 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2VLoc: Robust GNSS-Free Collaborative Perception via LiDAR Localization
Nov 18, 2025


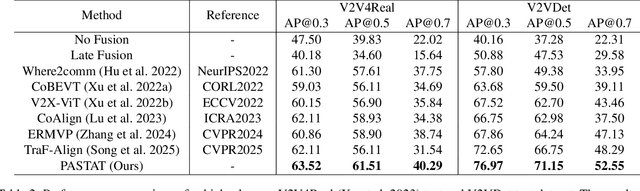
Multi-agents rely on accurate poses to share and align observations, enabling a collaborative perception of the environment. However, traditional GNSS-based localization often fails in GNSS-denied environments, making consistent feature alignment difficult in collaboration. To tackle this challenge, we propose a robust GNSS-free collaborative perception framework based on LiDAR localization. Specifically, we propose a lightweight Pose Generator with Confidence (PGC) to estimate compact pose and confidence representations. To alleviate the effects of localization errors, we further develop the Pose-Aware Spatio-Temporal Alignment Transformer (PASTAT), which performs confidence-aware spatial alignment while capturing essential temporal context. Additionally, we present a new simulation dataset, V2VLoc, which can be adapted for both LiDAR localization and collaborative detection tasks. V2VLoc comprises three subsets: Town1Loc, Town4Loc, and V2VDet. Town1Loc and Town4Loc offer multi-traversal sequences for training in localization tasks, whereas V2VDet is specifically intended for the collaborative detection task. Extensive experiments conducted on the V2VLoc dataset demonstrate that our approach achieves state-of-the-art performance under GNSS-denied conditions. We further conduct extended experiments on the real-world V2V4Real dataset to validate the effectiveness and generalizability of PASTAT.
WinMamba: Multi-Scale Shifted Windows in State Space Model for 3D Object Detection
Nov 17, 2025



3D object detection is critical for autonomous driving, yet it remains fundamentally challenging to simultaneously maximize computational efficiency and capture long-range spatial dependencies. We observed that Mamba-based models, with their linear state-space design, capture long-range dependencies at lower cost, offering a promising balance between efficiency and accuracy. However, existing methods rely on axis-aligned scanning within a fixed window, inevitably discarding spatial information. To address this problem, we propose WinMamba, a novel Mamba-based 3D feature-encoding backbone composed of stacked WinMamba blocks. To enhance the backbone with robust multi-scale representation, the WinMamba block incorporates a window-scale-adaptive module that compensates voxel features across varying resolutions during sampling. Meanwhile, to obtain rich contextual cues within the linear state space, we equip the WinMamba layer with a learnable positional encoding and a window-shift strategy. Extensive experiments on the KITTI and Waymo datasets demonstrate that WinMamba significantly outperforms the baseline. Ablation studies further validate the individual contributions of the WSF and AWF modules in improving detection accuracy. The code will be made publicly available.
DGFusion: Dual-guided Fusion for Robust Multi-Modal 3D Object Detection
Nov 13, 2025As a critical task in autonomous driving perception systems, 3D object detection is used to identify and track key objects, such as vehicles and pedestrians. However, detecting distant, small, or occluded objects (hard instances) remains a challenge, which directly compromises the safety of autonomous driving systems. We observe that existing multi-modal 3D object detection methods often follow a single-guided paradigm, failing to account for the differences in information density of hard instances between modalities. In this work, we propose DGFusion, based on the Dual-guided paradigm, which fully inherits the advantages of the Point-guide-Image paradigm and integrates the Image-guide-Point paradigm to address the limitations of the single paradigms. The core of DGFusion, the Difficulty-aware Instance Pair Matcher (DIPM), performs instance-level feature matching based on difficulty to generate easy and hard instance pairs, while the Dual-guided Modules exploit the advantages of both pair types to enable effective multi-modal feature fusion. Experimental results demonstrate that our DGFusion outperforms the baseline methods, with respective improvements of +1.0\% mAP, +0.8\% NDS, and +1.3\% average recall on nuScenes. Extensive experiments demonstrate consistent robustness gains for hard instance detection across ego-distance, size, visibility, and small-scale training scenarios.
Seg2Box: 3D Object Detection by Point-Wise Semantics Supervision
Mar 21, 2025
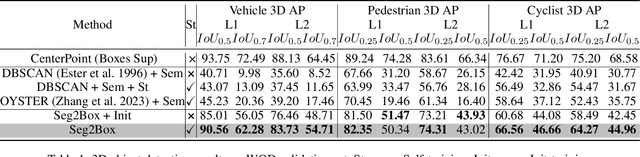
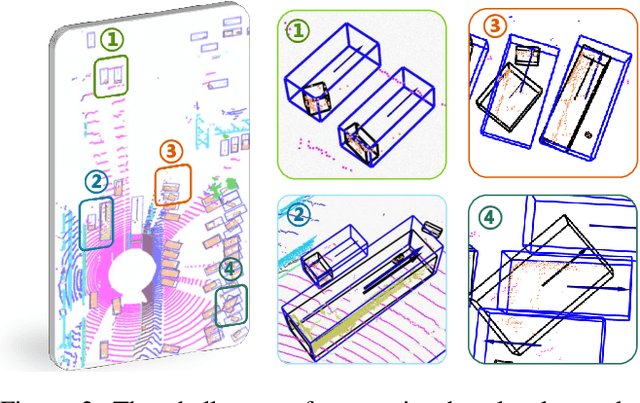
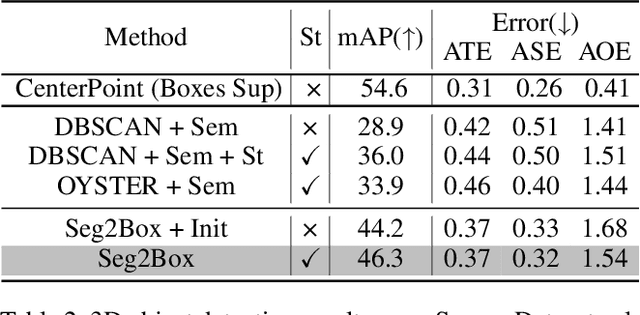
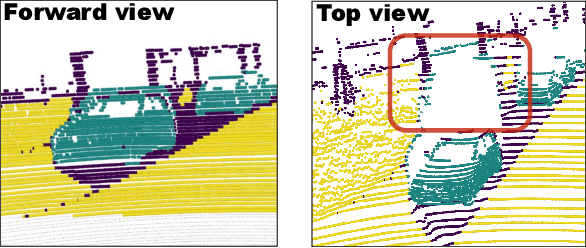
LiDAR-based 3D object detection and semantic segmentation are critical tasks in 3D scene understanding. Traditional detection and segmentation methods supervise their models through bounding box labels and semantic mask labels. However, these two independent labels inherently contain significant redundancy. This paper aims to eliminate the redundancy by supervising 3D object detection using only semantic labels. However, the challenge arises due to the incomplete geometry structure and boundary ambiguity of point-cloud instances, leading to inaccurate pseudo labels and poor detection results. To address these challenges, we propose a novel method, named Seg2Box. We first introduce a Multi-Frame Multi-Scale Clustering (MFMS-C) module, which leverages the spatio-temporal consistency of point clouds to generate accurate box-level pseudo-labels. Additionally, the Semantic?Guiding Iterative-Mining Self-Training (SGIM-ST) module is proposed to enhance the performance by progressively refining the pseudo-labels and mining the instances without generating pseudo-labels. Experiments on the Waymo Open Dataset and nuScenes Dataset show that our method significantly outperforms other competitive methods by 23.7\% and 10.3\% in mAP, respectively. The results demonstrate the great label-efficient potential and advancement of our method.
Learning to Detect Objects from Multi-Agent LiDAR Scans without Manual Labels
Mar 13, 2025Unsupervised 3D object detection serves as an important solution for offline 3D object annotation. However, due to the data sparsity and limited views, the clustering-based label fitting in unsupervised object detection often generates low-quality pseudo-labels. Multi-agent collaborative dataset, which involves the sharing of complementary observations among agents, holds the potential to break through this bottleneck. In this paper, we introduce a novel unsupervised method that learns to Detect Objects from Multi-Agent LiDAR scans, termed DOtA, without using labels from external. DOtA first uses the internally shared ego-pose and ego-shape of collaborative agents to initialize the detector, leveraging the generalization performance of neural networks to infer preliminary labels. Subsequently,DOtA uses the complementary observations between agents to perform multi-scale encoding on preliminary labels, then decodes high-quality and low-quality labels. These labels are further used as prompts to guide a correct feature learning process, thereby enhancing the performance of the unsupervised object detection task. Extensive experiments on the V2V4Real and OPV2V datasets show that our DOtA outperforms state-of-the-art unsupervised 3D object detection methods. Additionally, we also validate the effectiveness of the DOtA labels under various collaborative perception frameworks.The code is available at https://github.com/xmuqimingxia/DOtA.
SP3D: Boosting Sparsely-Supervised 3D Object Detection via Accurate Cross-Modal Semantic Prompts
Mar 09, 2025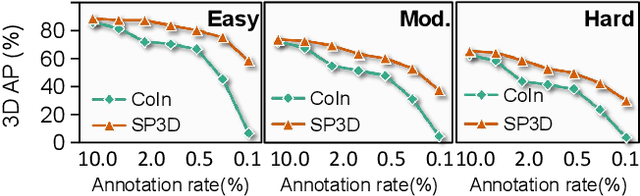
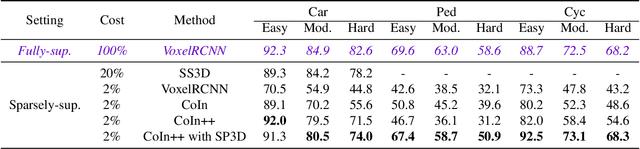
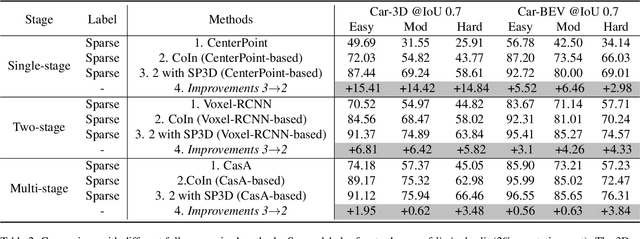
Recently, sparsely-supervised 3D object detection has gained great attention, achieving performance close to fully-supervised 3D objectors while requiring only a few annotated instances. Nevertheless, these methods suffer challenges when accurate labels are extremely absent. In this paper, we propose a boosting strategy, termed SP3D, explicitly utilizing the cross-modal semantic prompts generated from Large Multimodal Models (LMMs) to boost the 3D detector with robust feature discrimination capability under sparse annotation settings. Specifically, we first develop a Confident Points Semantic Transfer (CPST) module that generates accurate cross-modal semantic prompts through boundary-constrained center cluster selection. Based on these accurate semantic prompts, which we treat as seed points, we introduce a Dynamic Cluster Pseudo-label Generation (DCPG) module to yield pseudo-supervision signals from the geometry shape of multi-scale neighbor points. Additionally, we design a Distribution Shape score (DS score) that chooses high-quality supervision signals for the initial training of the 3D detector. Experiments on the KITTI dataset and Waymo Open Dataset (WOD) have validated that SP3D can enhance the performance of sparsely supervised detectors by a large margin under meager labeling conditions. Moreover, we verified SP3D in the zero-shot setting, where its performance exceeded that of the state-of-the-art methods. The code is available at https://github.com/xmuqimingxia/SP3D.
AdaCo: Overcoming Visual Foundation Model Noise in 3D Semantic Segmentation via Adaptive Label Correction
Dec 24, 2024



Recently, Visual Foundation Models (VFMs) have shown a remarkable generalization performance in 3D perception tasks. However, their effectiveness in large-scale outdoor datasets remains constrained by the scarcity of accurate supervision signals, the extensive noise caused by variable outdoor conditions, and the abundance of unknown objects. In this work, we propose a novel label-free learning method, Adaptive Label Correction (AdaCo), for 3D semantic segmentation. AdaCo first introduces the Cross-modal Label Generation Module (CLGM), providing cross-modal supervision with the formidable interpretive capabilities of the VFMs. Subsequently, AdaCo incorporates the Adaptive Noise Corrector (ANC), updating and adjusting the noisy samples within this supervision iteratively during training. Moreover, we develop an Adaptive Robust Loss (ARL) function to modulate each sample's sensitivity to noisy supervision, preventing potential underfitting issues associated with robust loss. Our proposed AdaCo can effectively mitigate the performance limitations of label-free learning networks in 3D semantic segmentation tasks. Extensive experiments on two outdoor benchmark datasets highlight the superior performance of our method.
V2X-R: Cooperative LiDAR-4D Radar Fusion for 3D Object Detection with Denoising Diffusion
Nov 13, 2024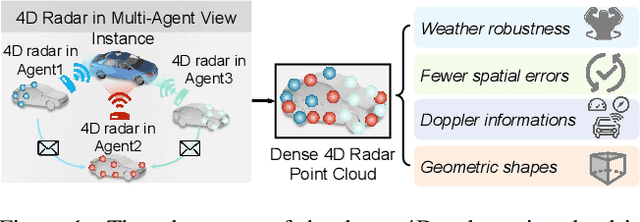

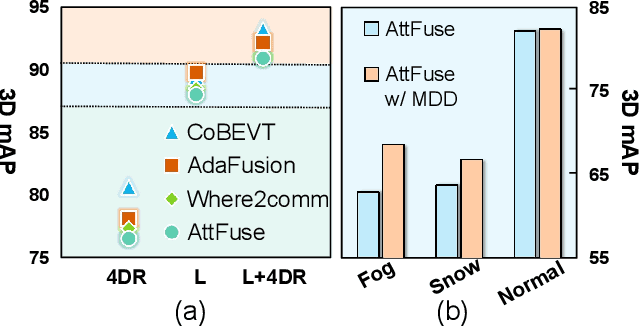

Current Vehicle-to-Everything (V2X) systems have significantly enhanced 3D object detection using LiDAR and camera data. However, these methods suffer from performance degradation in adverse weather conditions. The weatherrobust 4D radar provides Doppler and additional geometric information, raising the possibility of addressing this challenge. To this end, we present V2X-R, the first simulated V2X dataset incorporating LiDAR, camera, and 4D radar. V2X-R contains 12,079 scenarios with 37,727 frames of LiDAR and 4D radar point clouds, 150,908 images, and 170,859 annotated 3D vehicle bounding boxes. Subsequently, we propose a novel cooperative LiDAR-4D radar fusion pipeline for 3D object detection and implement it with various fusion strategies. To achieve weather-robust detection, we additionally propose a Multi-modal Denoising Diffusion (MDD) module in our fusion pipeline. MDD utilizes weather-robust 4D radar feature as a condition to prompt the diffusion model to denoise noisy LiDAR features. Experiments show that our LiDAR-4D radar fusion pipeline demonstrates superior performance in the V2X-R dataset. Over and above this, our MDD module further improved the performance of basic fusion model by up to 5.73%/6.70% in foggy/snowy conditions with barely disrupting normal performance. The dataset and code will be publicly available at: https://github.com/ylwhxht/V2X-R.
OC3D: Weakly Supervised Outdoor 3D Object Detection with Only Coarse Click Annotation
Aug 15, 2024



LiDAR-based outdoor 3D object detection has received widespread attention. However, training 3D detectors from the LiDAR point cloud typically relies on expensive bounding box annotations. This paper presents OC3D, an innovative weakly supervised method requiring only coarse clicks on the bird' s eye view of the 3D point cloud. A key challenge here is the absence of complete geometric descriptions of the target objects from such simple click annotations. To address this problem, our proposed OC3D adopts a two-stage strategy. In the first stage, we initially design a novel dynamic and static classification strategy and then propose the Click2Box and Click2Mask modules to generate box-level and mask-level pseudo-labels for static and dynamic instances, respectively. In the second stage, we design a Mask2Box module, leveraging the learning capabilities of neural networks to update mask-level pseudo-labels, which contain less information, to box level pseudo-labels. Experimental results on the widely used KITTI and nuScenes datasets demonstrate that our OC3D with only coarse clicks achieves state-of-the-art performance compared to weakly-supervised 3D detection methods. Combining OC3D with a missing click mining strategy, we propose a OC3D++ pipeline, which requires only 0.2% annotation cost in the KITTI dataset to achieve performance comparable to fully supervised methods.
L4DR: LiDAR-4DRadar Fusion for Weather-Robust 3D Object Detection
Aug 07, 2024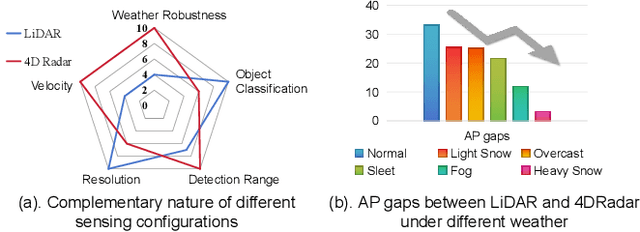
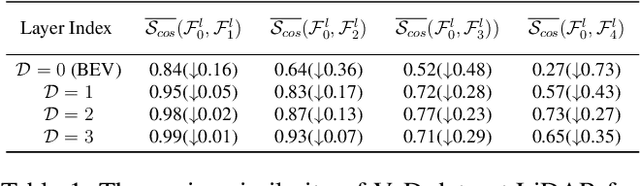
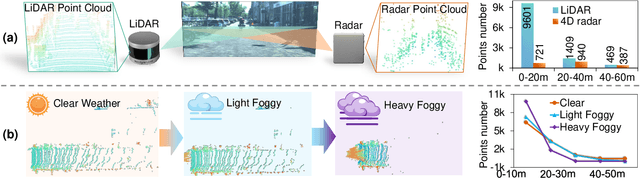
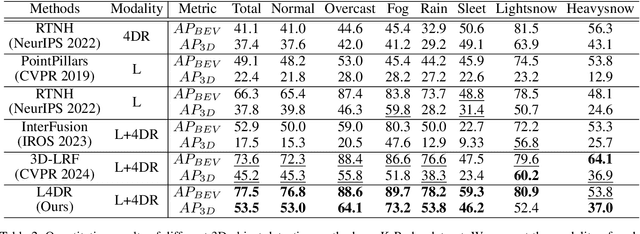
LiDAR-based vision systems are integral for 3D object detection, which is crucial for autonomous navigation. However, they suffer from performance degradation in adverse weather conditions due to the quality deterioration of LiDAR point clouds. Fusing LiDAR with the weather-robust 4D radar sensor is expected to solve this problem. However, the fusion of LiDAR and 4D radar is challenging because they differ significantly in terms of data quality and the degree of degradation in adverse weather. To address these issues, we introduce L4DR, a weather-robust 3D object detection method that effectively achieves LiDAR and 4D Radar fusion. Our L4DR includes Multi-Modal Encoding (MME) and Foreground-Aware Denoising (FAD) technique to reconcile sensor gaps, which is the first exploration of the complementarity of early fusion between LiDAR and 4D radar. Additionally, we design an Inter-Modal and Intra-Modal ({IM}2 ) parallel feature extraction backbone coupled with a Multi-Scale Gated Fusion (MSGF) module to counteract the varying degrees of sensor degradation under adverse weather conditions. Experimental evaluation on a VoD dataset with simulated fog proves that L4DR is more adaptable to changing weather conditions. It delivers a significant performance increase under different fog levels, improving the 3D mAP by up to 18.17% over the traditional LiDAR-only approach. Moreover, the results on the K-Radar dataset validate the consistent performance improvement of L4DR in real-world adverse weather conditions.