 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashCap: Millisecond-Accurate Human Motion Capture via Flashing LEDs and Event-Based Vision
Mar 20, 2026Precise motion timing (PMT) is crucial for swift motion analysis. A millisecond difference may determine victory or defeat in sports competitions. Despite substantial progress in human pose estimation (HPE), PMT remains largely overlooked by the HPE community due to the limited availability of high-temporal-resolution labeled datasets. Today, PMT is achieved using high-speed RGB cameras in specialized scenarios such as the Olympic Games; however, their high costs, light sensitivity, bandwidth, and computational complexity limit their feasibility for daily use. We developed FlashCap, the first flashing LED-based MoCap system for PMT. With FlashCap, we collect a millisecond-resolution human motion dataset, FlashMotion, comprising the event, RGB, LiDAR, and IMU modalities, and demonstrate its high quality through rigorous validation. To evaluate the merits of FlashMotion, we perform two tasks: precise motion timing and high-temporal-resolution HPE. For these tasks, we propose ResPose, a simple yet effective baseline that learns residual poses based on events and RGBs. Experimental results show that ResPose reduces pose estimation errors by ~40% and achieves millisecond-level timing accuracy, enabling new research opportunities. The dataset and code will be shared with the community.
Walking Further: Semantic-aware Multimodal Gait Recognition Under Long-Range Conditions
Mar 15, 2026Gait recognition is an emerging biometric technology that enables non-intrusive and hard-to-spoof human identification. However, most existing methods are confined to short-range, unimodal settings and fail to generalize to long-range and cross-distance scenarios under real-world conditions. To address this gap, we present \textbf{LRGait}, the first LiDAR-Camera multimodal benchmark designed for robust long-range gait recognition across diverse outdoor distances and environments. We further propose \textbf{EMGaitNet}, an end-to-end framework tailored for long-range multimodal gait recognition. To bridge the modality gap between RGB images and point clouds, we introduce a semantic-guided fusion pipeline. A CLIP-based Semantic Mining (SeMi) module first extracts human body-part-aware semantic cues, which are then employed to align 2D and 3D features via a Semantic-Guided Alignment (SGA) module within a unified embedding space. A Symmetric Cross-Attention Fusion (SCAF) module hierarchically integrates visual contours and 3D geometric features, and a Spatio-Temporal (ST) module captures global gait dynamics. Extensive experiments on various gait datasets validate the effectiveness of our method.
MAGE: Multi-scale Autoregressive Generation for Offline Reinforcement Learning
Feb 27, 2026Generative models have gained significant traction in offline reinforcement learning (RL) due to their ability to model complex trajectory distributions. However, existing generation-based approaches still struggle with long-horizon tasks characterized by sparse rewards. Some hierarchical generation methods have been developed to mitigate this issue by decomposing the original problem into shorter-horizon subproblems using one policy and generating detailed actions with another. While effective, these methods often overlook the multi-scale temporal structure inherent in trajectories, resulting in suboptimal performance. To overcome these limitations, we propose MAGE, a Multi-scale Autoregressive GEneration-based offline RL method. MAGE incorporates a condition-guided multi-scale autoencoder to learn hierarchical trajectory representations, along with a multi-scale transformer that autoregressively generates trajectory representations from coarse to fine temporal scales. MAGE effectively captures temporal dependencies of trajectories at multiple resolutions. Additionally, a condition-guided decoder is employed to exert precise control over short-term behaviors. Extensive experiments on five offline RL benchmarks against fifteen baseline algorithms show that MAGE successfully integrates multi-scale trajectory modeling with conditional guidance, generating coherent and controllable trajectories in long-horizon sparse-reward settings.
Revisiting LLM Value Probing Strategies: Are They Robust and Expressive?
Jul 17, 2025There has been extensive research on assessing the value orientation of Large Language Models (LLMs) as it can shape user experiences across demographic groups. However, several challenges remain. First, while the Multiple Choice Question (MCQ) setting has been shown to be vulnerable to perturbations, there is no systematic comparison of probing methods for value probing. Second, it is unclear to what extent the probed values capture in-context information and reflect models' preferences for real-world actions. In this paper, we evaluate the robustness and expressiveness of value representations across three widely used probing strategies. We use variations in prompts and options, showing that all methods exhibit large variances under input perturbations. We also introduce two tasks studying whether the values are responsive to demographic context, and how well they align with the models' behaviors in value-related scenarios. We show that the demographic context has little effect on the free-text generation, and the models' values only weakly correlate with their preference for value-based actions. Our work highlights the need for a more careful examination of LLM value probing and awareness of its limitations.
ClimbingCap: Multi-Modal Dataset and Method for Rock Climbing in World Coordinate
Mar 27, 2025Human Motion Recovery (HMR) research mainly focuses on ground-based motions such as running. The study on capturing climbing motion, an off-ground motion, is sparse. This is partly due to the limited availability of climbing motion datasets, especially large-scale and challenging 3D labeled datasets. To address the insufficiency of climbing motion datasets, we collect AscendMotion, a large-scale well-annotated, and challenging climbing motion dataset. It consists of 412k RGB, LiDAR frames, and IMU measurements, including the challenging climbing motions of 22 skilled climbing coaches across 12 different rock walls. Capturing the climbing motions is challenging as it requires precise recovery of not only the complex pose but also the global position of climbers. Although multiple global HMR methods have been proposed, they cannot faithfully capture climbing motions. To address the limitations of HMR methods for climbing, we propose ClimbingCap, a motion recovery method that reconstructs continuous 3D human climbing motion in a global coordinate system. One key insight is to use the RGB and LiDAR modalities to separately reconstruct motions in camera coordinates and global coordinates and to optimize them jointly. We demonstrate the quality of the AscendMotion dataset and present promising results from ClimbingCap. The AscendMotion dataset and source code release publicly at \href{this link}{http://www.lidarhumanmotion.net/climbingcap/}
L2RSI: Cross-view LiDAR-based Place Recognition for Large-scale Urban Scenes via Remote Sensing Imagery
Mar 14, 2025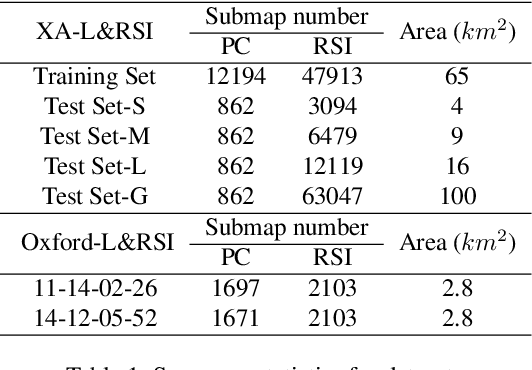
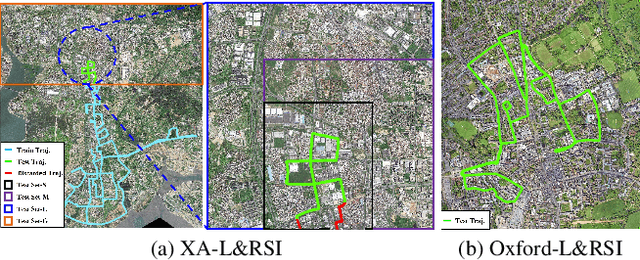
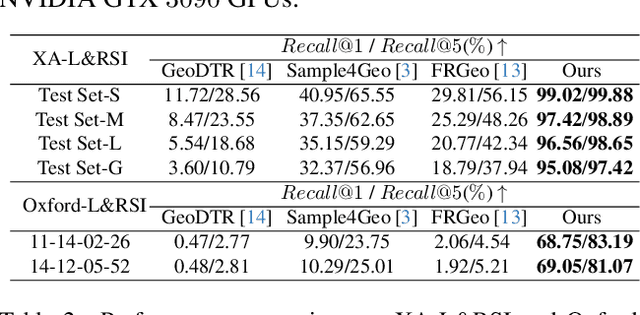
We tackle the challenge of LiDAR-based place recognition, which traditionally depends on costly and time-consuming prior 3D maps. To overcome this, we first construct XA-L&RSI dataset, which encompasses approximately $110,000$ remote sensing submaps and $13,000$ LiDAR point cloud submaps captured in urban scenes, and propose a novel method, L2RSI, for cross-view LiDAR place recognition using high-resolution Remote Sensing Imagery. This approach enables large-scale localization capabilities at a reduced cost by leveraging readily available overhead images as map proxies. L2RSI addresses the dual challenges of cross-view and cross-modal place recognition by learning feature alignment between point cloud submaps and remote sensing submaps in the semantic domain. Additionally, we introduce a novel probability propagation method based on a dynamic Gaussian mixture model to refine position predictions, effectively leveraging temporal and spatial information. This approach enables large-scale retrieval and cross-scene generalization without fine-tuning. Extensive experiments on XA-L&RSI demonstrate that, within a $100km^2$ retrieval range, L2RSI accurately localizes $95.08\%$ of point cloud submaps within a $30m$ radius for top-$1$ retrieved location. We provide a video to more vividly display the place recognition results of L2RSI at https://shizw695.github.io/L2RSI/.
ConDo: Continual Domain Expansion for Absolute Pose Regression
Dec 18, 2024



Visual localization is a fundamental machine learning problem. Absolute Pose Regression (APR) trains a scene-dependent model to efficiently map an input image to the camera pose in a pre-defined scene. However, many applications have continually changing environments, where inference data at novel poses or scene conditions (weather, geometry) appear after deployment. Training APR on a fixed dataset leads to overfitting, making it fail catastrophically on challenging novel data. This work proposes Continual Domain Expansion (ConDo), which continually collects unlabeled inference data to update the deployed APR. Instead of applying standard unsupervised domain adaptation methods which are ineffective for APR, ConDo effectively learns from unlabeled data by distilling knowledge from scene-agnostic localization methods. By sampling data uniformly from historical and newly collected data, ConDo can effectively expand the generalization domain of APR. Large-scale benchmarks with various scene types are constructed to evaluate models under practical (long-term) data changes. ConDo consistently and significantly outperforms baselines across architectures, scene types, and data changes. On challenging scenes (Fig.1), it reduces the localization error by >7x (14.8m vs 1.7m). Analysis shows the robustness of ConDo against compute budgets, replay buffer sizes and teacher prediction noise. Comparing to model re-training, ConDo achieves similar performance up to 25x faster.
A New Adversarial Perspective for LiDAR-based 3D Object Detection
Dec 17, 2024



Autonomous vehicles (AVs) rely on LiDAR sensors for environmental perception and decision-making in driving scenarios. However, ensuring the safety and reliability of AVs in complex environments remains a pressing challenge. To address this issue, we introduce a real-world dataset (ROLiD) comprising LiDAR-scanned point clouds of two random objects: water mist and smoke. In this paper, we introduce a novel adversarial perspective by proposing an attack framework that utilizes water mist and smoke to simulate environmental interference. Specifically, we propose a point cloud sequence generation method using a motion and content decomposition generative adversarial network named PCS-GAN to simulate the distribution of random objects. Furthermore, leveraging the simulated LiDAR scanning characteristics implemented with Range Image, we examine the effects of introducing random object perturbations at various positions on the target vehicle. Extensive experiments demonstrate that adversarial perturbations based on random objects effectively deceive vehicle detection and reduce the recognition rate of 3D object detection models.
Mining and Transferring Feature-Geometry Coherence for Unsupervised Point Cloud Registration
Nov 04, 2024



Point cloud registration, a fundamental task in 3D vision, has achieved remarkable success with learning-based methods in outdoor environments. Unsupervised outdoor point cloud registration methods have recently emerged to circumvent the need for costly pose annotations. However, they fail to establish reliable optimization objectives for unsupervised training, either relying on overly strong geometric assumptions, or suffering from poor-quality pseudo-labels due to inadequate integration of low-level geometric and high-level contextual information. We have observed that in the feature space, latent new inlier correspondences tend to cluster around respective positive anchors that summarize features of existing inliers. Motivated by this observation, we propose a novel unsupervised registration method termed INTEGER to incorporate high-level contextual information for reliable pseudo-label mining. Specifically, we propose the Feature-Geometry Coherence Mining module to dynamically adapt the teacher for each mini-batch of data during training and discover reliable pseudo-labels by considering both high-level feature representations and low-level geometric cues. Furthermore, we propose Anchor-Based Contrastive Learning to facilitate contrastive learning with anchors for a robust feature space. Lastly, we introduce a Mixed-Density Student to learn density-invariant features, addressing challenges related to density variation and low overlap in the outdoor scenario. Extensive experiments on KITTI and nuScenes datasets demonstrate that our INTEGER achieves competitive performance in terms of accuracy and generalizability.
HiSC4D: Human-centered interaction and 4D Scene Capture in Large-scale Space Using Wearable IMUs and LiDAR
Sep 09, 2024



We introduce HiSC4D, a novel Human-centered interaction and 4D Scene Capture method, aimed at accurately and efficiently creating a dynamic digital world, containing large-scale indoor-outdoor scenes, diverse human motions, rich human-human interactions, and human-environment interactions. By utilizing body-mounted IMUs and a head-mounted LiDAR, HiSC4D can capture egocentric human motions in unconstrained space without the need for external devices and pre-built maps. This affords great flexibility and accessibility for human-centered interaction and 4D scene capturing in various environments. Taking into account that IMUs can capture human spatially unrestricted poses but are prone to drifting for long-period using, and while LiDAR is stable for global localization but rough for local positions and orientations, HiSC4D employs a joint optimization method, harmonizing all sensors and utilizing environment cues, yielding promising results for long-term capture in large scenes. To promote research of egocentric human interaction in large scenes and facilitate downstream tasks, we also present a dataset, containing 8 sequences in 4 large scenes (200 to 5,000 $m^2$), providing 36k frames of accurate 4D human motions with SMPL annotations and dynamic scenes, 31k frames of cropped human point clouds, and scene mesh of the environment. A variety of scenarios, such as the basketball gym and commercial street, alongside challenging human motions, such as daily greeting, one-on-one basketball playing, and tour guiding, demonstrate the effectiveness and the generalization ability of HiSC4D. The dataset and code will be publicated on www.lidarhumanmotion.net/hisc4d available for research purposes.