 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSP3D: Boosting Sparsely-Supervised 3D Object Detection via Accurate Cross-Modal Semantic Prompts
Mar 09, 2025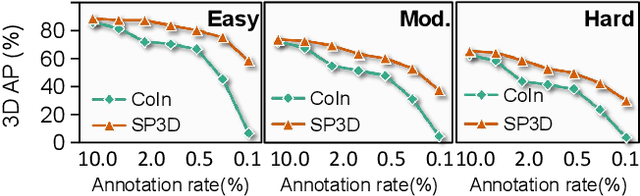
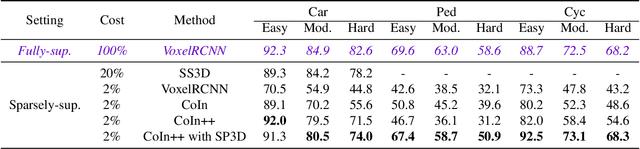
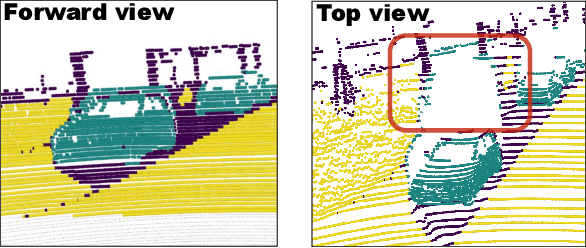
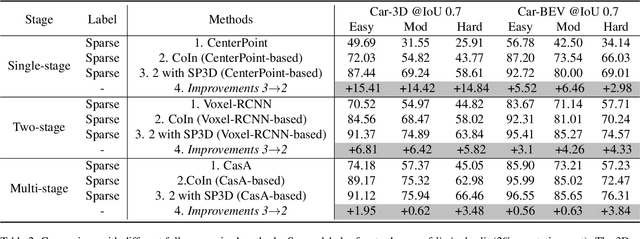
Recently, sparsely-supervised 3D object detection has gained great attention, achieving performance close to fully-supervised 3D objectors while requiring only a few annotated instances. Nevertheless, these methods suffer challenges when accurate labels are extremely absent. In this paper, we propose a boosting strategy, termed SP3D, explicitly utilizing the cross-modal semantic prompts generated from Large Multimodal Models (LMMs) to boost the 3D detector with robust feature discrimination capability under sparse annotation settings. Specifically, we first develop a Confident Points Semantic Transfer (CPST) module that generates accurate cross-modal semantic prompts through boundary-constrained center cluster selection. Based on these accurate semantic prompts, which we treat as seed points, we introduce a Dynamic Cluster Pseudo-label Generation (DCPG) module to yield pseudo-supervision signals from the geometry shape of multi-scale neighbor points. Additionally, we design a Distribution Shape score (DS score) that chooses high-quality supervision signals for the initial training of the 3D detector. Experiments on the KITTI dataset and Waymo Open Dataset (WOD) have validated that SP3D can enhance the performance of sparsely supervised detectors by a large margin under meager labeling conditions. Moreover, we verified SP3D in the zero-shot setting, where its performance exceeded that of the state-of-the-art methods. The code is available at https://github.com/xmuqimingxia/SP3D.
AdaCo: Overcoming Visual Foundation Model Noise in 3D Semantic Segmentation via Adaptive Label Correction
Dec 24, 2024



Recently, Visual Foundation Models (VFMs) have shown a remarkable generalization performance in 3D perception tasks. However, their effectiveness in large-scale outdoor datasets remains constrained by the scarcity of accurate supervision signals, the extensive noise caused by variable outdoor conditions, and the abundance of unknown objects. In this work, we propose a novel label-free learning method, Adaptive Label Correction (AdaCo), for 3D semantic segmentation. AdaCo first introduces the Cross-modal Label Generation Module (CLGM), providing cross-modal supervision with the formidable interpretive capabilities of the VFMs. Subsequently, AdaCo incorporates the Adaptive Noise Corrector (ANC), updating and adjusting the noisy samples within this supervision iteratively during training. Moreover, we develop an Adaptive Robust Loss (ARL) function to modulate each sample's sensitivity to noisy supervision, preventing potential underfitting issues associated with robust loss. Our proposed AdaCo can effectively mitigate the performance limitations of label-free learning networks in 3D semantic segmentation tasks. Extensive experiments on two outdoor benchmark datasets highlight the superior performance of our method.