properties by finding material embeddings in CLIP-space and using that to control pre-trained text-to-image models. We improve exemplar-based material editing by finding a block in the denoising UNet responsible for material attribution. Given two material exemplar-images, we find directions in the CLIP-space for blending the materials. Further, we can achieve parametric control over fine-grained material attributes such as roughness, metallic, transparency, and glow using a shallow network to predict the direction for the desired material attribute change. We perform qualitative and quantitative analysis to demonstrate the efficacy of our proposed method. We also present the ability of our method to perform multiple edits in a single forward pass and applicability to painting. Project Page: https://marblecontrol.github.io/
Seeing from Another Perspective: Evaluating Multi-View Understanding in MLLMs
Apr 21, 2025



Multi-view understanding, the ability to reconcile visual information across diverse viewpoints for effective navigation, manipulation, and 3D scene comprehension, is a fundamental challenge in Multi-Modal Large Language Models (MLLMs) to be used as embodied agents. While recent MLLMs have shown impressive advances in high-level reasoning and planning, they frequently fall short when confronted with multi-view geometric consistency and cross-view correspondence. To comprehensively evaluate the challenges of MLLMs in multi-view scene reasoning, we propose All-Angles Bench, a benchmark of over 2,100 human carefully annotated multi-view question-answer pairs across 90 diverse real-world scenes. Our six tasks (counting, attribute identification, relative distance, relative direction, object manipulation, and camera pose estimation) specifically test model's geometric correspondence and the capacity to align information consistently across views. Our extensive experiments, benchmark on 27 representative MLLMs including Gemini-2.0-Flash, Claude-3.7-Sonnet, and GPT-4o against human evaluators reveals a substantial performance gap, indicating that current MLLMs remain far from human-level proficiency. Through in-depth analysis, we show that MLLMs are particularly underperforming under two aspects: (1) cross-view correspondence for partially occluded views and (2) establishing the coarse camera poses. These findings highlight the necessity of domain-specific refinements or modules that embed stronger multi-view awareness. We believe that our All-Angles Bench offers valuable insights and contribute to bridging the gap between MLLMs and human-level multi-view understanding. The project and benchmark are publicly available at https://danielchyeh.github.io/All-Angles-Bench/.
ZeST: Zero-Shot Material Transfer from a Single Image
Apr 09, 2024We propose ZeST, a method for zero-shot material transfer to an object in the input image given a material exemplar image. ZeST leverages existing diffusion adapters to extract implicit material representation from the exemplar image. This representation is used to transfer the material using pre-trained inpainting diffusion model on the object in the input image using depth estimates as geometry cue and grayscale object shading as illumination cues. The method works on real images without any training resulting a zero-shot approach. Both qualitative and quantitative results on real and synthetic datasets demonstrate that ZeST outputs photorealistic images with transferred materials. We also show the application of ZeST to perform multiple edits and robust material assignment under different illuminations. Project Page: https://ttchengab.github.io/zest
See, Imagine, Plan: Discovering and Hallucinating Tasks from a Single Image
Mar 24, 2024



Humans can not only recognize and understand the world in its current state but also envision future scenarios that extend beyond immediate perception. To resemble this profound human capacity, we introduce zero-shot task hallucination -- given a single RGB image of any scene comprising unknown environments and objects, our model can identify potential tasks and imagine their execution in a vivid narrative, realized as a video. We develop a modular pipeline that progressively enhances scene decomposition, comprehension, and reconstruction, incorporating VLM for dynamic interaction and 3D motion planning for object trajectories. Our model can discover diverse tasks, with the generated task videos demonstrating realistic and compelling visual outcomes that are understandable by both machines and humans. Project Page: https://dannymcy.github.io/zeroshot_task_hallucination/
Gen4Gen: Generative Data Pipeline for Generative Multi-Concept Composition
Feb 23, 2024Recent text-to-image diffusion models are able to learn and synthesize images containing novel, personalized concepts (e.g., their own pets or specific items) with just a few examples for training. This paper tackles two interconnected issues within this realm of personalizing text-to-image diffusion models. First, current personalization techniques fail to reliably extend to multiple concepts -- we hypothesize this to be due to the mismatch between complex scenes and simple text descriptions in the pre-training dataset (e.g., LAION). Second, given an image containing multiple personalized concepts, there lacks a holistic metric that evaluates performance on not just the degree of resemblance of personalized concepts, but also whether all concepts are present in the image and whether the image accurately reflects the overall text description. To address these issues, we introduce Gen4Gen, a semi-automated dataset creation pipeline utilizing generative models to combine personalized concepts into complex compositions along with text-descriptions. Using this, we create a dataset called MyCanvas, that can be used to benchmark the task of multi-concept personalization. In addition, we design a comprehensive metric comprising two scores (CP-CLIP and TI-CLIP) for better quantifying the performance of multi-concept, personalized text-to-image diffusion methods. We provide a simple baseline built on top of Custom Diffusion with empirical prompting strategies for future researchers to evaluate on MyCanvas. We show that by improving data quality and prompting strategies, we can significantly increase multi-concept personalized image generation quality, without requiring any modifications to model architecture or training algorithms.
Learning Continuous 3D Words for Text-to-Image Generation
Feb 13, 2024Current controls over diffusion models (e.g., through text or ControlNet) for image generation fall short in recognizing abstract, continuous attributes like illumination direction or non-rigid shape change. In this paper, we present an approach for allowing users of text-to-image models to have fine-grained control of several attributes in an image. We do this by engineering special sets of input tokens that can be transformed in a continuous manner -- we call them Continuous 3D Words. These attributes can, for example, be represented as sliders and applied jointly with text prompts for fine-grained control over image generation. Given only a single mesh and a rendering engine, we show that our approach can be adopted to provide continuous user control over several 3D-aware attributes, including time-of-day illumination, bird wing orientation, dollyzoom effect, and object poses. Our method is capable of conditioning image creation with multiple Continuous 3D Words and text descriptions simultaneously while adding no overhead to the generative process. Project Page: https://ttchengab.github.io/continuous_3d_words
3DMiner: Discovering Shapes from Large-Scale Unannotated Image Datasets
Oct 29, 2023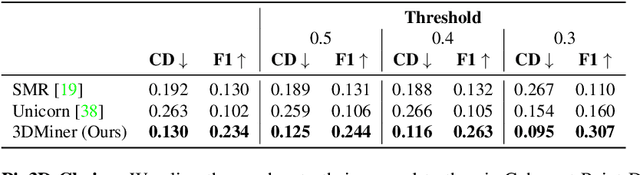
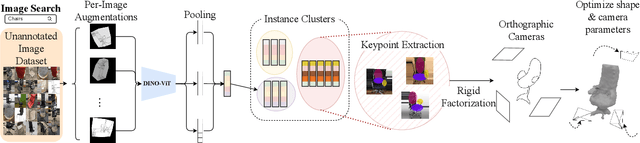
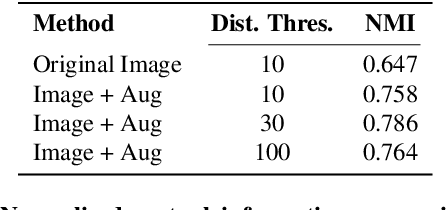

We present 3DMiner -- a pipeline for mining 3D shapes from challenging large-scale unannotated image datasets. Unlike other unsupervised 3D reconstruction methods, we assume that, within a large-enough dataset, there must exist images of objects with similar shapes but varying backgrounds, textures, and viewpoints. Our approach leverages the recent advances in learning self-supervised image representations to cluster images with geometrically similar shapes and find common image correspondences between them. We then exploit these correspondences to obtain rough camera estimates as initialization for bundle-adjustment. Finally, for every image cluster, we apply a progressive bundle-adjusting reconstruction method to learn a neural occupancy field representing the underlying shape. We show that this procedure is robust to several types of errors introduced in previous steps (e.g., wrong camera poses, images containing dissimilar shapes, etc.), allowing us to obtain shape and pose annotations for images in-the-wild. When using images from Pix3D chairs, our method is capable of producing significantly better results than state-of-the-art unsupervised 3D reconstruction techniques, both quantitatively and qualitatively. Furthermore, we show how 3DMiner can be applied to in-the-wild data by reconstructing shapes present in images from the LAION-5B dataset. Project Page: https://ttchengab.github.io/3dminerOfficial
Multi-body SE(3) Equivariance for Unsupervised Rigid Segmentation and Motion Estimation
Jun 08, 2023A truly generalizable approach to rigid segmentation and motion estimation is fundamental to 3D understanding of articulated objects and moving scenes. In view of the tightly coupled relationship between segmentation and motion estimates, we present an SE(3) equivariant architecture and a training strategy to tackle this task in an unsupervised manner. Our architecture comprises two lightweight and inter-connected heads that predict segmentation masks using point-level invariant features and motion estimates from SE(3) equivariant features without the prerequisites of category information. Our unified training strategy can be performed online while jointly optimizing the two predictions by exploiting the interrelations among scene flow, segmentation mask, and rigid transformations. We show experiments on four datasets as evidence of the superiority of our method both in terms of model performance and computational efficiency with only 0.25M parameters and 0.92G FLOPs. To the best of our knowledge, this is the first work designed for category-agnostic part-level SE(3) equivariance in dynamic point clouds.
Meta-Sampler: Almost-Universal yet Task-Oriented Sampling for Point Clouds
Mar 30, 2022Sampling is a key operation in point-cloud task and acts to increase computational efficiency and tractability by discarding redundant points. Universal sampling algorithms (e.g., Farthest Point Sampling) work without modification across different tasks, models, and datasets, but by their very nature are agnostic about the downstream task/model. As such, they have no implicit knowledge about which points would be best to keep and which to reject. Recent work has shown how task-specific point cloud sampling (e.g., SampleNet) can be used to outperform traditional sampling approaches by learning which points are more informative. However, these learnable samplers face two inherent issues: i) overfitting to a model rather than a task, and \ii) requiring training of the sampling network from scratch, in addition to the task network, somewhat countering the original objective of down-sampling to increase efficiency. In this work, we propose an almost-universal sampler, in our quest for a sampler that can learn to preserve the most useful points for a particular task, yet be inexpensive to adapt to different tasks, models, or datasets. We first demonstrate how training over multiple models for the same task (e.g., shape reconstruction) significantly outperforms the vanilla SampleNet in terms of accuracy by not overfitting the sample network to a particular task network. Second, we show how we can train an almost-universal meta-sampler across multiple tasks. This meta-sampler can then be rapidly fine-tuned when applied to different datasets, networks, or even different tasks, thus amortizing the initial cost of training.