 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
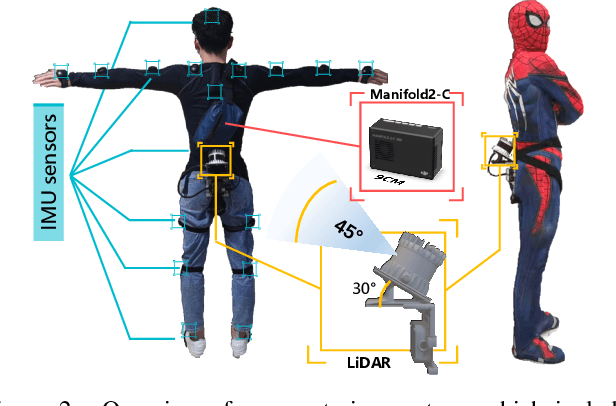
Add to EdgeClimbingCap: Multi-Modal Dataset and Method for Rock Climbing in World Coordinate
Mar 27, 2025Human Motion Recovery (HMR) research mainly focuses on ground-based motions such as running. The study on capturing climbing motion, an off-ground motion, is sparse. This is partly due to the limited availability of climbing motion datasets, especially large-scale and challenging 3D labeled datasets. To address the insufficiency of climbing motion datasets, we collect AscendMotion, a large-scale well-annotated, and challenging climbing motion dataset. It consists of 412k RGB, LiDAR frames, and IMU measurements, including the challenging climbing motions of 22 skilled climbing coaches across 12 different rock walls. Capturing the climbing motions is challenging as it requires precise recovery of not only the complex pose but also the global position of climbers. Although multiple global HMR methods have been proposed, they cannot faithfully capture climbing motions. To address the limitations of HMR methods for climbing, we propose ClimbingCap, a motion recovery method that reconstructs continuous 3D human climbing motion in a global coordinate system. One key insight is to use the RGB and LiDAR modalities to separately reconstruct motions in camera coordinates and global coordinates and to optimize them jointly. We demonstrate the quality of the AscendMotion dataset and present promising results from ClimbingCap. The AscendMotion dataset and source code release publicly at \href{this link}{http://www.lidarhumanmotion.net/climbingcap/}
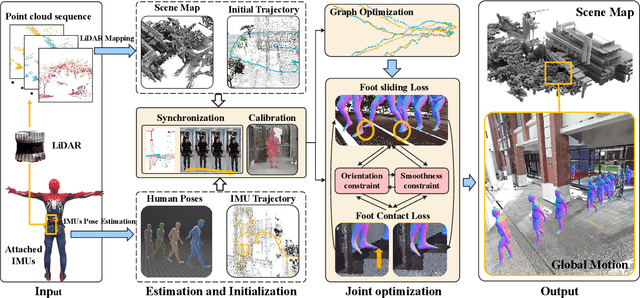
HiSC4D: Human-centered interaction and 4D Scene Capture in Large-scale Space Using Wearable IMUs and LiDAR
Sep 09, 2024



We introduce HiSC4D, a novel Human-centered interaction and 4D Scene Capture method, aimed at accurately and efficiently creating a dynamic digital world, containing large-scale indoor-outdoor scenes, diverse human motions, rich human-human interactions, and human-environment interactions. By utilizing body-mounted IMUs and a head-mounted LiDAR, HiSC4D can capture egocentric human motions in unconstrained space without the need for external devices and pre-built maps. This affords great flexibility and accessibility for human-centered interaction and 4D scene capturing in various environments. Taking into account that IMUs can capture human spatially unrestricted poses but are prone to drifting for long-period using, and while LiDAR is stable for global localization but rough for local positions and orientations, HiSC4D employs a joint optimization method, harmonizing all sensors and utilizing environment cues, yielding promising results for long-term capture in large scenes. To promote research of egocentric human interaction in large scenes and facilitate downstream tasks, we also present a dataset, containing 8 sequences in 4 large scenes (200 to 5,000 $m^2$), providing 36k frames of accurate 4D human motions with SMPL annotations and dynamic scenes, 31k frames of cropped human point clouds, and scene mesh of the environment. A variety of scenarios, such as the basketball gym and commercial street, alongside challenging human motions, such as daily greeting, one-on-one basketball playing, and tour guiding, demonstrate the effectiveness and the generalization ability of HiSC4D. The dataset and code will be publicated on www.lidarhumanmotion.net/hisc4d available for research purposes.
RELI11D: A Comprehensive Multimodal Human Motion Dataset and Method
Mar 28, 2024



Comprehensive capturing of human motions requires both accurate captures of complex poses and precise localization of the human within scenes. Most of the HPE datasets and methods primarily rely on RGB, LiDAR, or IMU data. However, solely using these modalities or a combination of them may not be adequate for HPE, particularly for complex and fast movements. For holistic human motion understanding, we present RELI11D, a high-quality multimodal human motion dataset involves LiDAR, IMU system, RGB camera, and Event camera. It records the motions of 10 actors performing 5 sports in 7 scenes, including 3.32 hours of synchronized LiDAR point clouds, IMU measurement data, RGB videos and Event steams. Through extensive experiments, we demonstrate that the RELI11D presents considerable challenges and opportunities as it contains many rapid and complex motions that require precise location. To address the challenge of integrating different modalities, we propose LEIR, a multimodal baseline that effectively utilizes LiDAR Point Cloud, Event stream, and RGB through our cross-attention fusion strategy. We show that LEIR exhibits promising results for rapid motions and daily motions and that utilizing the characteristics of multiple modalities can indeed improve HPE performance. Both the dataset and source code will be released publicly to the research community, fostering collaboration and enabling further exploration in this field.
CIMI4D: A Large Multimodal Climbing Motion Dataset under Human-scene Interactions
Mar 31, 2023Motion capture is a long-standing research problem. Although it has been studied for decades, the majority of research focus on ground-based movements such as walking, sitting, dancing, etc. Off-grounded actions such as climbing are largely overlooked. As an important type of action in sports and firefighting field, the climbing movements is challenging to capture because of its complex back poses, intricate human-scene interactions, and difficult global localization. The research community does not have an in-depth understanding of the climbing action due to the lack of specific datasets. To address this limitation, we collect CIMI4D, a large rock \textbf{C}l\textbf{I}mbing \textbf{M}ot\textbf{I}on dataset from 12 persons climbing 13 different climbing walls. The dataset consists of around 180,000 frames of pose inertial measurements, LiDAR point clouds, RGB videos, high-precision static point cloud scenes, and reconstructed scene meshes. Moreover, we frame-wise annotate touch rock holds to facilitate a detailed exploration of human-scene interaction. The core of this dataset is a blending optimization process, which corrects for the pose as it drifts and is affected by the magnetic conditions. To evaluate the merit of CIMI4D, we perform four tasks which include human pose estimations (with/without scene constraints), pose prediction, and pose generation. The experimental results demonstrate that CIMI4D presents great challenges to existing methods and enables extensive research opportunities. We share the dataset with the research community in http://www.lidarhumanmotion.net/cimi4d/.
SLOPER4D: A Scene-Aware Dataset for Global 4D Human Pose Estimation in Urban Environments
Mar 18, 2023



We present SLOPER4D, a novel scene-aware dataset collected in large urban environments to facilitate the research of global human pose estimation (GHPE) with human-scene interaction in the wild. Employing a head-mounted device integrated with a LiDAR and camera, we record 12 human subjects' activities over 10 diverse urban scenes from an egocentric view. Frame-wise annotations for 2D key points, 3D pose parameters, and global translations are provided, together with reconstructed scene point clouds. To obtain accurate 3D ground truth in such large dynamic scenes, we propose a joint optimization method to fit local SMPL meshes to the scene and fine-tune the camera calibration during dynamic motions frame by frame, resulting in plausible and scene-natural 3D human poses. Eventually, SLOPER4D consists of 15 sequences of human motions, each of which has a trajectory length of more than 200 meters (up to 1,300 meters) and covers an area of more than 2,000 $m^2$ (up to 13,000 $m^2$), including more than 100K LiDAR frames, 300k video frames, and 500K IMU-based motion frames. With SLOPER4D, we provide a detailed and thorough analysis of two critical tasks, including camera-based 3D HPE and LiDAR-based 3D HPE in urban environments, and benchmark a new task, GHPE. The in-depth analysis demonstrates SLOPER4D poses significant challenges to existing methods and produces great research opportunities. The dataset and code are released at \url{http://www.lidarhumanmotion.net/sloper4d/}
HSC4D: Human-centered 4D Scene Capture in Large-scale Indoor-outdoor Space Using Wearable IMUs and LiDAR
Apr 08, 2022

We propose Human-centered 4D Scene Capture (HSC4D) to accurately and efficiently create a dynamic digital world, containing large-scale indoor-outdoor scenes, diverse human motions, and rich interactions between humans and environments. Using only body-mounted IMUs and LiDAR, HSC4D is space-free without any external devices' constraints and map-free without pre-built maps. Considering that IMUs can capture human poses but always drift for long-period use, while LiDAR is stable for global localization but rough for local positions and orientations, HSC4D makes both sensors complement each other by a joint optimization and achieves promising results for long-term capture. Relationships between humans and environments are also explored to make their interaction more realistic. To facilitate many down-stream tasks, like AR, VR, robots, autonomous driving, etc., we propose a dataset containing three large scenes (1k-5k $m^2$) with accurate dynamic human motions and locations. Diverse scenarios (climbing gym, multi-story building, slope, etc.) and challenging human activities (exercising, walking up/down stairs, climbing, etc.) demonstrate the effectiveness and the generalization ability of HSC4D. The dataset and code are available at http://www.lidarhumanmotion.net/hsc4d/.