 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Informed Grounding Supervision
Jun 18, 2025Large language models (LLMs) are often supplemented with external knowledge to provide information not encoded in their parameters or to reduce hallucination. In such cases, we expect the model to generate responses by grounding its response in the provided external context. However, prior work has shown that simply appending context at inference time does not ensure grounded generation. To address this, we propose Context-INformed Grounding Supervision (CINGS), a post-training supervision in which the model is trained with relevant context prepended to the response, while computing the loss only over the response tokens and masking out the context. Our experiments demonstrate that models trained with CINGS exhibit stronger grounding in both textual and visual domains compared to standard instruction-tuned models. In the text domain, CINGS outperforms other training methods across 11 information-seeking datasets and is complementary to inference-time grounding techniques. In the vision-language domain, replacing a vision-language model's LLM backbone with a CINGS-trained model reduces hallucinations across four benchmarks and maintains factual consistency throughout the generated response. This improved grounding comes without degradation in general downstream performance. Finally, we analyze the mechanism underlying the enhanced grounding in CINGS and find that it induces a shift in the model's prior knowledge and behavior, implicitly encouraging greater reliance on the external context.
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Jun 09, 2024



As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
INSTRUCTIR: A Benchmark for Instruction Following of Information Retrieval Models
Feb 22, 2024Despite the critical need to align search targets with users' intention, retrievers often only prioritize query information without delving into the users' intended search context. Enhancing the capability of retrievers to understand intentions and preferences of users, akin to language model instructions, has the potential to yield more aligned search targets. Prior studies restrict the application of instructions in information retrieval to a task description format, neglecting the broader context of diverse and evolving search scenarios. Furthermore, the prevailing benchmarks utilized for evaluation lack explicit tailoring to assess instruction-following ability, thereby hindering progress in this field. In response to these limitations, we propose a novel benchmark,INSTRUCTIR, specifically designed to evaluate instruction-following ability in information retrieval tasks. Our approach focuses on user-aligned instructions tailored to each query instance, reflecting the diverse characteristics inherent in real-world search scenarios. Through experimental analysis, we observe that retrievers fine-tuned to follow task-style instructions, such as INSTRUCTOR, can underperform compared to their non-instruction-tuned counterparts. This underscores potential overfitting issues inherent in constructing retrievers trained on existing instruction-aware retrieval datasets.
KTRL+F: Knowledge-Augmented In-Document Search
Nov 16, 2023



We introduce a new problem KTRL+F, a knowledge-augmented in-document search task that necessitates real-time identification of all semantic targets within a document with the awareness of external sources through a single natural query. This task addresses following unique challenges for in-document search: 1) utilizing knowledge outside the document for extended use of additional information about targets to bridge the semantic gap between the query and the targets, and 2) balancing between real-time applicability with the performance. We analyze various baselines in KTRL+F and find there are limitations of existing models, such as hallucinations, low latency, or difficulties in leveraging external knowledge. Therefore we propose a Knowledge-Augmented Phrase Retrieval model that shows a promising balance between speed and performance by simply augmenting external knowledge embedding in phrase embedding. Additionally, we conduct a user study to verify whether solving KTRL+F can enhance search experience of users. It demonstrates that even with our simple model users can reduce the time for searching with less queries and reduced extra visits to other sources for collecting evidence. We encourage the research community to work on KTRL+F to enhance more efficient in-document information access.
Zero-Shot Dense Video Captioning by Jointly Optimizing Text and Moment
Jul 11, 2023Dense video captioning, a task of localizing meaningful moments and generating relevant captions for videos, often requires a large, expensive corpus of annotated video segments paired with text. In an effort to minimize the annotation cost, we propose ZeroTA, a novel method for dense video captioning in a zero-shot manner. Our method does not require any videos or annotations for training; instead, it localizes and describes events within each input video at test time by optimizing solely on the input. This is accomplished by introducing a soft moment mask that represents a temporal segment in the video and jointly optimizing it with the prefix parameters of a language model. This joint optimization aligns a frozen language generation model (i.e., GPT-2) with a frozen vision-language contrastive model (i.e., CLIP) by maximizing the matching score between the generated text and a moment within the video. We also introduce a pairwise temporal IoU loss to let a set of soft moment masks capture multiple distinct events within the video. Our method effectively discovers diverse significant events within the video, with the resulting captions appropriately describing these events. The empirical results demonstrate that ZeroTA surpasses zero-shot baselines and even outperforms the state-of-the-art few-shot method on the widely-used benchmark ActivityNet Captions. Moreover, our method shows greater robustness compared to supervised methods when evaluated in out-of-domain scenarios. This research provides insight into the potential of aligning widely-used models, such as language generation models and vision-language models, to unlock a new capability: understanding temporal aspects of videos.
Contextualized Generative Retrieval
Oct 07, 2022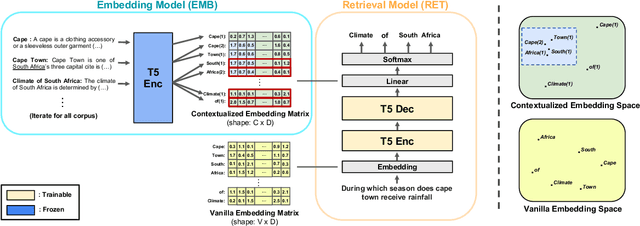
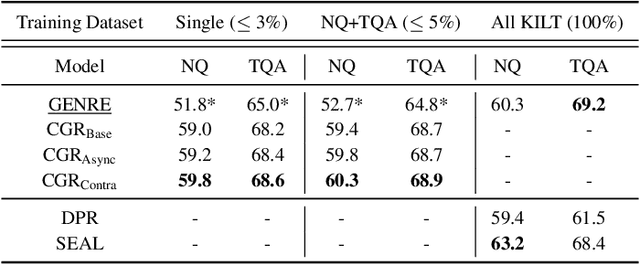
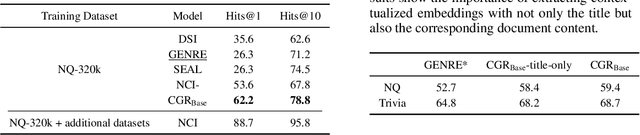
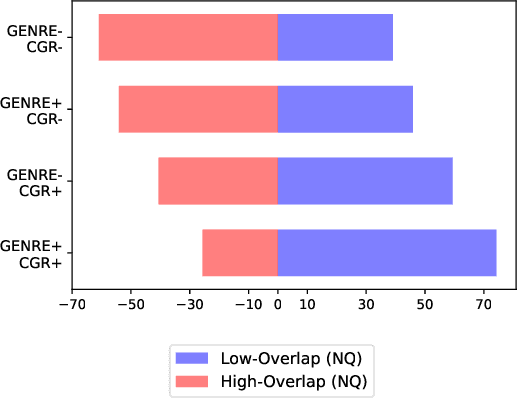
The text retrieval task is mainly performed in two ways: the bi-encoder approach and the generative approach. The bi-encoder approach maps the document and query embeddings to common vector space and performs a nearest neighbor search. It stably shows high performance and efficiency across different domains but has an embedding space bottleneck as it interacts in L2 or inner product space. The generative retrieval model retrieves by generating a target sequence and overcomes the embedding space bottleneck by interacting in the parametric space. However, it fails to retrieve the information it has not seen during the training process as it depends solely on the information encoded in its own model parameters. To leverage the advantages of both approaches, we propose Contextualized Generative Retrieval model, which uses contextualized embeddings (output embeddings of a language model encoder) as vocab embeddings at the decoding step of generative retrieval. The model uses information encoded in both the non-parametric space of contextualized token embeddings and the parametric space of the generative retrieval model. Our approach of generative retrieval with contextualized vocab embeddings shows higher performance than generative retrieval with only vanilla vocab embeddings in the document retrieval task, an average of 6% higher performance in KILT (NQ, TQA) and 2X higher in NQ-320k, suggesting the benefits of using contextualized embedding in generative retrieval models.
Generative Retrieval for Long Sequences
Apr 27, 2022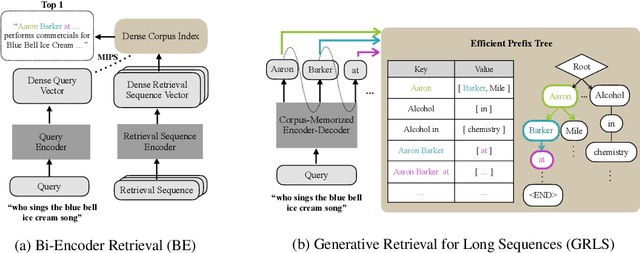
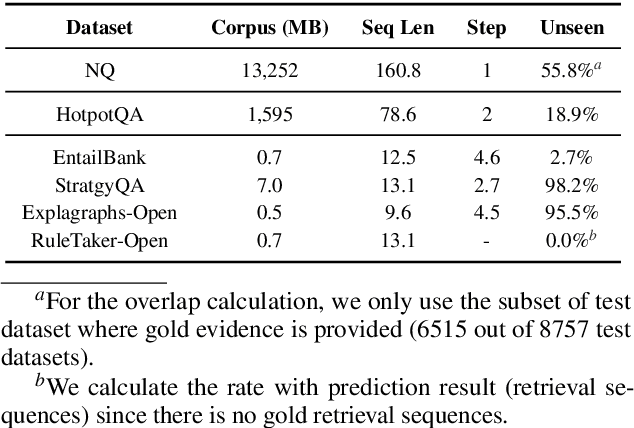
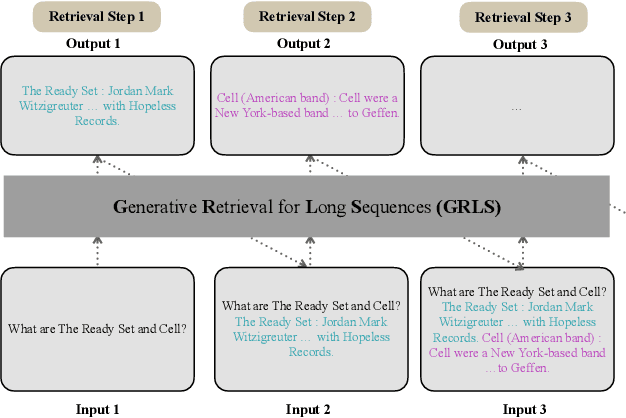
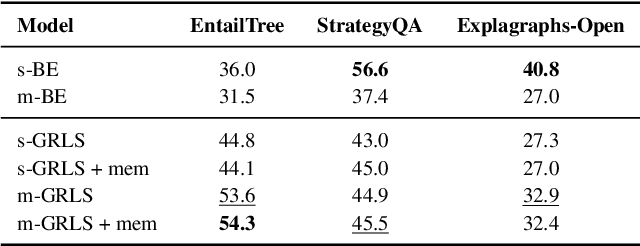
Text retrieval is often formulated as mapping the query and the target items (e.g., passages) to the same vector space and finding the item whose embedding is closest to that of the query. In this paper, we explore a generative approach as an alternative, where we use an encoder-decoder model to memorize the target corpus in a generative manner and then finetune it on query-to-passage generation. As GENRE(Cao et al., 2021) has shown that entities can be retrieved in a generative way, our work can be considered as its generalization to longer text. We show that it consistently achieves comparable performance to traditional bi-encoder retrieval on diverse datasets and is especially strong at retrieving highly structured items, such as reasoning chains and graph relations, while demonstrating superior GPU memory and time complexity. We also conjecture that generative retrieval is complementary to traditional retrieval, as we find that an ensemble of both outperforms homogeneous ensembles.
ViSeRet: A simple yet effective approach to moment retrieval via fine-grained video segmentation
Oct 12, 2021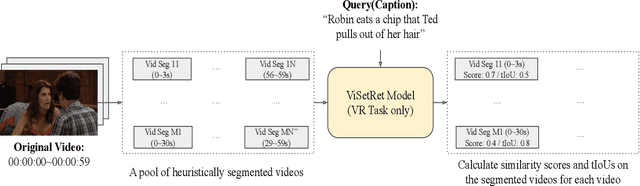

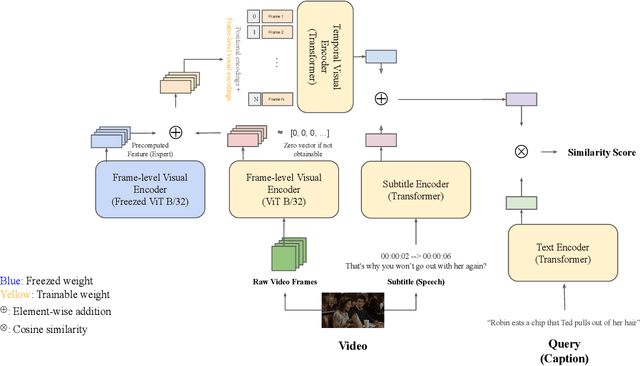

Video-text retrieval has many real-world applications such as media analytics, surveillance, and robotics. This paper presents the 1st place solution to the video retrieval track of the ICCV VALUE Challenge 2021. We present a simple yet effective approach to jointly tackle two video-text retrieval tasks (video retrieval and video corpus moment retrieval) by leveraging the model trained only on the video retrieval task. In addition, we create an ensemble model that achieves the new state-of-the-art performance on all four datasets (TVr, How2r, YouCook2r, and VATEXr) presented in the VALUE Challenge.