 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentOpt v0.1 Technical Report: Client-Side Optimization for LLM-Based Agent
Apr 07, 2026AI agents are increasingly deployed in real-world applications, including systems such as Manus, OpenClaw, and coding agents. Existing research has primarily focused on \emph{server-side} efficiency, proposing methods such as caching, speculative execution, traffic scheduling, and load balancing to reduce the cost of serving agentic workloads. However, as users increasingly construct agents by composing local tools, remote APIs, and diverse models, an equally important optimization problem arises on the client side. Client-side optimization asks how developers should allocate the resources available to them, including model choice, local tools, and API budget across pipeline stages, subject to application-specific quality, cost, and latency constraints. Because these objectives depend on the task and deployment setting, they cannot be determined by server-side systems alone. We introduce AgentOpt, the first framework-agnostic Python package for client-side agent optimization. We first study model selection, a high-impact optimization lever in multi-step agent pipelines. Given a pipeline and a small evaluation set, the goal is to find the most cost-effective assignment of models to pipeline roles. This problem is consequential in practice: at matched accuracy, the cost gap between the best and worst model combinations can reach 13--32$\times$ in our experiments. To efficiently explore the exponentially growing combination space, AgentOpt implements eight search algorithms, including Arm Elimination, Epsilon-LUCB, Threshold Successive Elimination, and Bayesian Optimization. Across four benchmarks, Arm Elimination recovers near-optimal accuracy while reducing evaluation budget by 24--67\% relative to brute-force search on three of four tasks. Code and benchmark results available at https://agentoptimizer.github.io/agentopt/.
Cost-aware Stopping for Bayesian Optimization
Jul 16, 2025In automated machine learning, scientific discovery, and other applications of Bayesian optimization, deciding when to stop evaluating expensive black-box functions is an important practical consideration. While several adaptive stopping rules have been proposed, in the cost-aware setting they lack guarantees ensuring they stop before incurring excessive function evaluation costs. We propose a cost-aware stopping rule for Bayesian optimization that adapts to varying evaluation costs and is free of heuristic tuning. Our rule is grounded in a theoretical connection to state-of-the-art cost-aware acquisition functions, namely the Pandora's Box Gittins Index (PBGI) and log expected improvement per cost. We prove a theoretical guarantee bounding the expected cumulative evaluation cost incurred by our stopping rule when paired with these two acquisition functions. In experiments on synthetic and empirical tasks, including hyperparameter optimization and neural architecture size search, we show that combining our stopping rule with the PBGI acquisition function consistently matches or outperforms other acquisition-function--stopping-rule pairs in terms of cost-adjusted simple regret, a metric capturing trade-offs between solution quality and cumulative evaluation cost.
EditBoard: Towards A Comprehensive Evaluation Benchmark for Text-based Video Editing Models
Sep 15, 2024The rapid development of diffusion models has significantly advanced AI-generated content (AIGC), particularly in Text-to-Image (T2I) and Text-to-Video (T2V) generation. Text-based video editing, leveraging these generative capabilities, has emerged as a promising field, enabling precise modifications to videos based on text prompts. Despite the proliferation of innovative video editing models, there is a conspicuous lack of comprehensive evaluation benchmarks that holistically assess these models' performance across various dimensions. Existing evaluations are limited and inconsistent, typically summarizing overall performance with a single score, which obscures models' effectiveness on individual editing tasks. To address this gap, we propose EditBoard, the first comprehensive evaluation benchmark for text-based video editing models. EditBoard encompasses nine automatic metrics across four dimensions, evaluating models on four task categories and introducing three new metrics to assess fidelity. This task-oriented benchmark facilitates objective evaluation by detailing model performance and providing insights into each model's strengths and weaknesses. By open-sourcing EditBoard, we aim to standardize evaluation and advance the development of robust video editing models.
Training Overhead Ratio: A Practical Reliability Metric for Large Language Model Training Systems
Aug 14, 2024
Large Language Models (LLMs) are revolutionizing the AI industry with their superior capabilities. Training these models requires large-scale GPU clusters and significant computing time, leading to frequent failures that significantly increase training costs. Despite its significance, this field lacks a metric for evaluating reliability. In this work, we introduce a novel reliability metric called \emph{Training Overhead Ratio} (TOR) to evaluate the reliability of fault-tolerant LLM training systems. TOR is defined as the ratio of optimal training time to the observed training time of a system, serving as a practical tool for users to estimate the actual time required to train an LLM on a given system. Furthermore, our investigation identifies the key factor for enhancing reliability and present TOR equations for various types of failures encountered in practice.
Cost-aware Bayesian optimization via the Pandora's Box Gittins index
Jun 28, 2024
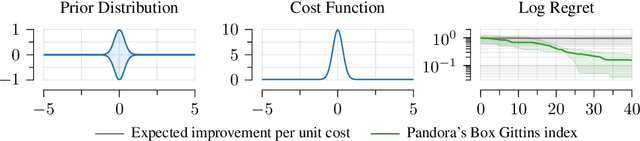
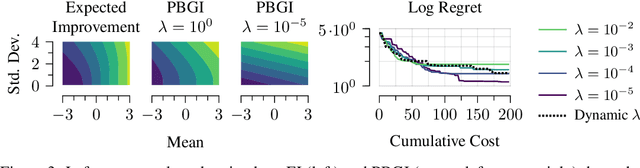
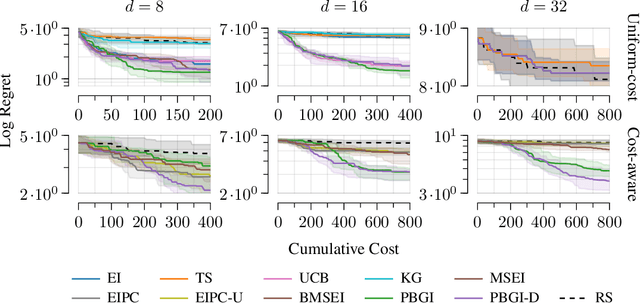
Bayesian optimization is a technique for efficiently optimizing unknown functions in a black-box manner. To handle practical settings where gathering data requires use of finite resources, it is desirable to explicitly incorporate function evaluation costs into Bayesian optimization policies. To understand how to do so, we develop a previously-unexplored connection between cost-aware Bayesian optimization and the Pandora's Box problem, a decision problem from economics. The Pandora's Box problem admits a Bayesian-optimal solution based on an expression called the Gittins index, which can be reinterpreted as an acquisition function. We study the use of this acquisition function for cost-aware Bayesian optimization, and demonstrate empirically that it performs well, particularly in medium-high dimensions. We further show that this performance carries over to classical Bayesian optimization without explicit evaluation costs. Our work constitutes a first step towards integrating techniques from Gittins index theory into Bayesian optimization.
MGDepth: Motion-Guided Cost Volume For Self-Supervised Monocular Depth In Dynamic Scenarios
Dec 23, 2023



Despite advancements in self-supervised monocular depth estimation, challenges persist in dynamic scenarios due to the dependence on assumptions about a static world. In this paper, we present MGDepth, a Motion-Guided Cost Volume Depth Net, to achieve precise depth estimation for both dynamic objects and static backgrounds, all while maintaining computational efficiency. To tackle the challenges posed by dynamic content, we incorporate optical flow and coarse monocular depth to create a novel static reference frame. This frame is then utilized to build a motion-guided cost volume in collaboration with the target frame. Additionally, to enhance the accuracy and resilience of the network structure, we introduce an attention-based depth net architecture to effectively integrate information from feature maps with varying resolutions. Compared to methods with similar computational costs, MGDepth achieves a significant reduction of approximately seven percent in root-mean-square error for self-supervised monocular depth estimation on the KITTI-2015 dataset.
Smooth Non-Stationary Bandits
Jan 29, 2023In many applications of online decision making, the environment is non-stationary and it is therefore crucial to use bandit algorithms that handle changes. Most existing approaches are designed to protect against non-smooth changes, constrained only by total variation or Lipschitzness over time, where they guarantee $T^{2/3}$ regret. However, in practice environments are often changing {\it smoothly}, so such algorithms may incur higher-than-necessary regret in these settings and do not leverage information on the {\it rate of change}. In this paper, we study a non-stationary two-arm bandit problem where we assume an arm's mean reward is a $\beta$-H\"older function over (normalized) time, meaning it is $(\beta-1)$-times Lipschitz-continuously differentiable. We show the first {\it separation} between the smooth and non-smooth regimes by presenting a policy with $T^{3/5}$ regret for $\beta=2$. We complement this result by a $T^{\frac{\beta+1}{2\beta+1}}$ lower bound for any integer $\beta\ge 1$, which matches our upper bound for $\beta=2$.
3DPCT: 3D Point Cloud Transformer with Dual Self-attention
Sep 21, 2022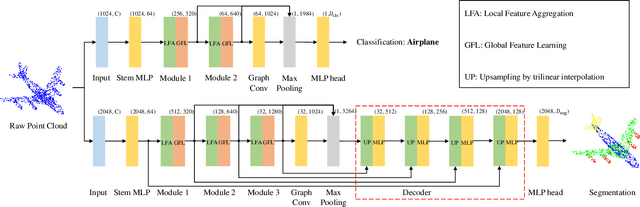
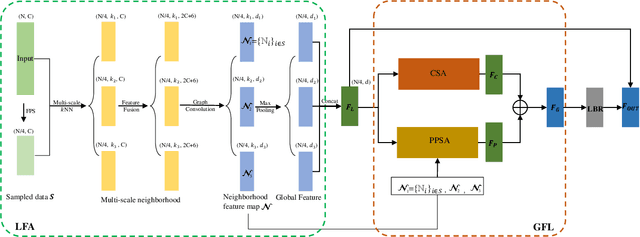
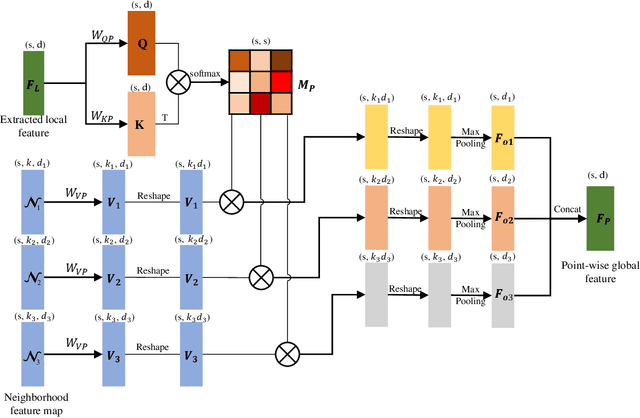
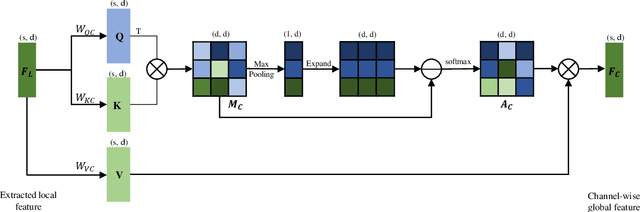
Transformers have resulted in remarkable achievements in the field of image processing. Inspired by this great success, the application of Transformers to 3D point cloud processing has drawn more and more attention. This paper presents a novel point cloud representational learning network, 3D Point Cloud Transformer with Dual Self-attention (3DPCT) and an encoder-decoder structure. Specifically, 3DPCT has a hierarchical encoder, which contains two local-global dual-attention modules for the classification task (three modules for the segmentation task), with each module consisting of a Local Feature Aggregation (LFA) block and a Global Feature Learning (GFL) block. The GFL block is dual self-attention, with both point-wise and channel-wise self-attention to improve feature extraction. Moreover, in LFA, to better leverage the local information extracted, a novel point-wise self-attention model, named as Point-Patch Self-Attention (PPSA), is designed. The performance is evaluated on both classification and segmentation datasets, containing both synthetic and real-world data. Extensive experiments demonstrate that the proposed method achieved state-of-the-art results on both classification and segmentation tasks.
MODNet: Multi-offset Point Cloud Denoising Network Customized for Multi-scale Patches
Sep 01, 2022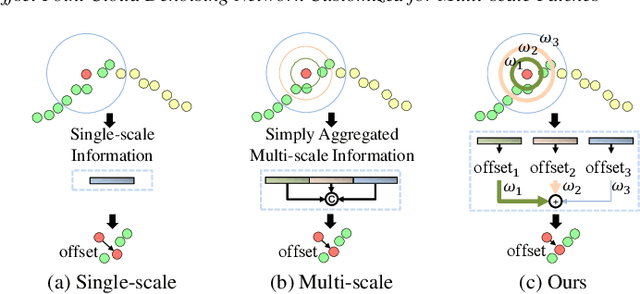
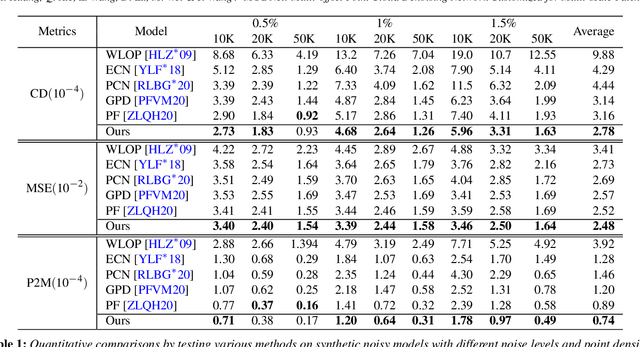
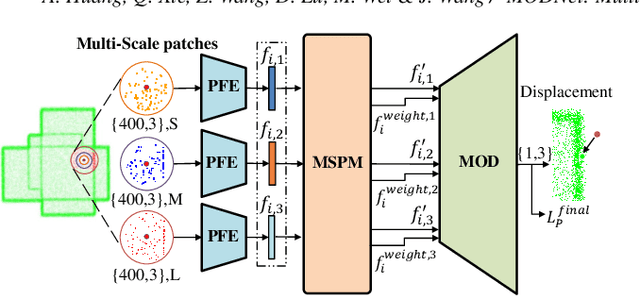
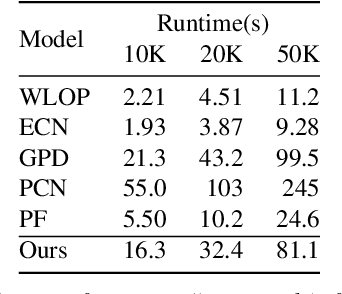
The intricacy of 3D surfaces often results cutting-edge point cloud denoising (PCD) models in surface degradation including remnant noise, wrongly-removed geometric details. Although using multi-scale patches to encode the geometry of a point has become the common wisdom in PCD, we find that simple aggregation of extracted multi-scale features can not adaptively utilize the appropriate scale information according to the geometric information around noisy points. It leads to surface degradation, especially for points close to edges and points on complex curved surfaces. We raise an intriguing question -- if employing multi-scale geometric perception information to guide the network to utilize multi-scale information, can eliminate the severe surface degradation problem? To answer it, we propose a Multi-offset Denoising Network (MODNet) customized for multi-scale patches. First, we extract the low-level feature of three scales patches by patch feature encoders. Second, a multi-scale perception module is designed to embed multi-scale geometric information for each scale feature and regress multi-scale weights to guide a multi-offset denoising displacement. Third, a multi-offset decoder regresses three scale offsets, which are guided by the multi-scale weights to predict the final displacement by weighting them adaptively. Experiments demonstrate that our method achieves new state-of-the-art performance on both synthetic and real-scanned datasets.
Transformers in 3D Point Clouds: A Survey
May 16, 2022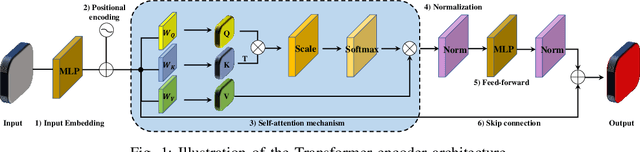
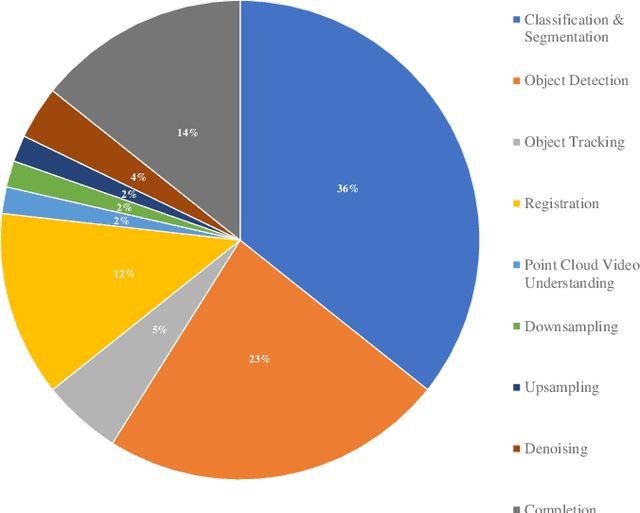
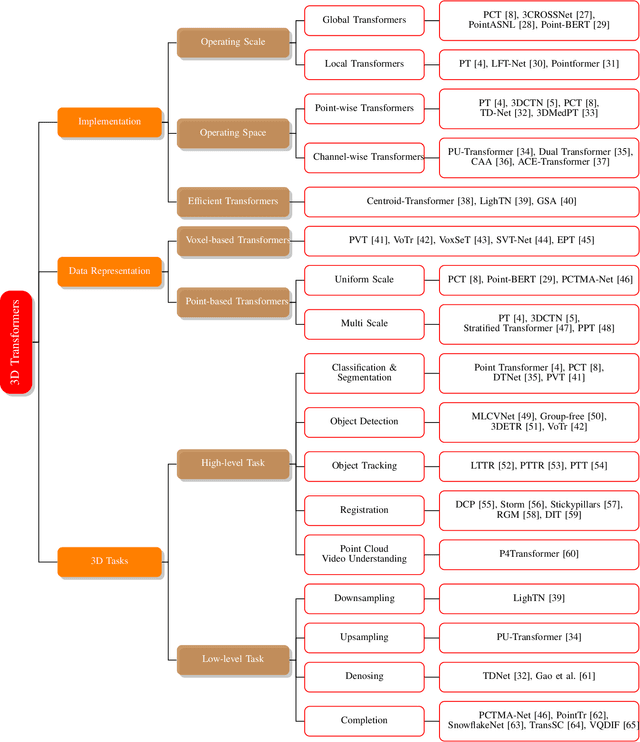
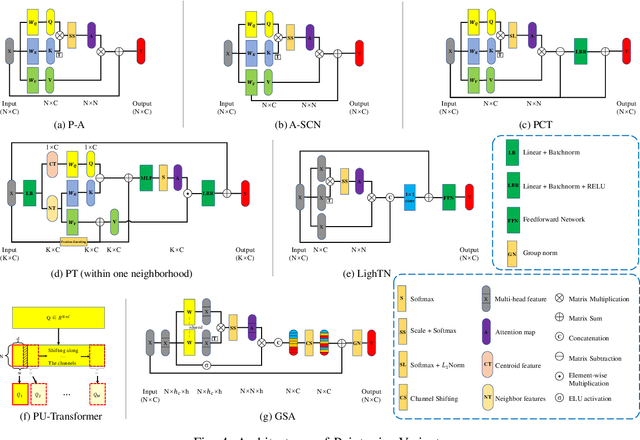
In recent years, Transformer models have been proven to have the remarkable ability of long-range dependencies modeling. They have achieved satisfactory results both in Natural Language Processing (NLP) and image processing. This significant achievement sparks great interest among researchers in 3D point cloud processing to apply them to various 3D tasks. Due to the inherent permutation invariance and strong global feature learning ability, 3D Transformers are well suited for point cloud processing and analysis. They have achieved competitive or even better performance compared to the state-of-the-art non-Transformer algorithms. This survey aims to provide a comprehensive overview of 3D Transformers designed for various tasks (e.g. point cloud classification, segmentation, object detection, and so on). We start by introducing the fundamental components of the general Transformer and providing a brief description of its application in 2D and 3D fields. Then, we present three different taxonomies (i.e., Transformer implementation-based taxonomy, data representation-based taxonomy, and task-based taxonomy) for method classification, which allows us to analyze involved methods from multiple perspectives. Furthermore, we also conduct an investigation of 3D self-attention mechanism variants designed for performance improvement. To demonstrate the superiority of 3D Transformers, we compare the performance of Transformer-based algorithms in terms of point cloud classification, segmentation, and object detection. Finally, we point out three potential future research directions, expecting to provide some benefit references for the development of 3D Transformers.