 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-BrowseComp: A Web Browsing Agent Benchmark Grounded in Korean Contexts
Jun 01, 2026Frontier model evaluations are shifting from foundational capabilities (e.g., instruction following and reasoning) toward compositional, agentic ones, but Korean agentic benchmarks remain scarce. We introduce K-BrowseComp, a web-browsing agent benchmark grounded in Korean contexts, consisting of 400 problems. The 300-problem K-BrowseComp-Verified subset is manually constructed and validated by native Korean speakers. On this subset, frontier LLMs, including GPT-5.5, DeepSeek-V4-Pro, and GLM-5.1, reach only 30.00--45.67\%, a substantial drop from BrowseComp, while Korean LLMs released through Korea's Proprietary AI Foundation Model program obtain only 0.00--10.33\%. We further construct a 100-problem synthetic split using hard few-shot exemplars and failure-mode-targeted generation to exploit the asymmetry between solving and creating web browsing problems. On the adversarially filtered synthetic diagnostic split, the strongest model reaches only 26.00\%, and we report this split separately as a targeted stress test. We publicly release our data and code.
On the limits and opportunities of AI reviewers: Reviewing the reviews of Nature-family papers with 45 expert scientists
May 20, 2026With the advancement of AI capabilities, AI reviewers are beginning to be deployed in scientific peer review, yet their capability and credibility remain in question: many scientists simply view them as probabilistic systems without the expertise to evaluate research, while other researchers are more optimistic about their readiness without concrete evidence. Understanding what AI reviewers do well, where they fall short, and what challenges remain is essential. However, existing evaluations of AI reviewers have focused on whether their verdicts match human verdicts (e.g., score alignment, acceptance prediction), which is insufficient to characterize their capabilities and limits. In this paper, we close this gap through a large-scale expert annotation study, in which 45 domain scientists in Physical, Biological, and Health Sciences spent 469 hours rating 2,960 individual criticisms (each targeting one specific aspect of a paper) from human-written and AI-generated reviews of 82 Nature-family papers on correctness, significance, and sufficiency of evidence. On a composite of all three dimensions, a reviewing agent powered by GPT-5.2 scores above each paper's top-rated human reviewer (60.0% vs. 48.2%, p = 0.009), while all three AI reviewers (including Gemini 3.0 Pro and Claude Opus 4.5) exceed the lowest-rated human across every dimension. AI reviewers' accurate criticisms are also more often rated significant and well-evidenced, and surface a distinct 26% of issues no human raises. However, AI reviewers overlap far more than humans do (21% vs. 3% for cross-reviewer pairs), and exhibit 16 recurring weaknesses humans do not share, such as limited subfield knowledge, lack of long context management over multiple files, and overly critical stance on minor issues. Overall, our results position current AI reviewers as complements to, not substitutes for, human reviewers.
K-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
Reasoning Models Better Express Their Confidence
May 20, 2025



Despite their strengths, large language models (LLMs) often fail to communicate their confidence accurately, making it difficult to assess when they might be wrong and limiting their reliability. In this work, we demonstrate that reasoning models-LLMs that engage in extended chain-of-thought (CoT) reasoning-exhibit superior performance not only in problem-solving but also in accurately expressing their confidence. Specifically, we benchmark six reasoning models across six datasets and find that they achieve strictly better confidence calibration than their non-reasoning counterparts in 33 out of the 36 settings. Our detailed analysis reveals that these gains in calibration stem from the slow thinking behaviors of reasoning models-such as exploring alternative approaches and backtracking-which enable them to adjust their confidence dynamically throughout their CoT, making it progressively more accurate. In particular, we find that reasoning models become increasingly better calibrated as their CoT unfolds, a trend not observed in non-reasoning models. Moreover, removing slow thinking behaviors from the CoT leads to a significant drop in calibration. Lastly, we show that these gains are not exclusive to reasoning models-non-reasoning models also benefit when guided to perform slow thinking via in-context learning.
M-Prometheus: A Suite of Open Multilingual LLM Judges
Apr 07, 2025The use of language models for automatically evaluating long-form text (LLM-as-a-judge) is becoming increasingly common, yet most LLM judges are optimized exclusively for English, with strategies for enhancing their multilingual evaluation capabilities remaining largely unexplored in the current literature. This has created a disparity in the quality of automatic evaluation methods for non-English languages, ultimately hindering the development of models with better multilingual capabilities. To bridge this gap, we introduce M-Prometheus, a suite of open-weight LLM judges ranging from 3B to 14B parameters that can provide both direct assessment and pairwise comparison feedback on multilingual outputs. M-Prometheus models outperform state-of-the-art open LLM judges on multilingual reward benchmarks spanning more than 20 languages, as well as on literary machine translation (MT) evaluation covering 4 language pairs. Furthermore, M-Prometheus models can be leveraged at decoding time to significantly improve generated outputs across all 3 tested languages, showcasing their utility for the development of better multilingual models. Lastly, through extensive ablations, we identify the key factors for obtaining an effective multilingual judge, including backbone model selection and training on natively multilingual feedback data instead of translated data. We release our models, training dataset, and code.
A 2-step Framework for Automated Literary Translation Evaluation: Its Promises and Pitfalls
Dec 02, 2024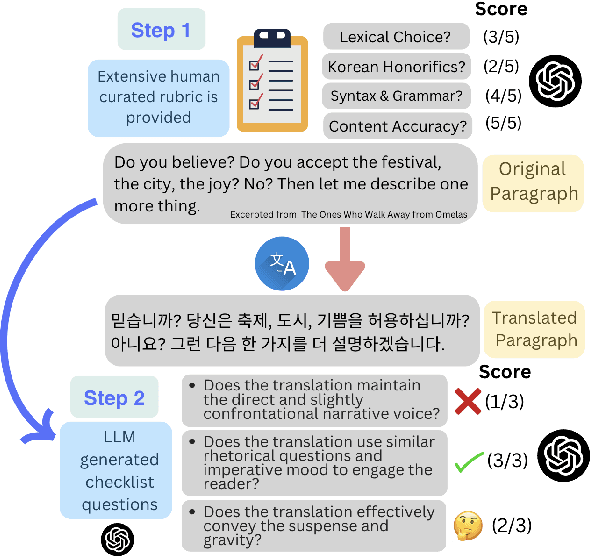
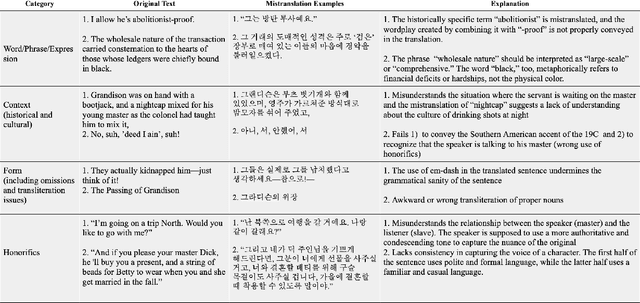
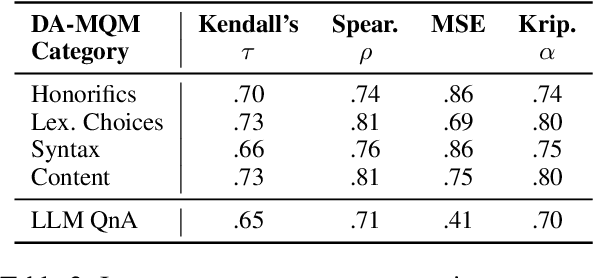
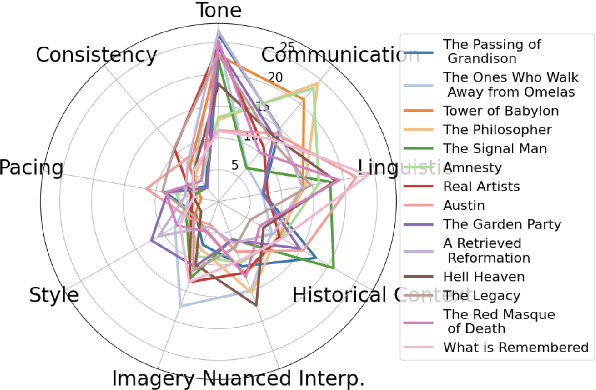
In this work, we propose and evaluate the feasibility of a two-stage pipeline to evaluate literary machine translation, in a fine-grained manner, from English to Korean. The results show that our framework provides fine-grained, interpretable metrics suited for literary translation and obtains a higher correlation with human judgment than traditional machine translation metrics. Nonetheless, it still fails to match inter-human agreement, especially in metrics like Korean Honorifics. We also observe that LLMs tend to favor translations generated by other LLMs, and we highlight the necessity of developing more sophisticated evaluation methods to ensure accurate and culturally sensitive machine translation of literary works.
MM-Eval: A Multilingual Meta-Evaluation Benchmark for LLM-as-a-Judge and Reward Models
Oct 23, 2024



Large language models (LLMs) are commonly used as evaluators in tasks (e.g., reward modeling, LLM-as-a-judge), where they act as proxies for human preferences or judgments. This leads to the need for meta-evaluation: evaluating the credibility of LLMs as evaluators. However, existing benchmarks primarily focus on English, offering limited insight into LLMs' effectiveness as evaluators in non-English contexts. To address this, we introduce MM-Eval, a multilingual meta-evaluation benchmark that covers 18 languages across six categories. MM-Eval evaluates various dimensions, including language-specific challenges like linguistics and language hallucinations. Evaluation results show that both proprietary and open-source language models have considerable room for improvement. Further analysis reveals a tendency for these models to assign middle-ground scores to low-resource languages. We publicly release our benchmark and code.
The BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Jun 09, 2024



As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
LangBridge: Multilingual Reasoning Without Multilingual Supervision
Jan 19, 2024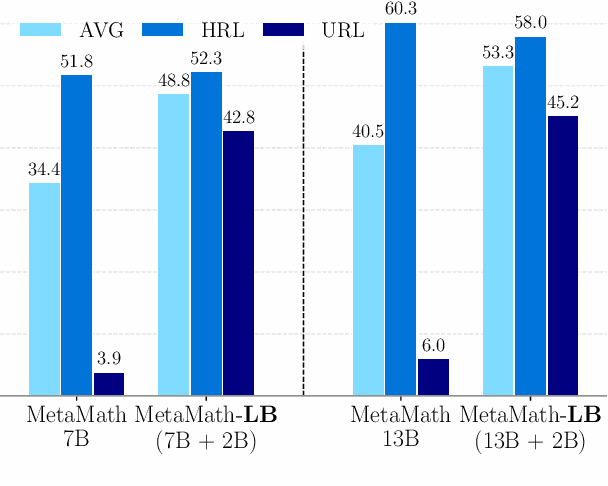
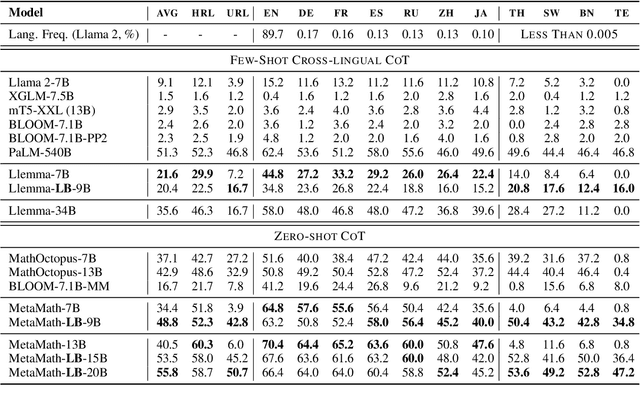

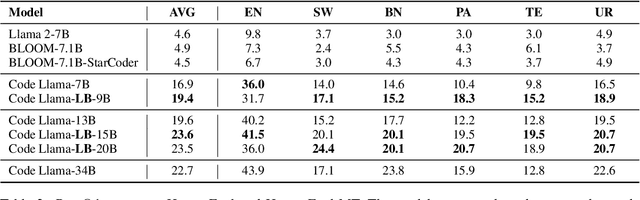
We introduce LangBridge, a zero-shot approach to adapt language models for multilingual reasoning tasks without multilingual supervision. LangBridge operates by bridging two models, each specialized in different aspects: (1) one specialized in understanding multiple languages (e.g., mT5 encoder) and (2) one specialized in reasoning (e.g., Orca 2). LangBridge connects the two models by introducing minimal trainable parameters between them. Despite utilizing only English data for training, LangBridge considerably enhances the performance of language models on low-resource languages across mathematical reasoning, coding, and logical reasoning. Our analysis suggests that the efficacy of LangBridge stems from the language-agnostic characteristics of multilingual representations. We publicly release our code and models.
Gradient Ascent Post-training Enhances Language Model Generalization
Jun 12, 2023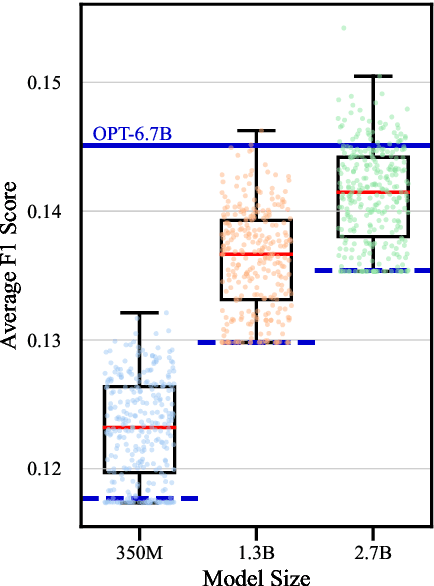
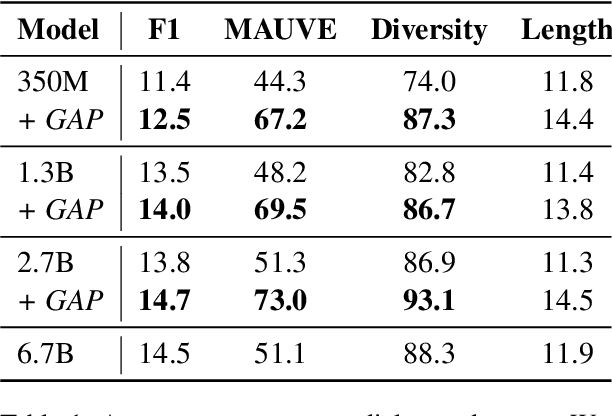
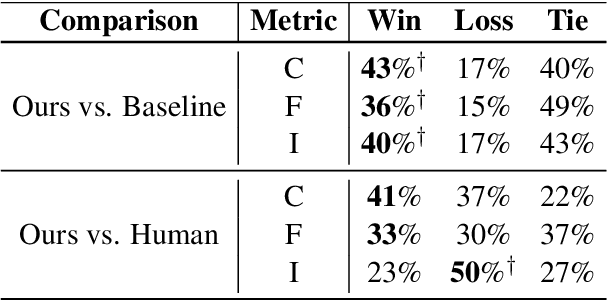
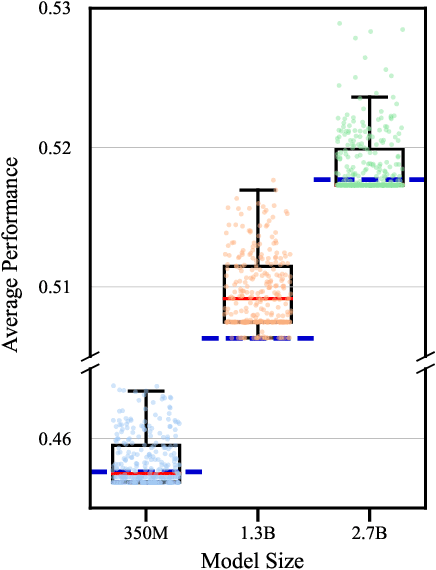
In this work, we empirically show that updating pretrained LMs (350M, 1.3B, 2.7B) with just a few steps of Gradient Ascent Post-training (GAP) on random, unlabeled text corpora enhances its zero-shot generalization capabilities across diverse NLP tasks. Specifically, we show that GAP can allow LMs to become comparable to 2-3x times larger LMs across 12 different NLP tasks. We also show that applying GAP on out-of-distribution corpora leads to the most reliable performance improvements. Our findings indicate that GAP can be a promising method for improving the generalization capability of LMs without any task-specific fine-tuning.