 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Context Distillation
Nov 24, 2024Prompts used in recent large language model based applications are often fixed and lengthy, leading to significant computational overhead. To address this challenge, we propose Generative Context Distillation (GCD), a lightweight prompt internalization method that employs a joint training approach. This method not only replicates the behavior of models with prompt inputs but also generates the content of the prompt along with reasons for why the model's behavior should change accordingly. We demonstrate that our approach effectively internalizes complex prompts across various agent-based application scenarios. For effective training without interactions with the dedicated environments, we introduce a data synthesis technique that autonomously collects conversational datasets by swapping the roles of the agent and environment. This method is especially useful in scenarios where only a predefined prompt is available without a corresponding training dataset. By internalizing complex prompts, Generative Context Distillation enables high-performance and efficient inference without the need for explicit prompts.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Ask Optimal Questions: Aligning Large Language Models with Retriever's Preference in Conversational Search
Feb 19, 2024



Conversational search, unlike single-turn retrieval tasks, requires understanding the current question within a dialogue context. The common approach of rewrite-then-retrieve aims to decontextualize questions to be self-sufficient for off-the-shelf retrievers, but most existing methods produce sub-optimal query rewrites due to the limited ability to incorporate signals from the retrieval results. To overcome this limitation, we present a novel framework RetPO (Retriever's Preference Optimization), which is designed to optimize a language model (LM) for reformulating search queries in line with the preferences of the target retrieval systems. The process begins by prompting a large LM to produce various potential rewrites and then collects retrieval performance for these rewrites as the retrievers' preferences. Through the process, we construct a large-scale dataset called RF collection, containing Retrievers' Feedback on over 410K query rewrites across 12K conversations. Furthermore, we fine-tune a smaller LM using this dataset to align it with the retrievers' preferences as feedback. The resulting model achieves state-of-the-art performance on two recent conversational search benchmarks, significantly outperforming existing baselines, including GPT-3.5.
KMMLU: Measuring Massive Multitask Language Understanding in Korean
Feb 18, 2024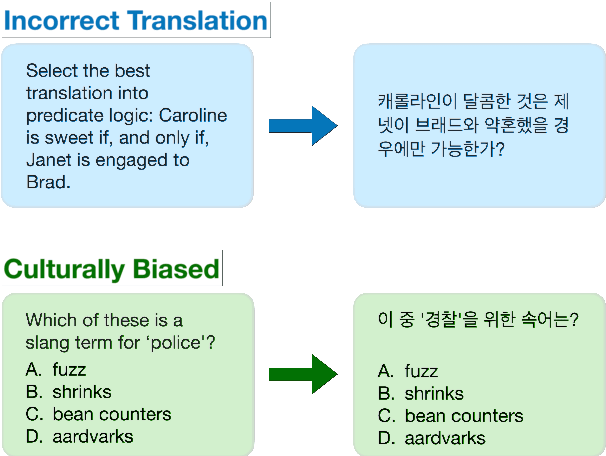



We propose KMMLU, a new Korean benchmark with 35,030 expert-level multiple-choice questions across 45 subjects ranging from humanities to STEM. Unlike previous Korean benchmarks that are translated from existing English benchmarks, KMMLU is collected from original Korean exams, capturing linguistic and cultural aspects of the Korean language. We test 26 publically available and proprietary LLMs, identifying significant room for improvement. The best publicly available model achieves 50.54% on KMMLU, far below the average human performance of 62.6%. This model was primarily trained for English and Chinese, not Korean. Current LLMs tailored to Korean, such as Polyglot-Ko, perform far worse. Surprisingly, even the most capable proprietary LLMs, e.g., GPT-4 and HyperCLOVA X, achieve 59.95% and 53.40%, respectively. This suggests that further work is needed to improve Korean LLMs, and KMMLU offers the right tool to track this progress. We make our dataset publicly available on the Hugging Face Hub and integrate the benchmark into EleutherAI's Language Model Evaluation Harness.
Aligning Large Language Models by On-Policy Self-Judgment
Feb 17, 2024To align large language models with human preferences, existing research either utilizes a separate reward model (RM) to perform on-policy learning or simplifies the training procedure by discarding the on-policy learning and the need for a separate RM. In this paper, we present a novel alignment framework, SELF-JUDGE that is (1) on-policy learning and 2) parameter efficient, as it does not require an additional RM for evaluating the samples for on-policy learning. To this end, we propose Judge-augmented Supervised Fine-Tuning (JSFT) to train a single model acting as both a policy and a judge. Specifically, we view the pairwise judgment task as a special case of the instruction-following task, choosing the better response from a response pair. Thus, the resulting model can judge preferences of on-the-fly responses from current policy initialized from itself. Experimental results show the efficacy of SELF-JUDGE, outperforming baselines in preference benchmarks. We also show that self-rejection with oversampling can improve further without an additional evaluator. Our code is available at https://github.com/oddqueue/self-judge.
Preference-free Alignment Learning with Regularized Relevance Reward
Feb 02, 2024



Learning from human preference has been considered key to aligning Large Language Models (LLMs) with human values. However, contrary to popular belief, our preliminary study reveals that reward models trained on human preference datasets tend to give higher scores to long off-topic responses than short on-topic ones. Motivated by this observation, we explore a preference-free approach utilizing `relevance' as a key objective for alignment. On our first attempt, we find that the relevance score obtained by a retriever alone is vulnerable to reward hacking, i.e., overoptimizing to undesired shortcuts, when we utilize the score as a reward for reinforcement learning. To mitigate it, we integrate effective inductive biases into the vanilla relevance to regularize each other, resulting in a mixture of reward functions: Regularized Relevance Reward ($R^3$). $R^3$ significantly improves performance on preference benchmarks by providing a robust reward signal. Notably, $R^3$ does not require any human preference datasets (i.e., preference-free), outperforming open-source reward models in improving human preference. Our analysis demonstrates that $R^3$ has advantages in elevating human preference while minimizing its side effects. Finally, we show the generalizability of $R^3$, consistently improving instruction-tuned models in various backbones and sizes without additional dataset cost. Our code is available at https://github.com/naver-ai/RRR.
LangBridge: Multilingual Reasoning Without Multilingual Supervision
Jan 19, 2024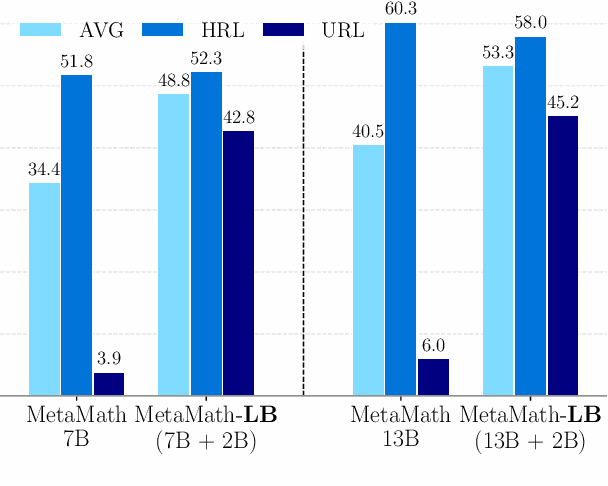
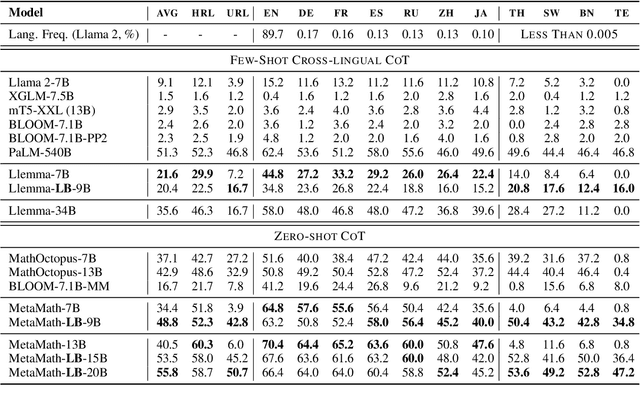

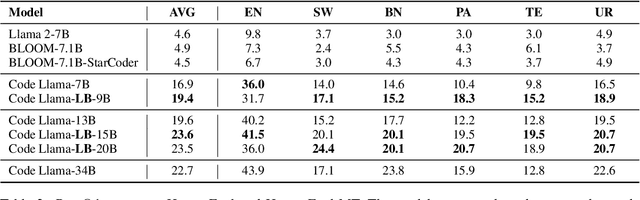
We introduce LangBridge, a zero-shot approach to adapt language models for multilingual reasoning tasks without multilingual supervision. LangBridge operates by bridging two models, each specialized in different aspects: (1) one specialized in understanding multiple languages (e.g., mT5 encoder) and (2) one specialized in reasoning (e.g., Orca 2). LangBridge connects the two models by introducing minimal trainable parameters between them. Despite utilizing only English data for training, LangBridge considerably enhances the performance of language models on low-resource languages across mathematical reasoning, coding, and logical reasoning. Our analysis suggests that the efficacy of LangBridge stems from the language-agnostic characteristics of multilingual representations. We publicly release our code and models.
Tree of Clarifications: Answering Ambiguous Questions with Retrieval-Augmented Large Language Models
Oct 23, 2023Questions in open-domain question answering are often ambiguous, allowing multiple interpretations. One approach to handling them is to identify all possible interpretations of the ambiguous question (AQ) and to generate a long-form answer addressing them all, as suggested by Stelmakh et al., (2022). While it provides a comprehensive response without bothering the user for clarification, considering multiple dimensions of ambiguity and gathering corresponding knowledge remains a challenge. To cope with the challenge, we propose a novel framework, Tree of Clarifications (ToC): It recursively constructs a tree of disambiguations for the AQ -- via few-shot prompting leveraging external knowledge -- and uses it to generate a long-form answer. ToC outperforms existing baselines on ASQA in a few-shot setup across the metrics, while surpassing fully-supervised baselines trained on the whole training set in terms of Disambig-F1 and Disambig-ROUGE. Code is available at https://github.com/gankim/tree-of-clarifications.
Prometheus: Inducing Fine-grained Evaluation Capability in Language Models
Oct 12, 2023Recently, using a powerful proprietary Large Language Model (LLM) (e.g., GPT-4) as an evaluator for long-form responses has become the de facto standard. However, for practitioners with large-scale evaluation tasks and custom criteria in consideration (e.g., child-readability), using proprietary LLMs as an evaluator is unreliable due to the closed-source nature, uncontrolled versioning, and prohibitive costs. In this work, we propose Prometheus, a fully open-source LLM that is on par with GPT-4's evaluation capabilities when the appropriate reference materials (reference answer, score rubric) are accompanied. We first construct the Feedback Collection, a new dataset that consists of 1K fine-grained score rubrics, 20K instructions, and 100K responses and language feedback generated by GPT-4. Using the Feedback Collection, we train Prometheus, a 13B evaluator LLM that can assess any given long-form text based on customized score rubric provided by the user. Experimental results show that Prometheus scores a Pearson correlation of 0.897 with human evaluators when evaluating with 45 customized score rubrics, which is on par with GPT-4 (0.882), and greatly outperforms ChatGPT (0.392). Furthermore, measuring correlation with GPT-4 with 1222 customized score rubrics across four benchmarks (MT Bench, Vicuna Bench, Feedback Bench, Flask Eval) shows similar trends, bolstering Prometheus's capability as an evaluator LLM. Lastly, Prometheus achieves the highest accuracy on two human preference benchmarks (HHH Alignment & MT Bench Human Judgment) compared to open-sourced reward models explicitly trained on human preference datasets, highlighting its potential as an universal reward model. We open-source our code, dataset, and model at https://github.com/kaistAI/Prometheus.
FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets
Jul 20, 2023
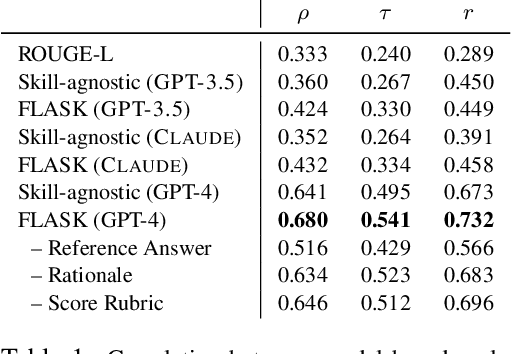

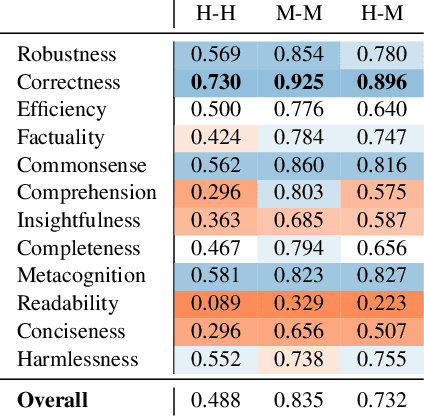
Evaluation of Large Language Models (LLMs) is challenging because aligning to human values requires the composition of multiple skills and the required set of skills varies depending on the instruction. Recent studies have evaluated the performance of LLMs in two ways, (1) automatic evaluation on several independent benchmarks and (2) human or machined-based evaluation giving an overall score to the response. However, both settings are coarse-grained evaluations, not considering the nature of user instructions that require instance-wise skill composition, which limits the interpretation of the true capabilities of LLMs. In this paper, we introduce FLASK (Fine-grained Language Model Evaluation based on Alignment SKill Sets), a fine-grained evaluation protocol that can be used for both model-based and human-based evaluation which decomposes coarse-level scoring to an instance-wise skill set-level. Specifically, we define 12 fine-grained skills needed for LLMs to follow open-ended user instructions and construct an evaluation set by allocating a set of skills for each instance. Additionally, by annotating the target domains and difficulty level for each instance, FLASK provides a holistic view with a comprehensive analysis of a model's performance depending on skill, domain, and difficulty. Through using FLASK, we compare multiple open-sourced and proprietary LLMs and observe highly-correlated findings between model-based and human-based evaluations. FLASK enables developers to more accurately measure the model performance and how it can be improved by analyzing factors that make LLMs proficient in particular skills. For practitioners, FLASK can be used to recommend suitable models for particular situations through comprehensive comparison among various LLMs. We release the evaluation data and code implementation at https://github.com/kaistAI/FLASK.