 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXAONE 4.0: Unified Large Language Models Integrating Non-reasoning and Reasoning Modes
Jul 15, 2025This technical report introduces EXAONE 4.0, which integrates a Non-reasoning mode and a Reasoning mode to achieve both the excellent usability of EXAONE 3.5 and the advanced reasoning abilities of EXAONE Deep. To pave the way for the agentic AI era, EXAONE 4.0 incorporates essential features such as agentic tool use, and its multilingual capabilities are extended to support Spanish in addition to English and Korean. The EXAONE 4.0 model series consists of two sizes: a mid-size 32B model optimized for high performance, and a small-size 1.2B model designed for on-device applications. The EXAONE 4.0 demonstrates superior performance compared to open-weight models in its class and remains competitive even against frontier-class models. The models are publicly available for research purposes and can be easily downloaded via https://huggingface.co/LGAI-EXAONE.
Geometric Embedding Alignment via Curvature Matching in Transfer Learning
Jun 16, 2025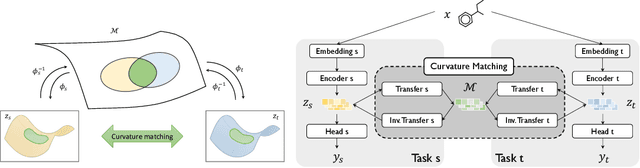

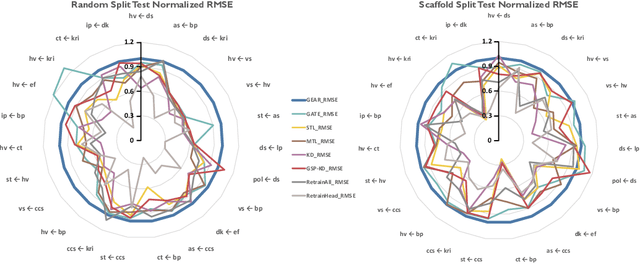

Geometrical interpretations of deep learning models offer insightful perspectives into their underlying mathematical structures. In this work, we introduce a novel approach that leverages differential geometry, particularly concepts from Riemannian geometry, to integrate multiple models into a unified transfer learning framework. By aligning the Ricci curvature of latent space of individual models, we construct an interrelated architecture, namely Geometric Embedding Alignment via cuRvature matching in transfer learning (GEAR), which ensures comprehensive geometric representation across datapoints. This framework enables the effective aggregation of knowledge from diverse sources, thereby improving performance on target tasks. We evaluate our model on 23 molecular task pairs sourced from various domains and demonstrate significant performance gains over existing benchmark model under both random (14.4%) and scaffold (8.3%) data splits.
LG-ANNA-Embedding technical report
Jun 09, 2025This report presents a unified instruction-based framework for learning generalized text embeddings optimized for both information retrieval (IR) and non-IR tasks. Built upon a decoder-only large language model (Mistral-7B), our approach combines in-context learning, soft supervision, and adaptive hard-negative mining to generate context-aware embeddings without task-specific fine-tuning. Structured instructions and few-shot examples are used to guide the model across diverse tasks, enabling strong performance on classification, semantic similarity, clustering, and reranking benchmarks. To improve semantic discrimination, we employ a soft labeling framework where continuous relevance scores, distilled from a high-performance dense retriever and reranker, serve as fine-grained supervision signals. In addition, we introduce adaptive margin-based hard-negative mining, which filters out semantically ambiguous negatives based on their similarity to positive examples, thereby enhancing training stability and retrieval robustness. Our model is evaluated on the newly introduced MTEB (English, v2) benchmark, covering 41 tasks across seven categories. Results show that our method achieves strong generalization and ranks among the top-performing models by Borda score, outperforming several larger or fully fine-tuned baselines. These findings highlight the effectiveness of combining in-context prompting, soft supervision, and adaptive sampling for scalable, high-quality embedding generation.
SafeDPO: A Simple Approach to Direct Preference Optimization with Enhanced Safety
May 26, 2025As Large Language Models (LLMs) continue to advance and find applications across a growing number of fields, ensuring the safety of LLMs has become increasingly critical. To address safety concerns, recent studies have proposed integrating safety constraints into Reinforcement Learning from Human Feedback (RLHF). However, these approaches tend to be complex, as they encompass complicated procedures in RLHF along with additional steps required by the safety constraints. Inspired by Direct Preference Optimization (DPO), we introduce a new algorithm called SafeDPO, which is designed to directly optimize the safety alignment objective in a single stage of policy learning, without requiring relaxation. SafeDPO introduces only one additional hyperparameter to further enhance safety and requires only minor modifications to standard DPO. As a result, it eliminates the need to fit separate reward and cost models or to sample from the language model during fine-tuning, while still enhancing the safety of LLMs. Finally, we demonstrate that SafeDPO achieves competitive performance compared to state-of-the-art safety alignment algorithms, both in terms of aligning with human preferences and improving safety.
Scalable Video-to-Dataset Generation for Cross-Platform Mobile Agents
May 19, 2025Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have sparked significant interest in developing GUI visual agents. We introduce MONDAY (Mobile OS Navigation Task Dataset for Agents from YouTube), a large-scale dataset of 313K annotated frames from 20K instructional videos capturing diverse real-world mobile OS navigation across multiple platforms. Models that include MONDAY in their pre-training phases demonstrate robust cross-platform generalization capabilities, consistently outperforming models trained on existing single OS datasets while achieving an average performance gain of 18.11%p on an unseen mobile OS platform. To enable continuous dataset expansion as mobile platforms evolve, we present an automated framework that leverages publicly available video content to create comprehensive task datasets without manual annotation. Our framework comprises robust OCR-based scene detection (95.04% F1score), near-perfect UI element detection (99.87% hit ratio), and novel multi-step action identification to extract reliable action sequences across diverse interface configurations. We contribute both the MONDAY dataset and our automated collection framework to facilitate future research in mobile OS navigation.
MolMole: Molecule Mining from Scientific Literature
May 08, 2025The extraction of molecular structures and reaction data from scientific documents is challenging due to their varied, unstructured chemical formats and complex document layouts. To address this, we introduce MolMole, a vision-based deep learning framework that unifies molecule detection, reaction diagram parsing, and optical chemical structure recognition (OCSR) into a single pipeline for automating the extraction of chemical data directly from page-level documents. Recognizing the lack of a standard page-level benchmark and evaluation metric, we also present a testset of 550 pages annotated with molecule bounding boxes, reaction labels, and MOLfiles, along with a novel evaluation metric. Experimental results demonstrate that MolMole outperforms existing toolkits on both our benchmark and public datasets. The benchmark testset will be publicly available, and the MolMole toolkit will be accessible soon through an interactive demo on the LG AI Research website. For commercial inquiries, please contact us at \href{mailto:contact_ddu@lgresearch.ai}{contact\_ddu@lgresearch.ai}.
EXAONE Deep: Reasoning Enhanced Language Models
Mar 16, 2025We present EXAONE Deep series, which exhibits superior capabilities in various reasoning tasks, including math and coding benchmarks. We train our models mainly on the reasoning-specialized dataset that incorporates long streams of thought processes. Evaluation results show that our smaller models, EXAONE Deep 2.4B and 7.8B, outperform other models of comparable size, while the largest model, EXAONE Deep 32B, demonstrates competitive performance against leading open-weight models. All EXAONE Deep models are openly available for research purposes and can be downloaded from https://huggingface.co/LGAI-EXAONE
Do Not Trust Licenses You See -- Dataset Compliance Requires Massive-Scale AI-Powered Lifecycle Tracing
Mar 04, 2025This paper argues that a dataset's legal risk cannot be accurately assessed by its license terms alone; instead, tracking dataset redistribution and its full lifecycle is essential. However, this process is too complex for legal experts to handle manually at scale. Tracking dataset provenance, verifying redistribution rights, and assessing evolving legal risks across multiple stages require a level of precision and efficiency that exceeds human capabilities. Addressing this challenge effectively demands AI agents that can systematically trace dataset redistribution, analyze compliance, and identify legal risks. We develop an automated data compliance system called NEXUS and show that AI can perform these tasks with higher accuracy, efficiency, and cost-effectiveness than human experts. Our massive legal analysis of 17,429 unique entities and 8,072 license terms using this approach reveals the discrepancies in legal rights between the original datasets before redistribution and their redistributed subsets, underscoring the necessity of the data lifecycle-aware compliance. For instance, we find that out of 2,852 datasets with commercially viable individual license terms, only 605 (21%) are legally permissible for commercialization. This work sets a new standard for AI data governance, advocating for a framework that systematically examines the entire lifecycle of dataset redistribution to ensure transparent, legal, and responsible dataset management.
Mol-LLM: Generalist Molecular LLM with Improved Graph Utilization
Feb 05, 2025



Recent advances in Large Language Models (LLMs) have motivated the development of general LLMs for molecular tasks. While several studies have demonstrated that fine-tuned LLMs can achieve impressive benchmark performances, they are far from genuine generalist molecular LLMs due to a lack of fundamental understanding of molecular structure. Specifically, when given molecular task instructions, LLMs trained with naive next-token prediction training assign similar likelihood scores to both original and negatively corrupted molecules, revealing their lack of molecular structure understanding that is crucial for reliable and general molecular LLMs. To overcome this limitation and obtain a true generalist molecular LLM, we introduce a novel multi-modal training method based on a thorough multi-modal instruction tuning as well as a molecular structure preference optimization between chosen and rejected graphs. On various molecular benchmarks, the proposed generalist molecular LLM, called Mol-LLM, achieves state-of-the-art performances among generalist LLMs on most tasks, at the same time, surpassing or comparable to state-of-the-art specialist LLMs. Moreover, Mol-LLM also shows superior generalization performances in reaction prediction tasks, demonstrating the effect of the molecular structure understanding for generalization perspective.
EXAONE 3.5: Series of Large Language Models for Real-world Use Cases
Dec 09, 2024



This technical report introduces the EXAONE 3.5 instruction-tuned language models, developed and released by LG AI Research. The EXAONE 3.5 language models are offered in three configurations: 32B, 7.8B, and 2.4B. These models feature several standout capabilities: 1) exceptional instruction following capabilities in real-world scenarios, achieving the highest scores across seven benchmarks, 2) outstanding long-context comprehension, attaining the top performance in four benchmarks, and 3) competitive results compared to state-of-the-art open models of similar sizes across nine general benchmarks. The EXAONE 3.5 language models are open to anyone for research purposes and can be downloaded from https://huggingface.co/LGAI-EXAONE. For commercial use, please reach out to the official contact point of LG AI Research: contact_us@lgresearch.ai.