 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSGNav: Unleashing the Power of Multi-modal 3D Scene Graph for Zero-Shot Embodied Navigation
Nov 14, 2025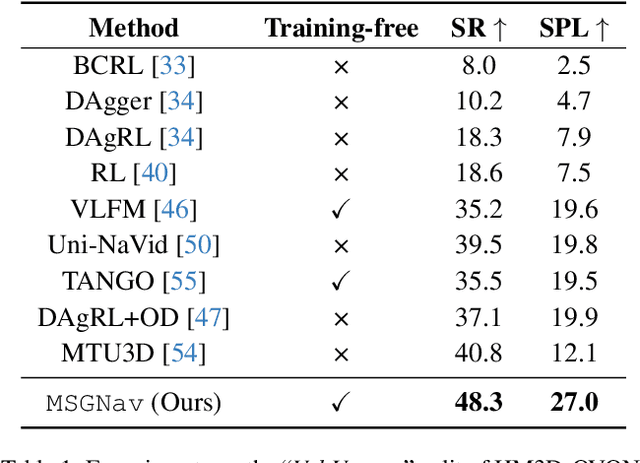
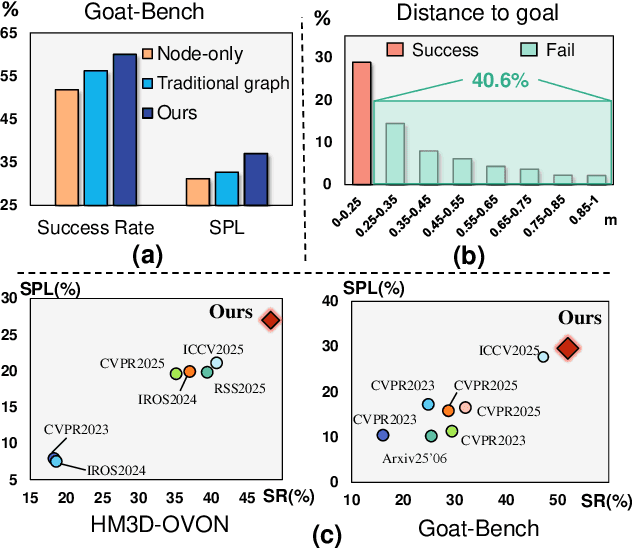
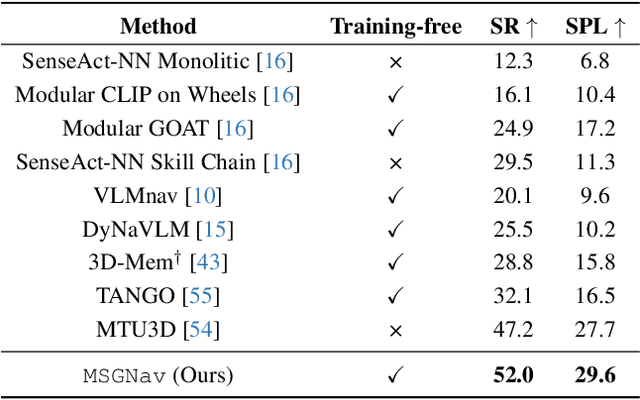
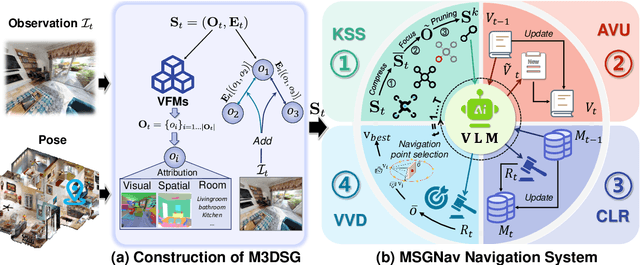
Embodied navigation is a fundamental capability for robotic agents operating. Real-world deployment requires open vocabulary generalization and low training overhead, motivating zero-shot methods rather than task-specific RL training. However, existing zero-shot methods that build explicit 3D scene graphs often compress rich visual observations into text-only relations, leading to high construction cost, irreversible loss of visual evidence, and constrained vocabularies. To address these limitations, we introduce the Multi-modal 3D Scene Graph (M3DSG), which preserves visual cues by replacing textual relation
Seedream 3.0 Technical Report
Apr 16, 2025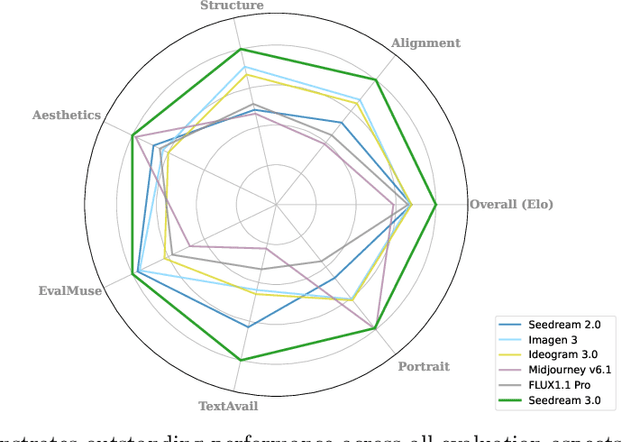


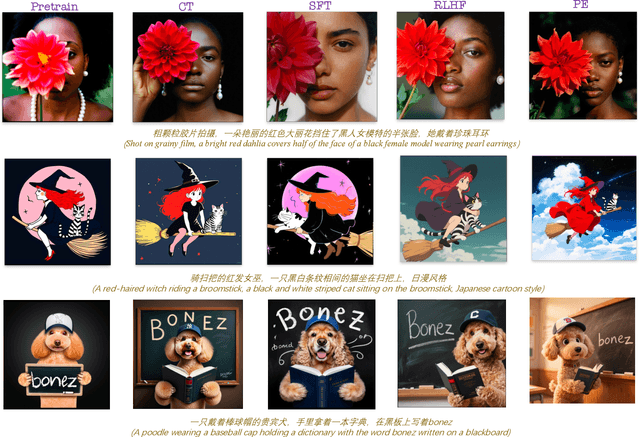
We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions. Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework. Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase. During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences. Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality. Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, in particular for text-rendering in complicated Chinese characters which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Mar 10, 2025Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
SP3D: Boosting Sparsely-Supervised 3D Object Detection via Accurate Cross-Modal Semantic Prompts
Mar 09, 2025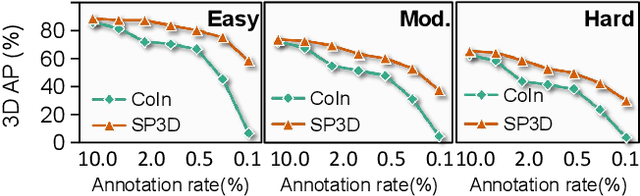
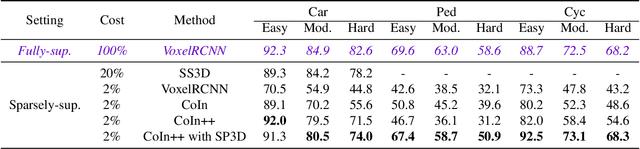
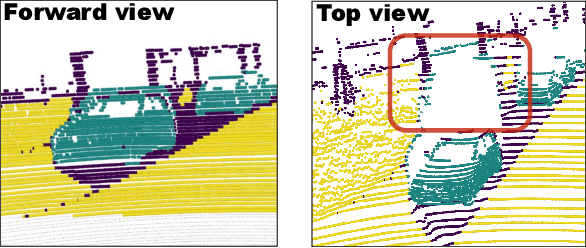
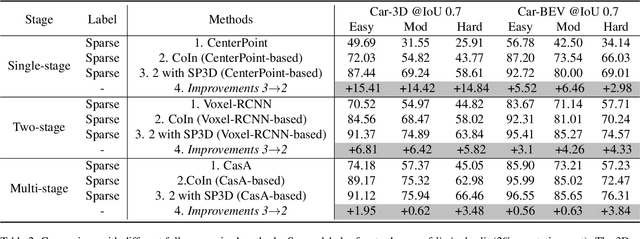
Recently, sparsely-supervised 3D object detection has gained great attention, achieving performance close to fully-supervised 3D objectors while requiring only a few annotated instances. Nevertheless, these methods suffer challenges when accurate labels are extremely absent. In this paper, we propose a boosting strategy, termed SP3D, explicitly utilizing the cross-modal semantic prompts generated from Large Multimodal Models (LMMs) to boost the 3D detector with robust feature discrimination capability under sparse annotation settings. Specifically, we first develop a Confident Points Semantic Transfer (CPST) module that generates accurate cross-modal semantic prompts through boundary-constrained center cluster selection. Based on these accurate semantic prompts, which we treat as seed points, we introduce a Dynamic Cluster Pseudo-label Generation (DCPG) module to yield pseudo-supervision signals from the geometry shape of multi-scale neighbor points. Additionally, we design a Distribution Shape score (DS score) that chooses high-quality supervision signals for the initial training of the 3D detector. Experiments on the KITTI dataset and Waymo Open Dataset (WOD) have validated that SP3D can enhance the performance of sparsely supervised detectors by a large margin under meager labeling conditions. Moreover, we verified SP3D in the zero-shot setting, where its performance exceeded that of the state-of-the-art methods. The code is available at https://github.com/xmuqimingxia/SP3D.
AdaCo: Overcoming Visual Foundation Model Noise in 3D Semantic Segmentation via Adaptive Label Correction
Dec 24, 2024



Recently, Visual Foundation Models (VFMs) have shown a remarkable generalization performance in 3D perception tasks. However, their effectiveness in large-scale outdoor datasets remains constrained by the scarcity of accurate supervision signals, the extensive noise caused by variable outdoor conditions, and the abundance of unknown objects. In this work, we propose a novel label-free learning method, Adaptive Label Correction (AdaCo), for 3D semantic segmentation. AdaCo first introduces the Cross-modal Label Generation Module (CLGM), providing cross-modal supervision with the formidable interpretive capabilities of the VFMs. Subsequently, AdaCo incorporates the Adaptive Noise Corrector (ANC), updating and adjusting the noisy samples within this supervision iteratively during training. Moreover, we develop an Adaptive Robust Loss (ARL) function to modulate each sample's sensitivity to noisy supervision, preventing potential underfitting issues associated with robust loss. Our proposed AdaCo can effectively mitigate the performance limitations of label-free learning networks in 3D semantic segmentation tasks. Extensive experiments on two outdoor benchmark datasets highlight the superior performance of our method.
OC3D: Weakly Supervised Outdoor 3D Object Detection with Only Coarse Click Annotation
Aug 15, 2024



LiDAR-based outdoor 3D object detection has received widespread attention. However, training 3D detectors from the LiDAR point cloud typically relies on expensive bounding box annotations. This paper presents OC3D, an innovative weakly supervised method requiring only coarse clicks on the bird' s eye view of the 3D point cloud. A key challenge here is the absence of complete geometric descriptions of the target objects from such simple click annotations. To address this problem, our proposed OC3D adopts a two-stage strategy. In the first stage, we initially design a novel dynamic and static classification strategy and then propose the Click2Box and Click2Mask modules to generate box-level and mask-level pseudo-labels for static and dynamic instances, respectively. In the second stage, we design a Mask2Box module, leveraging the learning capabilities of neural networks to update mask-level pseudo-labels, which contain less information, to box level pseudo-labels. Experimental results on the widely used KITTI and nuScenes datasets demonstrate that our OC3D with only coarse clicks achieves state-of-the-art performance compared to weakly-supervised 3D detection methods. Combining OC3D with a missing click mining strategy, we propose a OC3D++ pipeline, which requires only 0.2% annotation cost in the KITTI dataset to achieve performance comparable to fully supervised methods.
Commonsense Prototype for Outdoor Unsupervised 3D Object Detection
Apr 25, 2024



The prevalent approaches of unsupervised 3D object detection follow cluster-based pseudo-label generation and iterative self-training processes. However, the challenge arises due to the sparsity of LiDAR scans, which leads to pseudo-labels with erroneous size and position, resulting in subpar detection performance. To tackle this problem, this paper introduces a Commonsense Prototype-based Detector, termed CPD, for unsupervised 3D object detection. CPD first constructs Commonsense Prototype (CProto) characterized by high-quality bounding box and dense points, based on commonsense intuition. Subsequently, CPD refines the low-quality pseudo-labels by leveraging the size prior from CProto. Furthermore, CPD enhances the detection accuracy of sparsely scanned objects by the geometric knowledge from CProto. CPD outperforms state-of-the-art unsupervised 3D detectors on Waymo Open Dataset (WOD), PandaSet, and KITTI datasets by a large margin. Besides, by training CPD on WOD and testing on KITTI, CPD attains 90.85% and 81.01% 3D Average Precision on easy and moderate car classes, respectively. These achievements position CPD in close proximity to fully supervised detectors, highlighting the significance of our method. The code will be available at https://github.com/hailanyi/CPD.