 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Forest Fuel Load Estimation via Virtual Remote Sensing and Metric-Scale Feed-Forward 3D Reconstruction
May 11, 2026Accurate quantification of forest coverage and combustible biomass (fuel load) is critical for wildfire risk assessment and ecosystem management. However, traditional methods relying on airborne LiDAR or field surveys are cost-prohibitive and time-intensive, while satellite imagery often lacks the vertical resolution required for canopy volume analysis. This paper proposes a novel, automated pipeline for rapid forest inventory using virtual remote sensing data derived from Google Earth Studio (GES). Our approach first generates low-altitude orbital imagery and camera poses for a target region. For dense 3D reconstruction, we employ Pi-Long, developed within the VGGT-Long framework. This model serves as a scalable extension of the Pi-3 feed-forward Transformer architecture. To address the inherent scale ambiguity in monocular reconstruction, we introduce a metric recovery module that aligns the reconstructed trajectory with GES ground truth poses via Sim(3) Umeyama optimization. The metric-scale point cloud is then orthogonally projected into Bird's-Eye-View (BEV) height and density maps. Finally, we employ a watershed-based segmentation algorithm combined with height variance analysis to classify tree species (conifer vs. broadleaf), calculate Leaf Area Index (LAI), and estimate total fuel load. Experimental results demonstrate that this pipeline offers a scalable, cost-effective alternative to physical scanning, enabling near-real-time estimation of forest biomass with high geometric consistency.
KitchenTwin: Semantically and Geometrically Grounded 3D Kitchen Digital Twins
Mar 25, 2026Embodied AI training and evaluation require object-centric digital twin environments with accurate metric geometry and semantic grounding. Recent transformer-based feedforward reconstruction methods can efficiently predict global point clouds from sparse monocular videos, yet these geometries suffer from inherent scale ambiguity and inconsistent coordinate conventions. This mismatch prevents the reliable fusion of these dimensionless point cloud predictions with locally reconstructed object meshes. We propose a novel scale-aware 3D fusion framework that registers visually grounded object meshes with transformer-predicted global point clouds to construct metrically consistent digital twins. Our method introduces a Vision-Language Model (VLM)-guided geometric anchor mechanism that resolves this fundamental coordinate mismatch by recovering an accurate real-world metric scale. To fuse these networks, we propose a geometry-aware registration pipeline that explicitly enforces physical plausibility through gravity-aligned vertical estimation, Manhattan-world structural constraints, and collision-free local refinement. Experiments on real indoor kitchen environments demonstrate improved cross-network object alignment and geometric consistency for downstream tasks, including multi-primitive fitting and metric measurement. We additionally introduce an open-source indoor digital twin dataset with metrically scaled scenes and semantically grounded and registered object-centric mesh annotations.
Sparse Data Tree Canopy Segmentation: Fine-Tuning Leading Pretrained Models on Only 150 Images
Jan 16, 2026Tree canopy detection from aerial imagery is an important task for environmental monitoring, urban planning, and ecosystem analysis. Simulating real-life data annotation scarcity, the Solafune Tree Canopy Detection competition provides a small and imbalanced dataset of only 150 annotated images, posing significant challenges for training deep models without severe overfitting. In this work, we evaluate five representative architectures, YOLOv11, Mask R-CNN, DeepLabv3, Swin-UNet, and DINOv2, to assess their suitability for canopy segmentation under extreme data scarcity. Our experiments show that pretrained convolution-based models, particularly YOLOv11 and Mask R-CNN, generalize significantly better than pretrained transformer-based models. DeeplabV3, Swin-UNet and DINOv2 underperform likely due to differences between semantic and instance segmentation tasks, the high data requirements of Vision Transformers, and the lack of strong inductive biases. These findings confirm that transformer-based architectures struggle in low-data regimes without substantial pretraining or augmentation and that differences between semantic and instance segmentation further affect model performance. We provide a detailed analysis of training strategies, augmentation policies, and model behavior under the small-data constraint and demonstrate that lightweight CNN-based methods remain the most reliable for canopy detection on limited imagery.
Trustworthy Data-Driven Wildfire Risk Prediction and Understanding in Western Canada
Jan 04, 2026In recent decades, the intensification of wildfire activity in western Canada has resulted in substantial socio-economic and environmental losses. Accurate wildfire risk prediction is hindered by the intrinsic stochasticity of ignition and spread and by nonlinear interactions among fuel conditions, meteorology, climate variability, topography, and human activities, challenging the reliability and interpretability of purely data-driven models. We propose a trustworthy data-driven wildfire risk prediction framework based on long-sequence, multi-scale temporal modeling, which integrates heterogeneous drivers while explicitly quantifying predictive uncertainty and enabling process-level interpretation. Evaluated over western Canada during the record-breaking 2023 and 2024 fire seasons, the proposed model outperforms existing time-series approaches, achieving an F1 score of 0.90 and a PR-AUC of 0.98 with low computational cost. Uncertainty-aware analysis reveals structured spatial and seasonal patterns in predictive confidence, highlighting increased uncertainty associated with ambiguous predictions and spatiotemporal decision boundaries. SHAP-based interpretation provides mechanistic understanding of wildfire controls, showing that temperature-related drivers dominate wildfire risk in both years, while moisture-related constraints play a stronger role in shaping spatial and land-cover-specific contrasts in 2024 compared to the widespread hot and dry conditions of 2023. Data and code are available at https://github.com/SynUW/mmFire.
SAGOnline: Segment Any Gaussians Online
Aug 11, 20253D Gaussian Splatting (3DGS) has emerged as a powerful paradigm for explicit 3D scene representation, yet achieving efficient and consistent 3D segmentation remains challenging. Current methods suffer from prohibitive computational costs, limited 3D spatial reasoning, and an inability to track multiple objects simultaneously. We present Segment Any Gaussians Online (SAGOnline), a lightweight and zero-shot framework for real-time 3D segmentation in Gaussian scenes that addresses these limitations through two key innovations: (1) a decoupled strategy that integrates video foundation models (e.g., SAM2) for view-consistent 2D mask propagation across synthesized views; and (2) a GPU-accelerated 3D mask generation and Gaussian-level instance labeling algorithm that assigns unique identifiers to 3D primitives, enabling lossless multi-object tracking and segmentation across views. SAGOnline achieves state-of-the-art performance on NVOS (92.7% mIoU) and Spin-NeRF (95.2% mIoU) benchmarks, outperforming Feature3DGS, OmniSeg3D-gs, and SA3D by 15--1500 times in inference speed (27 ms/frame). Qualitative results demonstrate robust multi-object segmentation and tracking in complex scenes. Our contributions include: (i) a lightweight and zero-shot framework for 3D segmentation in Gaussian scenes, (ii) explicit labeling of Gaussian primitives enabling simultaneous segmentation and tracking, and (iii) the effective adaptation of 2D video foundation models to the 3D domain. This work allows real-time rendering and 3D scene understanding, paving the way for practical AR/VR and robotic applications.
Digital Twin Buildings: 3D Modeling, GIS Integration, and Visual Descriptions Using Gaussian Splatting, ChatGPT/Deepseek, and Google Maps Platforms
Feb 09, 2025Urban digital twins are virtual replicas of cities that use multi-source data and data analytics to optimize urban planning, infrastructure management, and decision-making. Towards this, we propose a framework focused on the single-building scale. By connecting to cloud mapping platforms such as Google Map Platforms APIs, by leveraging state-of-the-art multi-agent Large Language Models data analysis using ChatGPT(4o) and Deepseek-V3/R1, and by using our Gaussian Splatting-based mesh extraction pipeline, our Digital Twin Buildings framework can retrieve a building's 3D model, visual descriptions, and achieve cloud-based mapping integration with large language model-based data analytics using a building's address, postal code, or geographic coordinates.
Gaussian Building Mesh (GBM): Extract a Building's 3D Mesh with Google Earth and Gaussian Splatting
Jan 07, 2025



Recently released open-source pre-trained foundational image segmentation and object detection models (SAM2+GroundingDINO) allow for geometrically consistent segmentation of objects of interest in multi-view 2D images. Users can use text-based or click-based prompts to segment objects of interest without requiring labeled training datasets. Gaussian Splatting allows for the learning of the 3D representation of a scene's geometry and radiance based on 2D images. Combining Google Earth Studio, SAM2+GroundingDINO, 2D Gaussian Splatting, and our improvements in mask refinement based on morphological operations and contour simplification, we created a pipeline to extract the 3D mesh of any building based on its name, address, or geographic coordinates.
Advancements in Road Lane Mapping: Comparative Fine-Tuning Analysis of Deep Learning-based Semantic Segmentation Methods Using Aerial Imagery
Oct 08, 2024

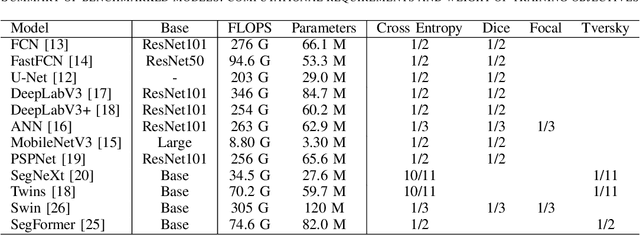
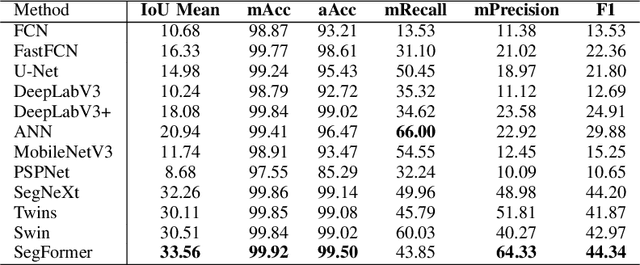
This research addresses the need for high-definition (HD) maps for autonomous vehicles (AVs), focusing on road lane information derived from aerial imagery. While Earth observation data offers valuable resources for map creation, specialized models for road lane extraction are still underdeveloped in remote sensing. In this study, we perform an extensive comparison of twelve foundational deep learning-based semantic segmentation models for road lane marking extraction from high-definition remote sensing images, assessing their performance under transfer learning with partially labeled datasets. These models were fine-tuned on the partially labeled Waterloo Urban Scene dataset, and pre-trained on the SkyScapes dataset, simulating a likely scenario of real-life model deployment under partial labeling. We observed and assessed the fine-tuning performance and overall performance. Models showed significant performance improvements after fine-tuning, with mean IoU scores ranging from 33.56% to 76.11%, and recall ranging from 66.0% to 98.96%. Transformer-based models outperformed convolutional neural networks, emphasizing the importance of model pre-training and fine-tuning in enhancing HD map development for AV navigation.
L4DR: LiDAR-4DRadar Fusion for Weather-Robust 3D Object Detection
Aug 07, 2024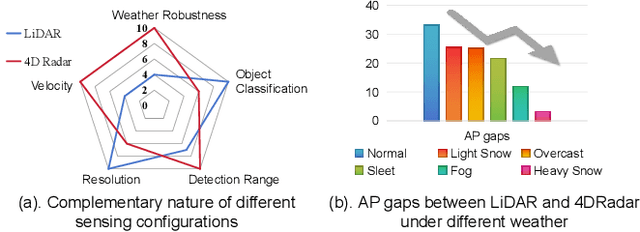
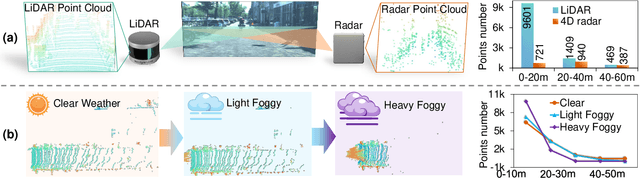
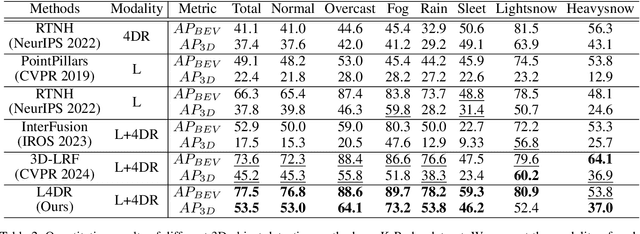
LiDAR-based vision systems are integral for 3D object detection, which is crucial for autonomous navigation. However, they suffer from performance degradation in adverse weather conditions due to the quality deterioration of LiDAR point clouds. Fusing LiDAR with the weather-robust 4D radar sensor is expected to solve this problem. However, the fusion of LiDAR and 4D radar is challenging because they differ significantly in terms of data quality and the degree of degradation in adverse weather. To address these issues, we introduce L4DR, a weather-robust 3D object detection method that effectively achieves LiDAR and 4D Radar fusion. Our L4DR includes Multi-Modal Encoding (MME) and Foreground-Aware Denoising (FAD) technique to reconcile sensor gaps, which is the first exploration of the complementarity of early fusion between LiDAR and 4D radar. Additionally, we design an Inter-Modal and Intra-Modal ({IM}2 ) parallel feature extraction backbone coupled with a Multi-Scale Gated Fusion (MSGF) module to counteract the varying degrees of sensor degradation under adverse weather conditions. Experimental evaluation on a VoD dataset with simulated fog proves that L4DR is more adaptable to changing weather conditions. It delivers a significant performance increase under different fog levels, improving the 3D mAP by up to 18.17% over the traditional LiDAR-only approach. Moreover, the results on the K-Radar dataset validate the consistent performance improvement of L4DR in real-world adverse weather conditions.
3D Learnable Supertoken Transformer for LiDAR Point Cloud Scene Segmentation
May 23, 2024



3D Transformers have achieved great success in point cloud understanding and representation. However, there is still considerable scope for further development in effective and efficient Transformers for large-scale LiDAR point cloud scene segmentation. This paper proposes a novel 3D Transformer framework, named 3D Learnable Supertoken Transformer (3DLST). The key contributions are summarized as follows. Firstly, we introduce the first Dynamic Supertoken Optimization (DSO) block for efficient token clustering and aggregating, where the learnable supertoken definition avoids the time-consuming pre-processing of traditional superpoint generation. Since the learnable supertokens can be dynamically optimized by multi-level deep features during network learning, they are tailored to the semantic homogeneity-aware token clustering. Secondly, an efficient Cross-Attention-guided Upsampling (CAU) block is proposed for token reconstruction from optimized supertokens. Thirdly, the 3DLST is equipped with a novel W-net architecture instead of the common U-net design, which is more suitable for Transformer-based feature learning. The SOTA performance on three challenging LiDAR datasets (airborne MultiSpectral LiDAR (MS-LiDAR) (89.3% of the average F1 score), DALES (80.2% of mIoU), and Toronto-3D dataset (80.4% of mIoU)) demonstrate the superiority of 3DLST and its strong adaptability to various LiDAR point cloud data (airborne MS-LiDAR, aerial LiDAR, and vehicle-mounted LiDAR data). Furthermore, 3DLST also achieves satisfactory results in terms of algorithm efficiency, which is up to 5x faster than previous best-performing methods.