 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Vocabulary Mismatch: Vocabulary-agnostic Teacher Guided Language Modeling
Mar 24, 2025Using large teacher models to guide the training of smaller student models has become the prevailing paradigm for efficient and effective learning. However, vocabulary mismatches between teacher and student language models pose significant challenges in language modeling, resulting in divergent token sequences and output distributions. To overcome these limitations, we propose Vocabulary-agnostic Teacher Guided Language Modeling (VocAgnoLM), a novel approach that bridges the gap caused by vocabulary mismatch through two key methods: (1) Token-level Lexical Alignment, which aligns token sequences across mismatched vocabularies, and (2) Teacher Guided Loss, which leverages the loss of teacher model to guide effective student training. We demonstrate its effectiveness in language modeling with 1B student model using various 7B teacher models with different vocabularies. Notably, with Qwen2.5-Math-Instruct, a teacher model sharing only about 6% of its vocabulary with TinyLlama, VocAgnoLM achieves a 46% performance improvement compared to naive continual pretraining. Furthermore, we demonstrate that VocAgnoLM consistently benefits from stronger teacher models, providing a robust solution to vocabulary mismatches in language modeling.
Generative Context Distillation
Nov 24, 2024Prompts used in recent large language model based applications are often fixed and lengthy, leading to significant computational overhead. To address this challenge, we propose Generative Context Distillation (GCD), a lightweight prompt internalization method that employs a joint training approach. This method not only replicates the behavior of models with prompt inputs but also generates the content of the prompt along with reasons for why the model's behavior should change accordingly. We demonstrate that our approach effectively internalizes complex prompts across various agent-based application scenarios. For effective training without interactions with the dedicated environments, we introduce a data synthesis technique that autonomously collects conversational datasets by swapping the roles of the agent and environment. This method is especially useful in scenarios where only a predefined prompt is available without a corresponding training dataset. By internalizing complex prompts, Generative Context Distillation enables high-performance and efficient inference without the need for explicit prompts.
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Jun 09, 2024



As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
INSTRUCTIR: A Benchmark for Instruction Following of Information Retrieval Models
Feb 22, 2024Despite the critical need to align search targets with users' intention, retrievers often only prioritize query information without delving into the users' intended search context. Enhancing the capability of retrievers to understand intentions and preferences of users, akin to language model instructions, has the potential to yield more aligned search targets. Prior studies restrict the application of instructions in information retrieval to a task description format, neglecting the broader context of diverse and evolving search scenarios. Furthermore, the prevailing benchmarks utilized for evaluation lack explicit tailoring to assess instruction-following ability, thereby hindering progress in this field. In response to these limitations, we propose a novel benchmark,INSTRUCTIR, specifically designed to evaluate instruction-following ability in information retrieval tasks. Our approach focuses on user-aligned instructions tailored to each query instance, reflecting the diverse characteristics inherent in real-world search scenarios. Through experimental analysis, we observe that retrievers fine-tuned to follow task-style instructions, such as INSTRUCTOR, can underperform compared to their non-instruction-tuned counterparts. This underscores potential overfitting issues inherent in constructing retrievers trained on existing instruction-aware retrieval datasets.
KTRL+F: Knowledge-Augmented In-Document Search
Nov 16, 2023



We introduce a new problem KTRL+F, a knowledge-augmented in-document search task that necessitates real-time identification of all semantic targets within a document with the awareness of external sources through a single natural query. This task addresses following unique challenges for in-document search: 1) utilizing knowledge outside the document for extended use of additional information about targets to bridge the semantic gap between the query and the targets, and 2) balancing between real-time applicability with the performance. We analyze various baselines in KTRL+F and find there are limitations of existing models, such as hallucinations, low latency, or difficulties in leveraging external knowledge. Therefore we propose a Knowledge-Augmented Phrase Retrieval model that shows a promising balance between speed and performance by simply augmenting external knowledge embedding in phrase embedding. Additionally, we conduct a user study to verify whether solving KTRL+F can enhance search experience of users. It demonstrates that even with our simple model users can reduce the time for searching with less queries and reduced extra visits to other sources for collecting evidence. We encourage the research community to work on KTRL+F to enhance more efficient in-document information access.
Intuitive Access to Smartphone Settings Using Relevance Model Trained by Contrastive Learning
Jul 15, 2023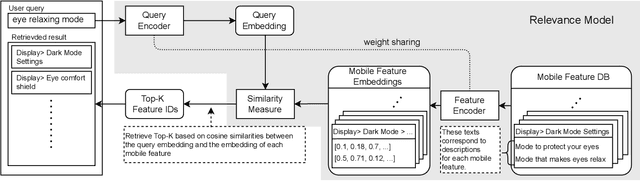
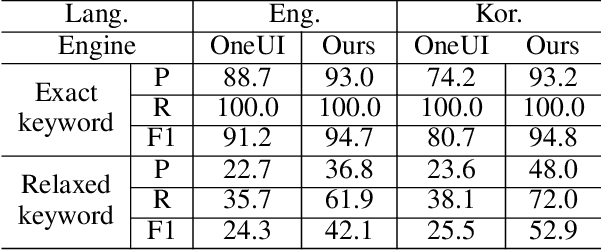
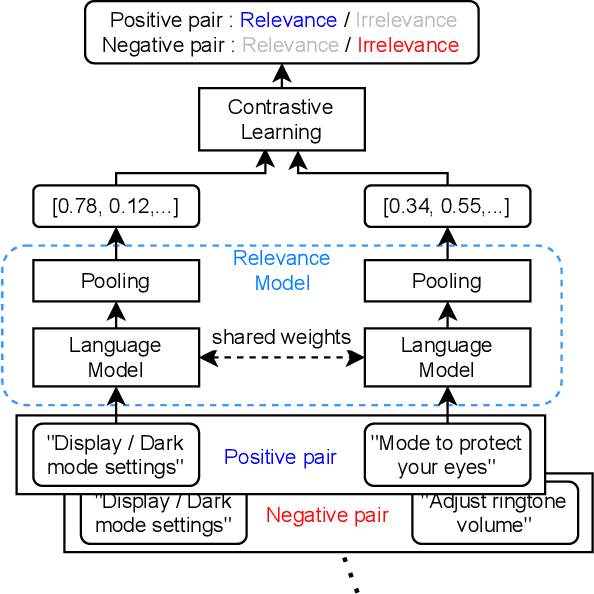

The more new features that are being added to smartphones, the harder it becomes for users to find them. This is because the feature names are usually short, and there are just too many to remember. In such a case, the users may want to ask contextual queries that describe the features they are looking for, but the standard term frequency-based search cannot process them. This paper presents a novel retrieval system for mobile features that accepts intuitive and contextual search queries. We trained a relevance model via contrastive learning from a pre-trained language model to perceive the contextual relevance between query embeddings and indexed mobile features. Also, to make it run efficiently on-device using minimal resources, we applied knowledge distillation to compress the model without degrading much performance. To verify the feasibility of our method, we collected test queries and conducted comparative experiments with the currently deployed search baselines. The results show that our system outperforms the others on contextual sentence queries and even on usual keyword-based queries.