 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLG-ANNA-Embedding technical report
Jun 09, 2025This report presents a unified instruction-based framework for learning generalized text embeddings optimized for both information retrieval (IR) and non-IR tasks. Built upon a decoder-only large language model (Mistral-7B), our approach combines in-context learning, soft supervision, and adaptive hard-negative mining to generate context-aware embeddings without task-specific fine-tuning. Structured instructions and few-shot examples are used to guide the model across diverse tasks, enabling strong performance on classification, semantic similarity, clustering, and reranking benchmarks. To improve semantic discrimination, we employ a soft labeling framework where continuous relevance scores, distilled from a high-performance dense retriever and reranker, serve as fine-grained supervision signals. In addition, we introduce adaptive margin-based hard-negative mining, which filters out semantically ambiguous negatives based on their similarity to positive examples, thereby enhancing training stability and retrieval robustness. Our model is evaluated on the newly introduced MTEB (English, v2) benchmark, covering 41 tasks across seven categories. Results show that our method achieves strong generalization and ranks among the top-performing models by Borda score, outperforming several larger or fully fine-tuned baselines. These findings highlight the effectiveness of combining in-context prompting, soft supervision, and adaptive sampling for scalable, high-quality embedding generation.
INSTRUCTIR: A Benchmark for Instruction Following of Information Retrieval Models
Feb 22, 2024Despite the critical need to align search targets with users' intention, retrievers often only prioritize query information without delving into the users' intended search context. Enhancing the capability of retrievers to understand intentions and preferences of users, akin to language model instructions, has the potential to yield more aligned search targets. Prior studies restrict the application of instructions in information retrieval to a task description format, neglecting the broader context of diverse and evolving search scenarios. Furthermore, the prevailing benchmarks utilized for evaluation lack explicit tailoring to assess instruction-following ability, thereby hindering progress in this field. In response to these limitations, we propose a novel benchmark,INSTRUCTIR, specifically designed to evaluate instruction-following ability in information retrieval tasks. Our approach focuses on user-aligned instructions tailored to each query instance, reflecting the diverse characteristics inherent in real-world search scenarios. Through experimental analysis, we observe that retrievers fine-tuned to follow task-style instructions, such as INSTRUCTOR, can underperform compared to their non-instruction-tuned counterparts. This underscores potential overfitting issues inherent in constructing retrievers trained on existing instruction-aware retrieval datasets.
ANNA: Enhanced Language Representation for Question Answering
Apr 04, 2022
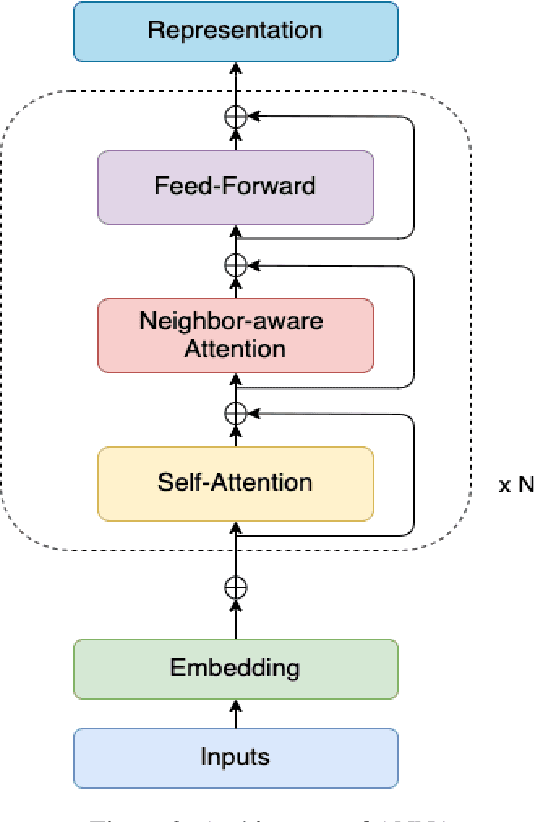
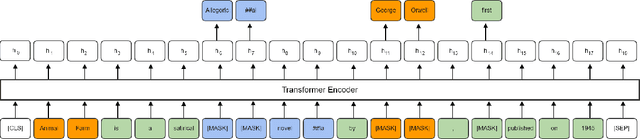
Pre-trained language models have brought significant improvements in performance in a variety of natural language processing tasks. Most existing models performing state-of-the-art results have shown their approaches in the separate perspectives of data processing, pre-training tasks, neural network modeling, or fine-tuning. In this paper, we demonstrate how the approaches affect performance individually, and that the language model performs the best results on a specific question answering task when those approaches are jointly considered in pre-training models. In particular, we propose an extended pre-training task, and a new neighbor-aware mechanism that attends neighboring tokens more to capture the richness of context for pre-training language modeling. Our best model achieves new state-of-the-art results of 95.7\% F1 and 90.6\% EM on SQuAD 1.1 and also outperforms existing pre-trained language models such as RoBERTa, ALBERT, ELECTRA, and XLNet on the SQuAD 2.0 benchmark.
* 11 pages, 3 figures
Korean-Specific Dataset for Table Question Answering
Jan 17, 2022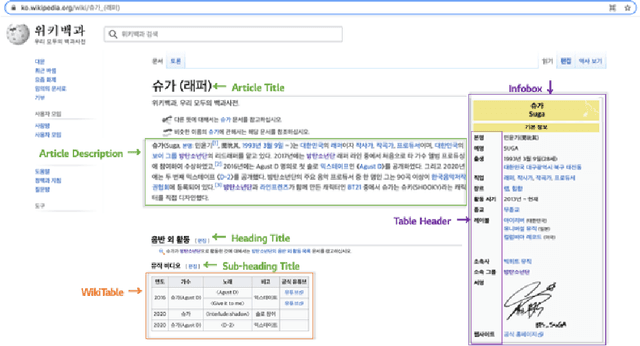
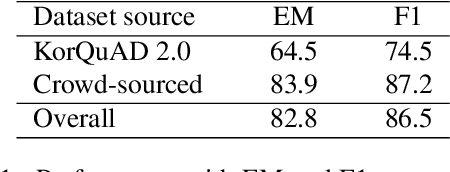

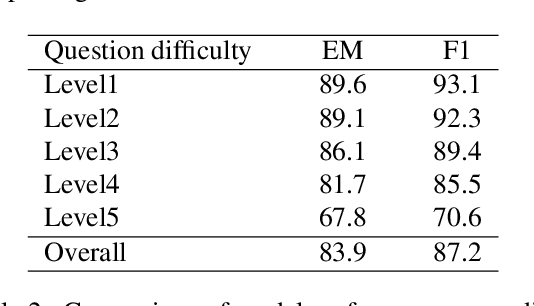
Existing question answering systems mainly focus on dealing with text data. However, much of the data produced daily is stored in the form of tables that can be found in documents and relational databases, or on the web. To solve the task of question answering over tables, there exist many datasets for table question answering written in English, but few Korean datasets. In this paper, we demonstrate how we construct Korean-specific datasets for table question answering: Korean tabular dataset is a collection of 1.4M tables with corresponding descriptions for unsupervised pre-training language models. Korean table question answering corpus consists of 70k pairs of questions and answers created by crowd-sourced workers. Subsequently, we then build a pre-trained language model based on Transformer, and fine-tune the model for table question answering with these datasets. We then report the evaluation results of our model. We make our datasets publicly available via our GitHub repository, and hope that those datasets will help further studies for question answering over tables, and for transformation of table formats.