 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Web Agent Training through Automatic Data Generation and Fine-grained Evaluation
Feb 13, 2026We present a scalable pipeline for automatically generating high-quality training data for web agents. In particular, a major challenge in identifying high-quality training instances is trajectory evaluation - quantifying how much progress was made towards task completion. We introduce a novel constraint-based evaluation framework that provides fine-grained assessment of progress towards task completion. This enables us to leverage partially successful trajectories, which significantly expands the amount of usable training data. We evaluate our method on a new benchmark we propose called BookingArena, which consists of complex booking tasks across 20 popular websites, and demonstrate that our distilled student model outperforms open-source approaches and matches or exceeds commercial systems, while being a significantly smaller model. Our work addresses the challenge of efficiently creating diverse, realistic web interaction datasets and provides a systematic evaluation methodology for complex structured web tasks.
Gaming the Judge: Unfaithful Chain-of-Thought Can Undermine Agent Evaluation
Jan 21, 2026Large language models (LLMs) are increasingly used as judges to evaluate agent performance, particularly in non-verifiable settings where judgments rely on agent trajectories including chain-of-thought (CoT) reasoning. This paradigm implicitly assumes that the agent's CoT faithfully reflects both its internal reasoning and the underlying environment state. We show this assumption is brittle: LLM judges are highly susceptible to manipulation of agent reasoning traces. By systematically rewriting agent CoTs while holding actions and observations fixed, we demonstrate that manipulated reasoning alone can inflate false positive rates of state-of-the-art VLM judges by up to 90% across 800 trajectories spanning diverse web tasks. We study manipulation strategies spanning style-based approaches that alter only the presentation of reasoning and content-based approaches that fabricate signals of task progress, and find that content-based manipulations are consistently more effective. We evaluate prompting-based techniques and scaling judge-time compute, which reduce but do not fully eliminate susceptibility to manipulation. Our findings reveal a fundamental vulnerability in LLM-based evaluation and highlight the need for judging mechanisms that verify reasoning claims against observable evidence.
Towards Minimal Fine-Tuning of VLMs
Dec 22, 2025We introduce Image-LoRA, a lightweight parameter efficient fine-tuning (PEFT) recipe for transformer-based vision-language models (VLMs). Image-LoRA applies low-rank adaptation only to the value path of attention layers within the visual-token span, reducing adapter-only training FLOPs roughly in proportion to the visual-token fraction. We further adapt only a subset of attention heads, selected using head influence scores estimated with a rank-1 Image-LoRA, and stabilize per-layer updates via selection-size normalization. Across screen-centric grounding and referring benchmarks spanning text-heavy to image-heavy regimes, Image-LoRA matches or closely approaches standard LoRA accuracy while using fewer trainable parameters and lower adapter-only training FLOPs. The method also preserves the pure-text reasoning performance of VLMs before and after fine-tuning, as further shown on GSM8K.
Revisiting LLM Value Probing Strategies: Are They Robust and Expressive?
Jul 17, 2025There has been extensive research on assessing the value orientation of Large Language Models (LLMs) as it can shape user experiences across demographic groups. However, several challenges remain. First, while the Multiple Choice Question (MCQ) setting has been shown to be vulnerable to perturbations, there is no systematic comparison of probing methods for value probing. Second, it is unclear to what extent the probed values capture in-context information and reflect models' preferences for real-world actions. In this paper, we evaluate the robustness and expressiveness of value representations across three widely used probing strategies. We use variations in prompts and options, showing that all methods exhibit large variances under input perturbations. We also introduce two tasks studying whether the values are responsive to demographic context, and how well they align with the models' behaviors in value-related scenarios. We show that the demographic context has little effect on the free-text generation, and the models' values only weakly correlate with their preference for value-based actions. Our work highlights the need for a more careful examination of LLM value probing and awareness of its limitations.
Scalable Video-to-Dataset Generation for Cross-Platform Mobile Agents
May 19, 2025Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have sparked significant interest in developing GUI visual agents. We introduce MONDAY (Mobile OS Navigation Task Dataset for Agents from YouTube), a large-scale dataset of 313K annotated frames from 20K instructional videos capturing diverse real-world mobile OS navigation across multiple platforms. Models that include MONDAY in their pre-training phases demonstrate robust cross-platform generalization capabilities, consistently outperforming models trained on existing single OS datasets while achieving an average performance gain of 18.11%p on an unseen mobile OS platform. To enable continuous dataset expansion as mobile platforms evolve, we present an automated framework that leverages publicly available video content to create comprehensive task datasets without manual annotation. Our framework comprises robust OCR-based scene detection (95.04% F1score), near-perfect UI element detection (99.87% hit ratio), and novel multi-step action identification to extract reliable action sequences across diverse interface configurations. We contribute both the MONDAY dataset and our automated collection framework to facilitate future research in mobile OS navigation.
Visual Test-time Scaling for GUI Agent Grounding
May 01, 2025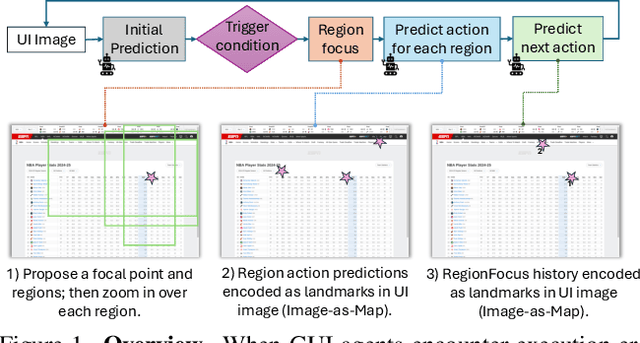
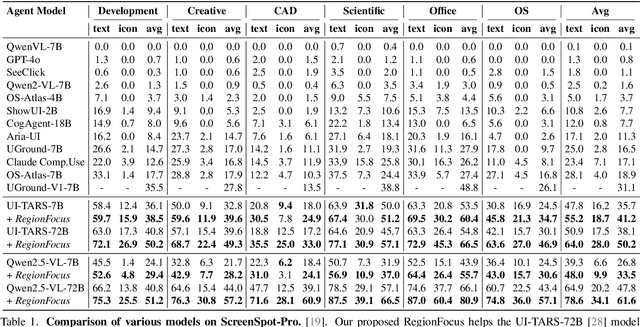
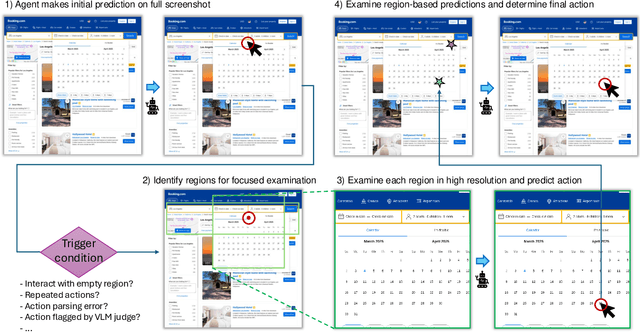
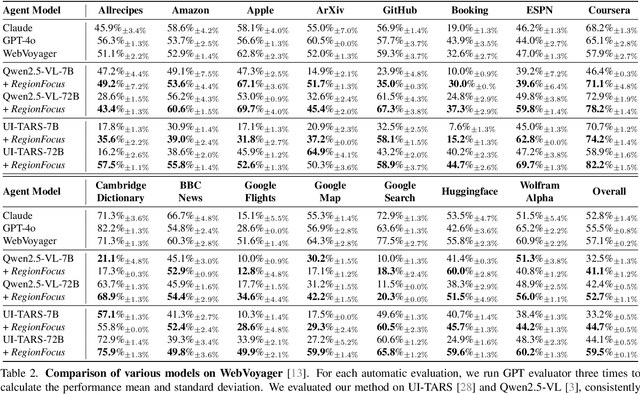
We introduce RegionFocus, a visual test-time scaling approach for Vision Language Model Agents. Understanding webpages is challenging due to the visual complexity of GUI images and the large number of interface elements, making accurate action selection difficult. Our approach dynamically zooms in on relevant regions, reducing background clutter and improving grounding accuracy. To support this process, we propose an image-as-map mechanism that visualizes key landmarks at each step, providing a transparent action record and enables the agent to effectively choose among action candidates. Even with a simple region selection strategy, we observe significant performance gains of 28+\% on Screenspot-pro and 24+\% on WebVoyager benchmarks on top of two state-of-the-art open vision language model agents, UI-TARS and Qwen2.5-VL, highlighting the effectiveness of visual test-time scaling in interactive settings. We achieve a new state-of-the-art grounding performance of 61.6\% on the ScreenSpot-Pro benchmark by applying RegionFocus to a Qwen2.5-VL-72B model. Our code will be released publicly at https://github.com/tiangeluo/RegionFocus.
Process Reward Models That Think
Apr 23, 2025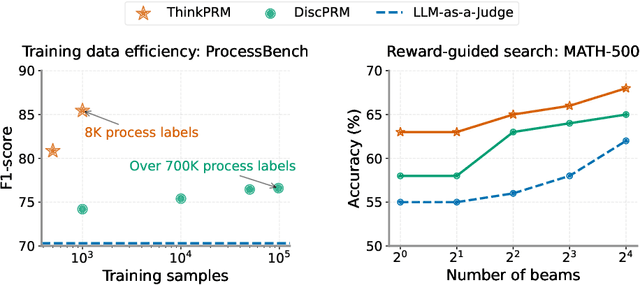
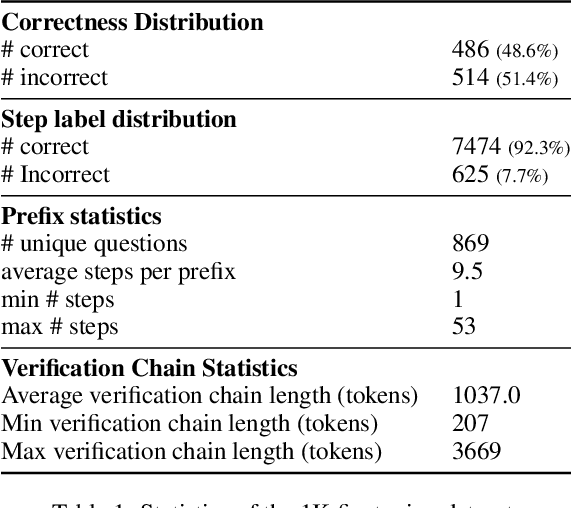
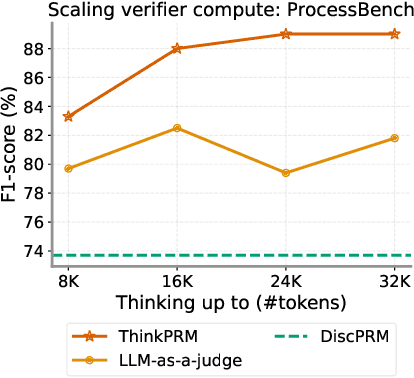
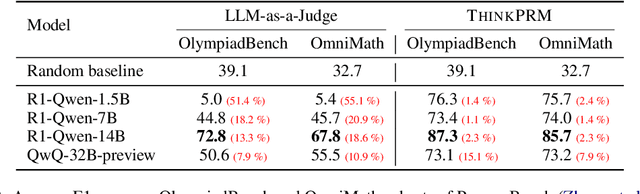
Step-by-step verifiers -- also known as process reward models (PRMs) -- are a key ingredient for test-time scaling. PRMs require step-level supervision, making them expensive to train. This work aims to build data-efficient PRMs as verbalized step-wise reward models that verify every step in the solution by generating a verification chain-of-thought (CoT). We propose ThinkPRM, a long CoT verifier fine-tuned on orders of magnitude fewer process labels than those required by discriminative PRMs. Our approach capitalizes on the inherent reasoning abilities of long CoT models, and outperforms LLM-as-a-Judge and discriminative verifiers -- using only 1% of the process labels in PRM800K -- across several challenging benchmarks. Specifically, ThinkPRM beats the baselines on ProcessBench, MATH-500, and AIME '24 under best-of-N selection and reward-guided search. In an out-of-domain evaluation on a subset of GPQA-Diamond and LiveCodeBench, our PRM surpasses discriminative verifiers trained on the full PRM800K by 8% and 4.5%, respectively. Lastly, under the same token budget, ThinkPRM scales up verification compute more effectively compared to LLM-as-a-Judge, outperforming it by 7.2% on a subset of ProcessBench. Our work highlights the value of generative, long CoT PRMs that can scale test-time compute for verification while requiring minimal supervision for training. Our code, data, and models will be released at https://github.com/mukhal/thinkprm.
MLRC-Bench: Can Language Agents Solve Machine Learning Research Challenges?
Apr 13, 2025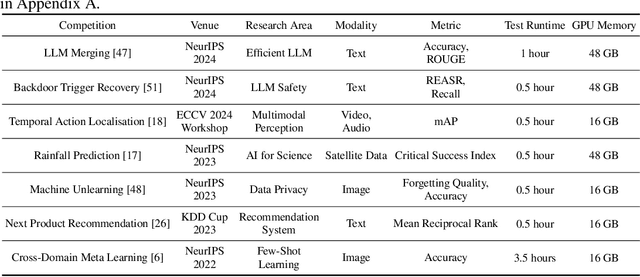
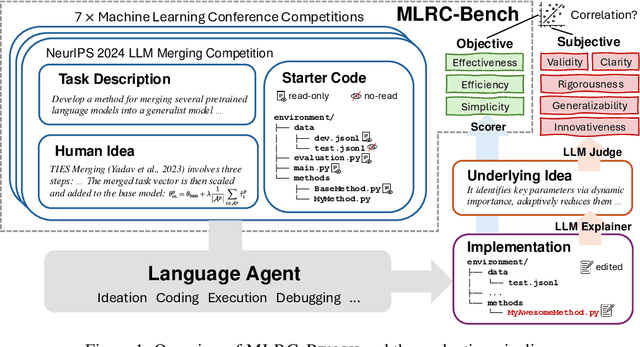
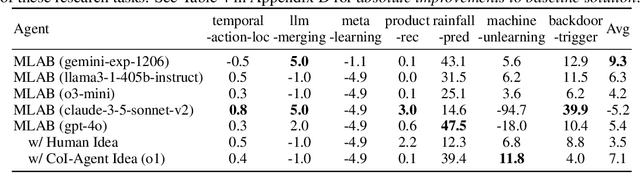
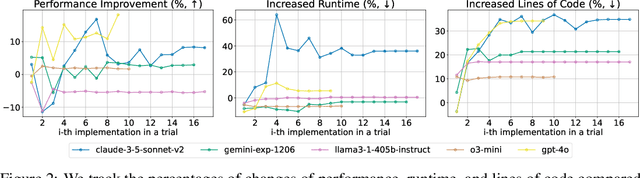
Existing evaluation of large language model (LLM) agents on scientific discovery lacks objective baselines and metrics to assess the viability of their proposed methods. To address this issue, we introduce MLRC-Bench, a benchmark designed to quantify how effectively language agents can tackle challenging Machine Learning (ML) Research Competitions. Our benchmark highlights open research problems that demand novel methodologies, in contrast to recent benchmarks such as OpenAI's MLE-Bench (Chan et al., 2024) and METR's RE-Bench (Wijk et al., 2024), which focus on well-established research tasks that are largely solvable through sufficient engineering effort. Unlike prior work, e.g., AI Scientist (Lu et al., 2024b), which evaluates the end-to-end agentic pipeline by using LLM-as-a-judge, MLRC-Bench measures the key steps of proposing and implementing novel research methods and evaluates them with newly proposed rigorous protocol and objective metrics. Our curated suite of 7 competition tasks reveals significant challenges for LLM agents. Even the best-performing tested agent (gemini-exp-1206 under MLAB (Huang et al., 2024a)) closes only 9.3% of the gap between baseline and top human participant scores. Furthermore, our analysis reveals a misalignment between the LLM-judged innovation and their actual performance on cutting-edge ML research problems. MLRC-Bench is a dynamic benchmark, which is designed to continually grow with new ML competitions to encourage rigorous and objective evaluations of AI's research capabilities.
Auto-Intent: Automated Intent Discovery and Self-Exploration for Large Language Model Web Agents
Oct 29, 2024



In this paper, we introduce Auto-Intent, a method to adapt a pre-trained large language model (LLM) as an agent for a target domain without direct fine-tuning, where we empirically focus on web navigation tasks. Our approach first discovers the underlying intents from target domain demonstrations unsupervisedly, in a highly compact form (up to three words). With the extracted intents, we train our intent predictor to predict the next intent given the agent's past observations and actions. In particular, we propose a self-exploration approach where top-k probable intent predictions are provided as a hint to the pre-trained LLM agent, which leads to enhanced decision-making capabilities. Auto-Intent substantially improves the performance of GPT-{3.5, 4} and Llama-3.1-{70B, 405B} agents on the large-scale real-website navigation benchmarks from Mind2Web and online navigation tasks from WebArena with its cross-benchmark generalization from Mind2Web.
SPRIG: Improving Large Language Model Performance by System Prompt Optimization
Oct 18, 2024Large Language Models (LLMs) have shown impressive capabilities in many scenarios, but their performance depends, in part, on the choice of prompt. Past research has focused on optimizing prompts specific to a task. However, much less attention has been given to optimizing the general instructions included in a prompt, known as a system prompt. To address this gap, we propose SPRIG, an edit-based genetic algorithm that iteratively constructs prompts from prespecified components to maximize the model's performance in general scenarios. We evaluate the performance of system prompts on a collection of 47 different types of tasks to ensure generalizability. Our study finds that a single optimized system prompt performs on par with task prompts optimized for each individual task. Moreover, combining system and task-level optimizations leads to further improvement, which showcases their complementary nature. Experiments also reveal that the optimized system prompts generalize effectively across model families, parameter sizes, and languages. This study provides insights into the role of system-level instructions in maximizing LLM potential.