 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEADER: Learning Reliable Local-to-Global Correspondences for LiDAR Relocalization
Apr 13, 2026LiDAR relocalization has attracted increasing attention as it can deliver accurate 6-DoF pose estimation in complex 3D environments. Recent learning-based regression methods offer efficient solutions by directly predicting global poses without the need for explicit map storage. However, these methods often struggle in challenging scenes due to their equal treatment of all predicted points, which is vulnerable to noise and outliers. In this paper, we propose LEADER, a robust LiDAR-based relocalization framework enhanced by a simple, yet effective geometric encoder. Specifically, a Robust Projection-based Geometric Encoder architecture which captures multi-scale geometric features is first presented to enhance descriptiveness in geometric representation. A Truncated Relative Reliability loss is then formulated to model point-wise ambiguity and mitigate the influence of unreliable predictions. Extensive experiments on the Oxford RobotCar and NCLT datasets demonstrate that LEADER outperforms state-of-the-art methods, achieving 24.1% and 73.9% relative reductions in position error over existing techniques, respectively. The source code is released on https://github.com/JiansW/LEADER.
V2U4Real: A Real-world Large-scale Dataset for Vehicle-to-UAV Cooperative Perception
Mar 26, 2026Modern autonomous vehicle perception systems are often constrained by occlusions, blind spots, and limited sensing range. While existing cooperative perception paradigms, such as Vehicle-to-Vehicle (V2V) and Vehicle-to-Infrastructure (V2I), have demonstrated their effectiveness in mitigating these challenges, they remain limited to ground-level collaboration and cannot fully address large-scale occlusions or long-range perception in complex environments. To advance research in cross-view cooperative perception, we present V2U4Real, the first large-scale real-world multi-modal dataset for Vehicle-to-UAV (V2U) cooperative object perception. V2U4Real is collected by a ground vehicle and a UAV equipped with multi-view LiDARs and RGB cameras. The dataset covers urban streets, university campuses, and rural roads under diverse traffic scenarios, comprising over 56K LiDAR frames, 56K multi-view camera images, and 700K annotated 3D bounding boxes across four classes. To support a wide range of research tasks, we establish benchmarks for single-agent 3D object detection, cooperative 3D object detection, and object tracking. Comprehensive evaluations of several state-of-the-art models demonstrate the effectiveness of V2U cooperation in enhancing perception robustness and long-range awareness. The V2U4Real dataset and codebase is available at https://github.com/VjiaLi/V2U4Real.
FlashCap: Millisecond-Accurate Human Motion Capture via Flashing LEDs and Event-Based Vision
Mar 20, 2026Precise motion timing (PMT) is crucial for swift motion analysis. A millisecond difference may determine victory or defeat in sports competitions. Despite substantial progress in human pose estimation (HPE), PMT remains largely overlooked by the HPE community due to the limited availability of high-temporal-resolution labeled datasets. Today, PMT is achieved using high-speed RGB cameras in specialized scenarios such as the Olympic Games; however, their high costs, light sensitivity, bandwidth, and computational complexity limit their feasibility for daily use. We developed FlashCap, the first flashing LED-based MoCap system for PMT. With FlashCap, we collect a millisecond-resolution human motion dataset, FlashMotion, comprising the event, RGB, LiDAR, and IMU modalities, and demonstrate its high quality through rigorous validation. To evaluate the merits of FlashMotion, we perform two tasks: precise motion timing and high-temporal-resolution HPE. For these tasks, we propose ResPose, a simple yet effective baseline that learns residual poses based on events and RGBs. Experimental results show that ResPose reduces pose estimation errors by ~40% and achieves millisecond-level timing accuracy, enabling new research opportunities. The dataset and code will be shared with the community.
AW-MoE: All-Weather Mixture of Experts for Robust Multi-Modal 3D Object Detection
Mar 17, 2026Robust 3D object detection under adverse weather conditions is crucial for autonomous driving. However, most existing methods simply combine all weather samples for training while overlooking data distribution discrepancies across different weather scenarios, leading to performance conflicts. To address this issue, we introduce AW-MoE, the framework that innovatively integrates Mixture of Experts (MoE) into weather-robust multi-modal 3D object detection approaches. AW-MoE incorporates Image-guided Weather-aware Routing (IWR), which leverages the superior discriminability of image features across weather conditions and their invariance to scene variations for precise weather classification. Based on this accurate classification, IWR selects the top-K most relevant Weather-Specific Experts (WSE) that handle data discrepancies, ensuring optimal detection under all weather conditions. Additionally, we propose a Unified Dual-Modal Augmentation (UDMA) for synchronous LiDAR and 4D Radar dual-modal data augmentation while preserving the realism of scenes. Extensive experiments on the real-world dataset demonstrate that AW-MoE achieves ~ 15% improvement in adverse-weather performance over state-of-the-art methods, while incurring negligible inference overhead. Moreover, integrating AW-MoE into established baseline detectors yields performance improvements surpassing current state-of-the-art methods. These results show the effectiveness and strong scalability of our AW-MoE. We will release the code publicly at https://github.com/windlinsherlock/AW-MoE.
MAGE: Multi-scale Autoregressive Generation for Offline Reinforcement Learning
Feb 27, 2026Generative models have gained significant traction in offline reinforcement learning (RL) due to their ability to model complex trajectory distributions. However, existing generation-based approaches still struggle with long-horizon tasks characterized by sparse rewards. Some hierarchical generation methods have been developed to mitigate this issue by decomposing the original problem into shorter-horizon subproblems using one policy and generating detailed actions with another. While effective, these methods often overlook the multi-scale temporal structure inherent in trajectories, resulting in suboptimal performance. To overcome these limitations, we propose MAGE, a Multi-scale Autoregressive GEneration-based offline RL method. MAGE incorporates a condition-guided multi-scale autoencoder to learn hierarchical trajectory representations, along with a multi-scale transformer that autoregressively generates trajectory representations from coarse to fine temporal scales. MAGE effectively captures temporal dependencies of trajectories at multiple resolutions. Additionally, a condition-guided decoder is employed to exert precise control over short-term behaviors. Extensive experiments on five offline RL benchmarks against fifteen baseline algorithms show that MAGE successfully integrates multi-scale trajectory modeling with conditional guidance, generating coherent and controllable trajectories in long-horizon sparse-reward settings.
MoniRefer: A Real-world Large-scale Multi-modal Dataset based on Roadside Infrastructure for 3D Visual Grounding
Dec 31, 20253D visual grounding aims to localize the object in 3D point cloud scenes that semantically corresponds to given natural language sentences. It is very critical for roadside infrastructure system to interpret natural languages and localize relevant target objects in complex traffic environments. However, most existing datasets and approaches for 3D visual grounding focus on the indoor and outdoor driving scenes, outdoor monitoring scenarios remain unexplored due to scarcity of paired point cloud-text data captured by roadside infrastructure sensors. In this paper, we introduce a novel task of 3D Visual Grounding for Outdoor Monitoring Scenarios, which enables infrastructure-level understanding of traffic scenes beyond the ego-vehicle perspective. To support this task, we construct MoniRefer, the first real-world large-scale multi-modal dataset for roadside-level 3D visual grounding. The dataset consists of about 136,018 objects with 411,128 natural language expressions collected from multiple complex traffic intersections in the real-world environments. To ensure the quality and accuracy of the dataset, we manually verified all linguistic descriptions and 3D labels for objects. Additionally, we also propose a new end-to-end method, named Moni3DVG, which utilizes the rich appearance information provided by images and geometry and optical information from point cloud for multi-modal feature learning and 3D object localization. Extensive experiments and ablation studies on the proposed benchmarks demonstrate the superiority and effectiveness of our method. Our dataset and code will be released.
V2VLoc: Robust GNSS-Free Collaborative Perception via LiDAR Localization
Nov 18, 2025


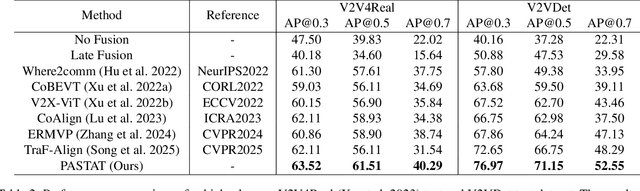
Multi-agents rely on accurate poses to share and align observations, enabling a collaborative perception of the environment. However, traditional GNSS-based localization often fails in GNSS-denied environments, making consistent feature alignment difficult in collaboration. To tackle this challenge, we propose a robust GNSS-free collaborative perception framework based on LiDAR localization. Specifically, we propose a lightweight Pose Generator with Confidence (PGC) to estimate compact pose and confidence representations. To alleviate the effects of localization errors, we further develop the Pose-Aware Spatio-Temporal Alignment Transformer (PASTAT), which performs confidence-aware spatial alignment while capturing essential temporal context. Additionally, we present a new simulation dataset, V2VLoc, which can be adapted for both LiDAR localization and collaborative detection tasks. V2VLoc comprises three subsets: Town1Loc, Town4Loc, and V2VDet. Town1Loc and Town4Loc offer multi-traversal sequences for training in localization tasks, whereas V2VDet is specifically intended for the collaborative detection task. Extensive experiments conducted on the V2VLoc dataset demonstrate that our approach achieves state-of-the-art performance under GNSS-denied conditions. We further conduct extended experiments on the real-world V2V4Real dataset to validate the effectiveness and generalizability of PASTAT.
WinMamba: Multi-Scale Shifted Windows in State Space Model for 3D Object Detection
Nov 17, 2025



3D object detection is critical for autonomous driving, yet it remains fundamentally challenging to simultaneously maximize computational efficiency and capture long-range spatial dependencies. We observed that Mamba-based models, with their linear state-space design, capture long-range dependencies at lower cost, offering a promising balance between efficiency and accuracy. However, existing methods rely on axis-aligned scanning within a fixed window, inevitably discarding spatial information. To address this problem, we propose WinMamba, a novel Mamba-based 3D feature-encoding backbone composed of stacked WinMamba blocks. To enhance the backbone with robust multi-scale representation, the WinMamba block incorporates a window-scale-adaptive module that compensates voxel features across varying resolutions during sampling. Meanwhile, to obtain rich contextual cues within the linear state space, we equip the WinMamba layer with a learnable positional encoding and a window-shift strategy. Extensive experiments on the KITTI and Waymo datasets demonstrate that WinMamba significantly outperforms the baseline. Ablation studies further validate the individual contributions of the WSF and AWF modules in improving detection accuracy. The code will be made publicly available.
MSGNav: Unleashing the Power of Multi-modal 3D Scene Graph for Zero-Shot Embodied Navigation
Nov 14, 2025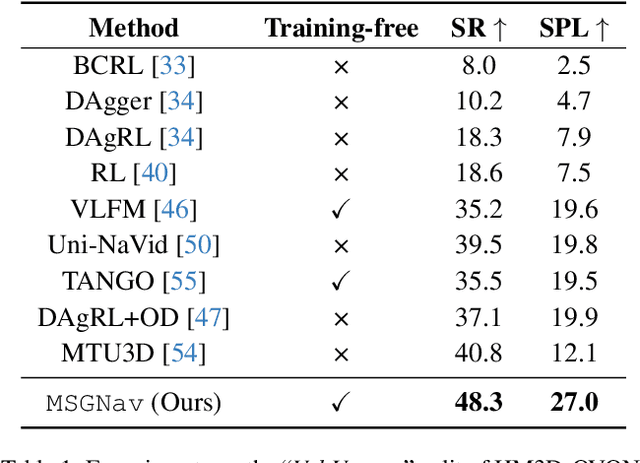
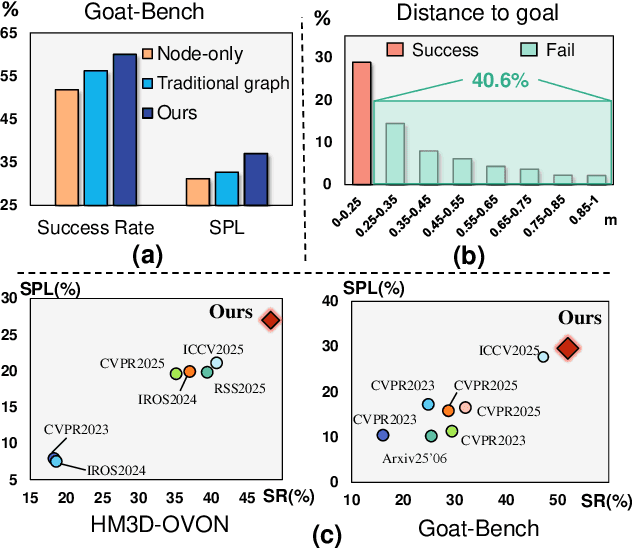
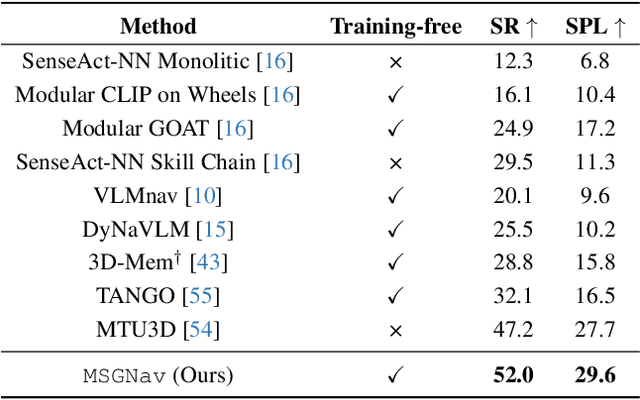
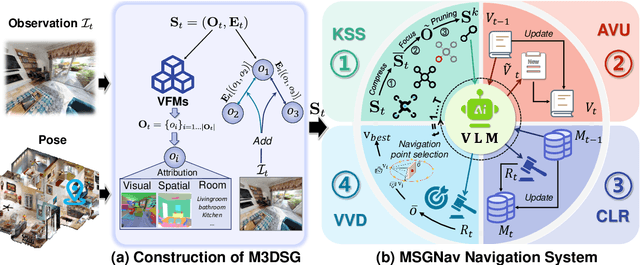
Embodied navigation is a fundamental capability for robotic agents operating. Real-world deployment requires open vocabulary generalization and low training overhead, motivating zero-shot methods rather than task-specific RL training. However, existing zero-shot methods that build explicit 3D scene graphs often compress rich visual observations into text-only relations, leading to high construction cost, irreversible loss of visual evidence, and constrained vocabularies. To address these limitations, we introduce the Multi-modal 3D Scene Graph (M3DSG), which preserves visual cues by replacing textual relation
ClimbingCap: Multi-Modal Dataset and Method for Rock Climbing in World Coordinate
Mar 27, 2025Human Motion Recovery (HMR) research mainly focuses on ground-based motions such as running. The study on capturing climbing motion, an off-ground motion, is sparse. This is partly due to the limited availability of climbing motion datasets, especially large-scale and challenging 3D labeled datasets. To address the insufficiency of climbing motion datasets, we collect AscendMotion, a large-scale well-annotated, and challenging climbing motion dataset. It consists of 412k RGB, LiDAR frames, and IMU measurements, including the challenging climbing motions of 22 skilled climbing coaches across 12 different rock walls. Capturing the climbing motions is challenging as it requires precise recovery of not only the complex pose but also the global position of climbers. Although multiple global HMR methods have been proposed, they cannot faithfully capture climbing motions. To address the limitations of HMR methods for climbing, we propose ClimbingCap, a motion recovery method that reconstructs continuous 3D human climbing motion in a global coordinate system. One key insight is to use the RGB and LiDAR modalities to separately reconstruct motions in camera coordinates and global coordinates and to optimize them jointly. We demonstrate the quality of the AscendMotion dataset and present promising results from ClimbingCap. The AscendMotion dataset and source code release publicly at \href{this link}{http://www.lidarhumanmotion.net/climbingcap/}