 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCP Loss: Channel-wise Perceptual Loss for Time Series Forecasting
Jan 25, 2026Multi-channel time-series data, prevalent across diverse applications, is characterized by significant heterogeneity in its different channels. However, existing forecasting models are typically guided by channel-agnostic loss functions like MSE, which apply a uniform metric across all channels. This often leads to fail to capture channel-specific dynamics such as sharp fluctuations or trend shifts. To address this, we propose a Channel-wise Perceptual Loss (CP Loss). Its core idea is to learn a unique perceptual space for each channel that is adapted to its characteristics, and to compute the loss within this space. Specifically, we first design a learnable channel-wise filter that decomposes the raw signal into disentangled multi-scale representations, which form the basis of our perceptual space. Crucially, the filter is optimized jointly with the main forecasting model, ensuring that the learned perceptual space is explicitly oriented towards the prediction task. Finally, losses are calculated within these perception spaces to optimize the model. Code is available at https://github.com/zyh16143998882/CP_Loss.
MoniRefer: A Real-world Large-scale Multi-modal Dataset based on Roadside Infrastructure for 3D Visual Grounding
Dec 31, 20253D visual grounding aims to localize the object in 3D point cloud scenes that semantically corresponds to given natural language sentences. It is very critical for roadside infrastructure system to interpret natural languages and localize relevant target objects in complex traffic environments. However, most existing datasets and approaches for 3D visual grounding focus on the indoor and outdoor driving scenes, outdoor monitoring scenarios remain unexplored due to scarcity of paired point cloud-text data captured by roadside infrastructure sensors. In this paper, we introduce a novel task of 3D Visual Grounding for Outdoor Monitoring Scenarios, which enables infrastructure-level understanding of traffic scenes beyond the ego-vehicle perspective. To support this task, we construct MoniRefer, the first real-world large-scale multi-modal dataset for roadside-level 3D visual grounding. The dataset consists of about 136,018 objects with 411,128 natural language expressions collected from multiple complex traffic intersections in the real-world environments. To ensure the quality and accuracy of the dataset, we manually verified all linguistic descriptions and 3D labels for objects. Additionally, we also propose a new end-to-end method, named Moni3DVG, which utilizes the rich appearance information provided by images and geometry and optical information from point cloud for multi-modal feature learning and 3D object localization. Extensive experiments and ablation studies on the proposed benchmarks demonstrate the superiority and effectiveness of our method. Our dataset and code will be released.
Seg2Box: 3D Object Detection by Point-Wise Semantics Supervision
Mar 21, 2025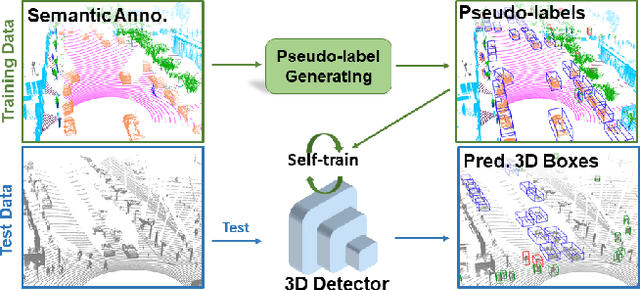
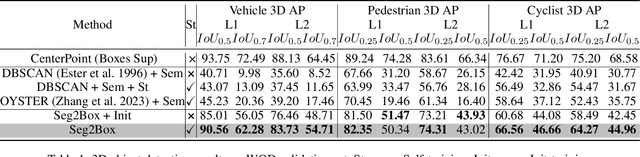
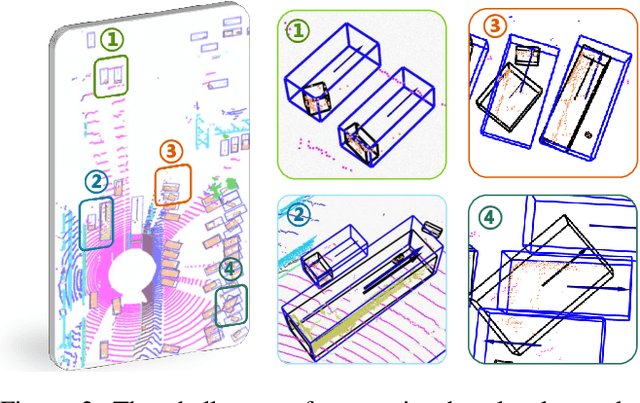
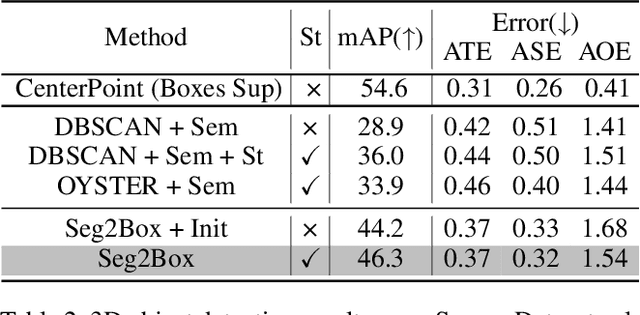
LiDAR-based 3D object detection and semantic segmentation are critical tasks in 3D scene understanding. Traditional detection and segmentation methods supervise their models through bounding box labels and semantic mask labels. However, these two independent labels inherently contain significant redundancy. This paper aims to eliminate the redundancy by supervising 3D object detection using only semantic labels. However, the challenge arises due to the incomplete geometry structure and boundary ambiguity of point-cloud instances, leading to inaccurate pseudo labels and poor detection results. To address these challenges, we propose a novel method, named Seg2Box. We first introduce a Multi-Frame Multi-Scale Clustering (MFMS-C) module, which leverages the spatio-temporal consistency of point clouds to generate accurate box-level pseudo-labels. Additionally, the Semantic?Guiding Iterative-Mining Self-Training (SGIM-ST) module is proposed to enhance the performance by progressively refining the pseudo-labels and mining the instances without generating pseudo-labels. Experiments on the Waymo Open Dataset and nuScenes Dataset show that our method significantly outperforms other competitive methods by 23.7\% and 10.3\% in mAP, respectively. The results demonstrate the great label-efficient potential and advancement of our method.
Optimal Expert Selection for Distributed Mixture-of-Experts at the Wireless Edge
Mar 17, 2025



The emergence of distributed Mixture-of-Experts (DMoE) systems, which deploy expert models at edge nodes, offers a pathway to achieving connected intelligence in sixth-generation (6G) mobile networks and edge artificial intelligence (AI). However, current DMoE systems lack an effective expert selection algorithm to address the simultaneous task-expert relevance and channel diversity inherent in these systems. Traditional AI or communication systems focus on either performance or channel conditions, and direct application of these methods leads to high communication overhead or low performance. To address this, we propose the DMoE protocol to schedule the expert inference and inter-expert transmission. This protocol identifies expert selection and subcarrier allocation as key optimization problems. We formulate an expert selection problem by incorporating both AI performance and channel conditions, and further extend it to a Joint Expert and Subcarrier Allocation (JESA) problem for comprehensive AI and channel management within the DMoE framework. For the NP-hard expert selection problem, we introduce the Dynamic Expert Selection (DES) algorithm, which leverages a linear relaxation as a bounding criterion to significantly reduce search complexity. For the JESA problem, we discover a unique structural property that ensures asymptotic optimality in most scenarios. We propose an iterative algorithm that addresses subcarrier allocation as a subproblem and integrates it with the DES algorithm. The proposed framework effectively manages the tradeoff between task relevance and channel conditions through a tunable importance factor, enabling flexible adaptation to diverse scenarios. Numerical experiments validate the dual benefits of the proposed expert selection algorithm: high performance and significantly reduced cost.
SP3D: Boosting Sparsely-Supervised 3D Object Detection via Accurate Cross-Modal Semantic Prompts
Mar 09, 2025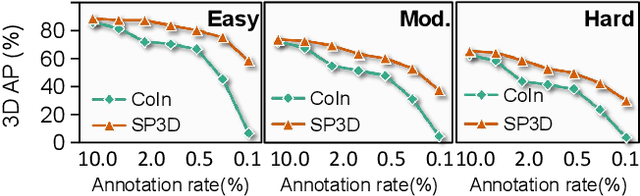
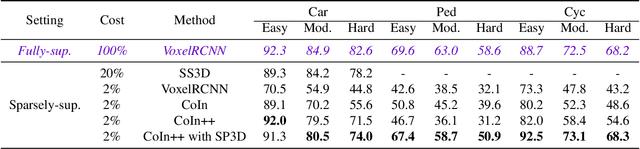
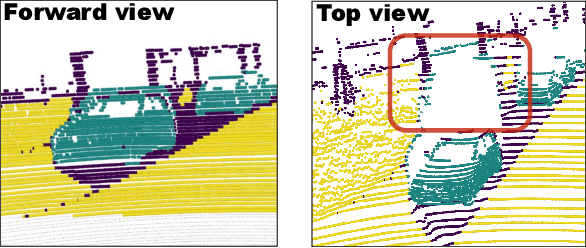
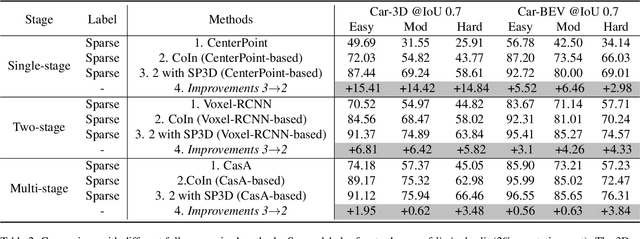
Recently, sparsely-supervised 3D object detection has gained great attention, achieving performance close to fully-supervised 3D objectors while requiring only a few annotated instances. Nevertheless, these methods suffer challenges when accurate labels are extremely absent. In this paper, we propose a boosting strategy, termed SP3D, explicitly utilizing the cross-modal semantic prompts generated from Large Multimodal Models (LMMs) to boost the 3D detector with robust feature discrimination capability under sparse annotation settings. Specifically, we first develop a Confident Points Semantic Transfer (CPST) module that generates accurate cross-modal semantic prompts through boundary-constrained center cluster selection. Based on these accurate semantic prompts, which we treat as seed points, we introduce a Dynamic Cluster Pseudo-label Generation (DCPG) module to yield pseudo-supervision signals from the geometry shape of multi-scale neighbor points. Additionally, we design a Distribution Shape score (DS score) that chooses high-quality supervision signals for the initial training of the 3D detector. Experiments on the KITTI dataset and Waymo Open Dataset (WOD) have validated that SP3D can enhance the performance of sparsely supervised detectors by a large margin under meager labeling conditions. Moreover, we verified SP3D in the zero-shot setting, where its performance exceeded that of the state-of-the-art methods. The code is available at https://github.com/xmuqimingxia/SP3D.
Integrated Sensing and Edge AI: Realizing Intelligent Perception in 6G
Jan 12, 2025Sensing and edge artificial intelligence (AI) are envisioned as two essential and interconnected functions in sixth-generation (6G) mobile networks. On the one hand, sensing-empowered applications rely on powerful AI models to extract features and understand semantics from ubiquitous wireless sensors. On the other hand, the massive amount of sensory data serves as the fuel to continuously refine edge AI models. This deep integration of sensing and edge AI has given rise to a new task-oriented paradigm known as integrated sensing and edge AI (ISEA), which features a holistic design approach to communication, AI computation, and sensing for optimal sensing-task performance. In this article, we present a comprehensive survey for ISEA. We first provide technical preliminaries for sensing, edge AI, and new communication paradigms in ISEA. Then, we study several use cases of ISEA to demonstrate its practical relevance and introduce current standardization and industrial progress. Next, the design principles, metrics, tradeoffs, and architectures of ISEA are established, followed by a thorough overview of ISEA techniques, including digital air interface, over-the-air computation, and advanced signal processing. Its interplay with various 6G advancements, e.g., new physical-layer and networking techniques, are presented. Finally, we present future research opportunities in ISEA, including the integration of foundation models, convergence of ISEA and integrated sensing and communications (ISAC), and ultra-low-latency ISEA.
OC3D: Weakly Supervised Outdoor 3D Object Detection with Only Coarse Click Annotation
Aug 15, 2024



LiDAR-based outdoor 3D object detection has received widespread attention. However, training 3D detectors from the LiDAR point cloud typically relies on expensive bounding box annotations. This paper presents OC3D, an innovative weakly supervised method requiring only coarse clicks on the bird' s eye view of the 3D point cloud. A key challenge here is the absence of complete geometric descriptions of the target objects from such simple click annotations. To address this problem, our proposed OC3D adopts a two-stage strategy. In the first stage, we initially design a novel dynamic and static classification strategy and then propose the Click2Box and Click2Mask modules to generate box-level and mask-level pseudo-labels for static and dynamic instances, respectively. In the second stage, we design a Mask2Box module, leveraging the learning capabilities of neural networks to update mask-level pseudo-labels, which contain less information, to box level pseudo-labels. Experimental results on the widely used KITTI and nuScenes datasets demonstrate that our OC3D with only coarse clicks achieves state-of-the-art performance compared to weakly-supervised 3D detection methods. Combining OC3D with a missing click mining strategy, we propose a OC3D++ pipeline, which requires only 0.2% annotation cost in the KITTI dataset to achieve performance comparable to fully supervised methods.
L4DR: LiDAR-4DRadar Fusion for Weather-Robust 3D Object Detection
Aug 07, 2024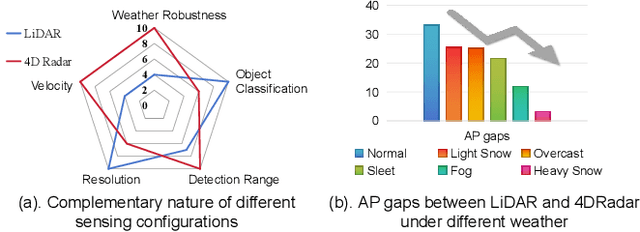
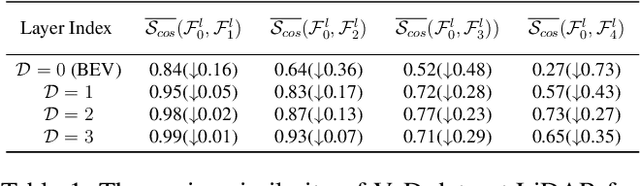
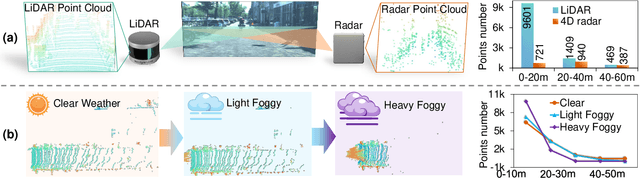
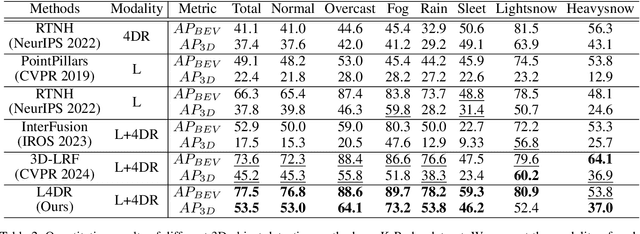
LiDAR-based vision systems are integral for 3D object detection, which is crucial for autonomous navigation. However, they suffer from performance degradation in adverse weather conditions due to the quality deterioration of LiDAR point clouds. Fusing LiDAR with the weather-robust 4D radar sensor is expected to solve this problem. However, the fusion of LiDAR and 4D radar is challenging because they differ significantly in terms of data quality and the degree of degradation in adverse weather. To address these issues, we introduce L4DR, a weather-robust 3D object detection method that effectively achieves LiDAR and 4D Radar fusion. Our L4DR includes Multi-Modal Encoding (MME) and Foreground-Aware Denoising (FAD) technique to reconcile sensor gaps, which is the first exploration of the complementarity of early fusion between LiDAR and 4D radar. Additionally, we design an Inter-Modal and Intra-Modal ({IM}2 ) parallel feature extraction backbone coupled with a Multi-Scale Gated Fusion (MSGF) module to counteract the varying degrees of sensor degradation under adverse weather conditions. Experimental evaluation on a VoD dataset with simulated fog proves that L4DR is more adaptable to changing weather conditions. It delivers a significant performance increase under different fog levels, improving the 3D mAP by up to 18.17% over the traditional LiDAR-only approach. Moreover, the results on the K-Radar dataset validate the consistent performance improvement of L4DR in real-world adverse weather conditions.
Resource Management for Low-latency Cooperative Fine-tuning of Foundation Models at the Network Edge
Jul 13, 2024



The emergence of large-scale foundation models (FoMo's) that can perform human-like intelligence motivates their deployment at the network edge for devices to access state-of-the-art artificial intelligence. For better user experiences, the pre-trained FoMo's need to be adapted to specialized downstream tasks through fine-tuning techniques. To transcend a single device's memory and computation limitations, we advocate multi-device cooperation within the device-edge cooperative fine-tuning (DEFT) paradigm, where edge devices cooperate to simultaneously optimize different parts of fine-tuning parameters within a FoMo. However, the parameter blocks reside at different depths within a FoMo architecture, leading to varied computation latency-and-memory cost due to gradient backpropagation-based calculations. The heterogeneous on-device computation and memory capacities and channel conditions necessitate an integrated communication-and-computation allocation of local computation loads and communication resources to achieve low-latency (LoLa) DEFT. To this end, we consider the depth-ware DEFT block allocation problem. The involved optimal block-device matching is tackled by the proposed low-complexity Cutting-RecoUNting-CHecking (CRUNCH) algorithm, which is designed by exploiting the monotone-increasing property between block depth and computation latency-and-memory cost. Next, the joint bandwidth-and-block allocation makes the problem more sophisticated. We observe a splittable Lagrangian expression through the transformation and analysis of the original problem, where the variables indicating device involvement are introduced. Then, the dual ascent method is employed to tackle this problem iteratively. Through extensive experiments conducted on the GLUE benchmark, our results demonstrate significant latency reduction achievable by LoLa DEFT for fine-tuning a RoBERTa model.
Commonsense Prototype for Outdoor Unsupervised 3D Object Detection
Apr 25, 2024



The prevalent approaches of unsupervised 3D object detection follow cluster-based pseudo-label generation and iterative self-training processes. However, the challenge arises due to the sparsity of LiDAR scans, which leads to pseudo-labels with erroneous size and position, resulting in subpar detection performance. To tackle this problem, this paper introduces a Commonsense Prototype-based Detector, termed CPD, for unsupervised 3D object detection. CPD first constructs Commonsense Prototype (CProto) characterized by high-quality bounding box and dense points, based on commonsense intuition. Subsequently, CPD refines the low-quality pseudo-labels by leveraging the size prior from CProto. Furthermore, CPD enhances the detection accuracy of sparsely scanned objects by the geometric knowledge from CProto. CPD outperforms state-of-the-art unsupervised 3D detectors on Waymo Open Dataset (WOD), PandaSet, and KITTI datasets by a large margin. Besides, by training CPD on WOD and testing on KITTI, CPD attains 90.85% and 81.01% 3D Average Precision on easy and moderate car classes, respectively. These achievements position CPD in close proximity to fully supervised detectors, highlighting the significance of our method. The code will be available at https://github.com/hailanyi/CPD.