 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Static Dialogues: Benchmarking Realistic, Heterogeneous, and Evolving Long-Term Memory
Jun 01, 2026In existing memory benchmarks for Large Language Models (LLMs), the evaluated dialogue sessions often lack long-term semantic consistency, and the underlying personas tend to be flat and static. Furthermore, in real-world scenarios, interactions between users and assistants involve more diverse, heterogeneous data streams, such as documents and emails. These shortcomings significantly limit the realism and effectiveness of current evaluations. To address these limitations, we introduce RHELM (Realistic, Heterogeneous, and Evolving Long-term Memory). Driven by meticulously crafted user profiles and a novel LOOP (pLan-rOllout-evOlve-Prune) module, we construct realistic dialogues across diverse interaction scenarios that exhibit dynamic temporal evolution and long-term coherence. Crucially, these dialogues are deeply integrated with heterogeneous external sources synchronized with the user's temporal event trajectory. The resulting benchmark encompasses challenging question-answer pairs spanning seven inquiry types, with each question mapping to at least one of 27 critical memory characteristics that we identify as essential yet underexplored in current research. Comprehensive experiments across full-context models, retrieval-augmented generation (RAG) methods, and representative memory frameworks reveal that contemporary approaches still expose critical weaknesses in complex, real-world settings, particularly in resolving multi-source aggregation and real-world contextual reasoning.
From Patches to Trajectories: Privileged Process Supervision for Software-Engineering Agents
May 21, 2026Supervised fine-tuning (SFT) on long teacher trajectories is the dominant way to instill investigation and reasoning in open software-engineering (SWE) agents. Since every retained response becomes an imitation target, the student inherits the final outcome and intermediate flaws, including ungrounded leaps and redundant loops. High-quality training data must be effective(each step is grounded and narrows the agent's epistemic gap to the correct fix) and efficient(each step is information-bearing rather than redundant or looping). Existing recipes filter or relabel teacher rollouts using only a binary terminal verifier, which does not directly target these axes and provides no supervision on instances where the teacher fails. Most real issue includes a developer-authored reference patch, $p^\star$, revealing the file paths, runtime behaviors, and coding conventions presupposed by the correct fix, yet standard pipelines discard it. We propose Patches-to-Trajectories (P2T), which uses $p^\star$ as privileged information during curation and formulates trajectory construction as bi-objective optimization over per-step effectiveness and trajectory length. A reverse phase distills $p^\star$ into a latent process graph, $G^\star$, of contextual facts and solution milestones. A forward phase curates trajectories from blinded teacher continuations by scoring per-step progress against $G^\star$ under a leakage-blocking groundedness check and retaining the shortest effective segments. Using only 1.8k curated SWE-Gym instances, P2T improves effectiveness and efficiency over outcome-filtered SFT and its tool-error-masking variant. On SWE-bench Verified, it raises Pass@1 by up to 10.8 points while reducing per-instance inference cost by ~15%, with consistent gains on SWE-bench Lite. Size-matched ablations and qualitative analysis further isolate trajectory quality from data scale.
Memory Grafting: Scaling Language Model Pre-training via Offline Conditional Memory
May 20, 2026Scaling conditional memory offers a promising way to increase language-model capacity, but existing methods such as Engram learn large memory tables from scratch during pre-training, making memory scaling expensive and sometimes ineffective. We propose Memory Grafting, a conditional memory scaling method that utilizes frozen hidden states from a grafting model as conditional n-gram memory. Given frequent local n-grams, we run the grafting model offline, store final-token hidden representations as memory values, and let the recipient model retrieve them through exact longest-match suffix lookup. Retrieved memories are adapted by lightweight projections and gates, while a hash-based Engram fallback preserves coverage for unmatched contexts. Since the grafting model is only run offline and exact lookup has expected O(1) complexity with respect to memory-bank size, Memory Grafting expands external latent capacity with limited training and inference overhead. Experiments under matched recipient architectures and pre-training budgets show that Memory Grafting improves over both MoE and vanilla Engram baselines. In the 2.8B-scale setting, it improves the average benchmark score from 51.95 for MoE and 52.43 for vanilla Engram to 53.86. In the 0.92B-scale setting, all grafting-model variants improve over the baselines, with Qwen3.5-35B-A3B giving the strongest gains. These results suggest that pretrained models can serve as reusable constructors of external latent memory, providing a practical step toward scaling future language models beyond trainable parameters alone.
m3BERT: A Modern, Multi-lingual, Matryoshka Bidirectional Encoder
May 19, 2026Embedding models are pivotal in industrial information retrieval systems like search and advertising. However, existing pretrained models often exhibit fixed architectures and embedding dimensionalities, posing significant challenges when adapting them to diverse deployment scenarios with varying business-driven constraints. A common practice involves fine-tuning with partial parameter initialization from larger pretrained models for resource-constrained tasks. This method is often suboptimal as the misalignment between pretraining and downstream usage prevents full realization of pretraining benefits. To address this limitation, we introduce m3BERT: a Modern, Multi-lingual, Matryoshka Bidirectional Encoder, which features a novel pretraining strategy that jointly optimizes representations across both transformer layers and multiple embedding dimensions. This enables a single model to be tailored to varied resource and accuracy targets while maintaining consistency with pretraining. Incorporating recent architectural improvements, m3BERT uses a three-stage pretraining: monolingual pretraining, multilingual adaptation to serve diverse user bases, and crucial continual pretraining on a massive web domain corpus to enhance utility in commercial retrieval. m3BERT significantly outperforms state-of-the-art embedding models in Bing-Click, a large-scale industrial retrieval dataset, showcasing its practical versatility as an efficient foundation for resource-aware industrial retrieval systems. Further experiments on public datasets also confirm the general effectiveness of our multigranular Matryoshka pretraining strategy.
Improving Data and Reward Design for Scientific Reasoning in Large Language Models
Feb 09, 2026Solving open-ended science questions remains challenging for large language models, particularly due to inherently unreliable supervision and evaluation. The bottleneck lies in the data construction and reward design for scientific post-training. We develop a large-scale, systematic data processing pipeline that transforms heterogeneous open-source science data into Dr. SCI dataset, which comprises of 1M questions across eight STEM subjects, with explicit verifiable/open-ended splits, scalable difficulty annotation, and fine-grained rubrics that operationalize evaluation for open-ended answers. Building on this dataset, we propose the Dr. SCI post-training pipeline, which redesigns the standard SFT -> RL workflow through three components: (i) Exploration-Expanding SFT, which broadens the model's reasoning pattern coverage prior to RL; (ii) Dynamic Difficulty Curriculum, which adapts training data to the model's evolving scientific capability; and (iii) SciRubric-Guided RL, which enables stable reinforcement learning on open-ended scientific questions via rubric-based evaluation with explicit answer correctness. Qwen3-4B-Base trained using Dr.SCI pipeline achieves 63.2 on GPQA-diamond and 32.4 on GPQA-general, consistently improves over strong post-trained baselines such as o1-mini and GPT-4o, demonstrating substantial gains in scientific reasoning, especially in open-ended settings.
Pull Requests as a Training Signal for Repo-Level Code Editing
Feb 07, 2026Repository-level code editing requires models to understand complex dependencies and execute precise multi-file modifications across a large codebase. While recent gains on SWE-bench rely heavily on complex agent scaffolding, it remains unclear how much of this capability can be internalised via high-quality training signals. To address this, we propose Clean Pull Request (Clean-PR), a mid-training paradigm that leverages real-world GitHub pull requests as a training signal for repository-level editing. We introduce a scalable pipeline that converts noisy pull request diffs into Search/Replace edit blocks through reconstruction and validation, resulting in the largest publicly available corpus of 2 million pull requests spanning 12 programming languages. Using this training signal, we perform a mid-training stage followed by an agentless-aligned supervised fine-tuning process with error-driven data augmentation. On SWE-bench, our model significantly outperforms the instruction-tuned baseline, achieving absolute improvements of 13.6% on SWE-bench Lite and 12.3% on SWE-bench Verified. These results demonstrate that repository-level code understanding and editing capabilities can be effectively internalised into model weights under a simplified, agentless protocol, without relying on heavy inference-time scaffolding.
MSign: An Optimizer Preventing Training Instability in Large Language Models via Stable Rank Restoration
Feb 02, 2026Training instability remains a critical challenge in large language model (LLM) pretraining, often manifesting as sudden gradient explosions that waste significant computational resources. We study training failures in a 5M-parameter NanoGPT model scaled via $μ$P, identifying two key phenomena preceding collapse: (1) rapid decline in weight matrix stable rank (ratio of squared Frobenius norm to squared spectral norm), and (2) increasing alignment between adjacent layer Jacobians. We prove theoretically that these two conditions jointly cause exponential gradient norm growth with network depth. To break this instability mechanism, we propose MSign, a new optimizer that periodically applies matrix sign operations to restore stable rank. Experiments on models from 5M to 3B parameters demonstrate that MSign effectively prevents training failures with a computational overhead of less than 7.0%.
Training LLMs for Divide-and-Conquer Reasoning Elevates Test-Time Scalability
Feb 02, 2026Large language models (LLMs) have demonstrated strong reasoning capabilities through step-by-step chain-of-thought (CoT) reasoning. Nevertheless, at the limits of model capability, CoT often proves insufficient, and its strictly sequential nature constrains test-time scalability. A potential alternative is divide-and-conquer (DAC) reasoning, which decomposes a complex problem into subproblems to facilitate more effective exploration of the solution. Although promising, our analysis reveals a fundamental misalignment between general-purpose post-training and DAC-style inference, which limits the model's capacity to fully leverage this potential. To bridge this gap and fully unlock LLMs' reasoning capabilities on the most challenging tasks, we propose an end-to-end reinforcement learning (RL) framework to enhance their DAC-style reasoning capacity. At each step, the policy decomposes a problem into a group of subproblems, solves them sequentially, and addresses the original one conditioned on the subproblem solutions, with both decomposition and solution integrated into RL training. Under comparable training, our DAC-style framework endows the model with a higher performance ceiling and stronger test-time scalability, surpassing CoT by 8.6% in Pass@1 and 6.3% in Pass@32 on competition-level benchmarks.
Sigma-MoE-Tiny Technical Report
Dec 19, 2025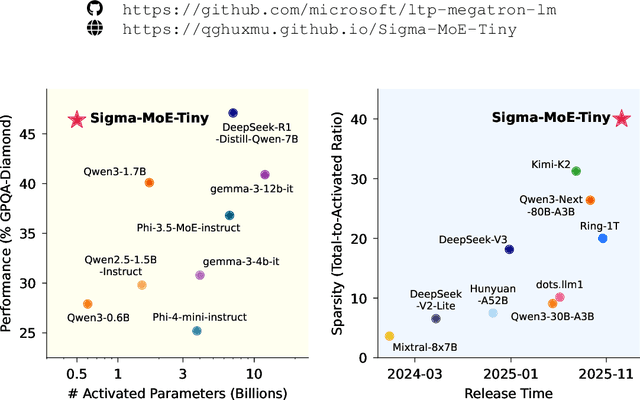

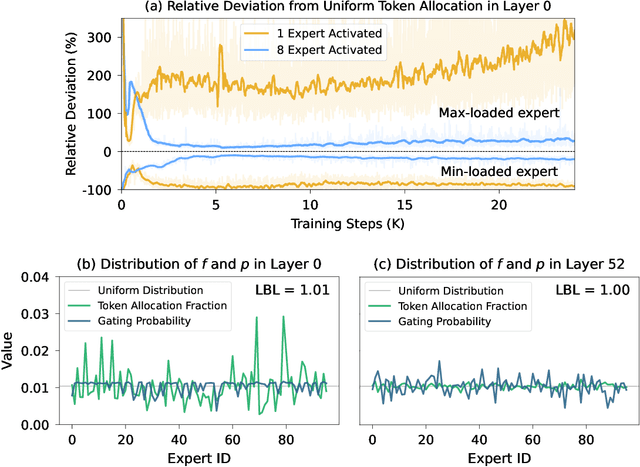
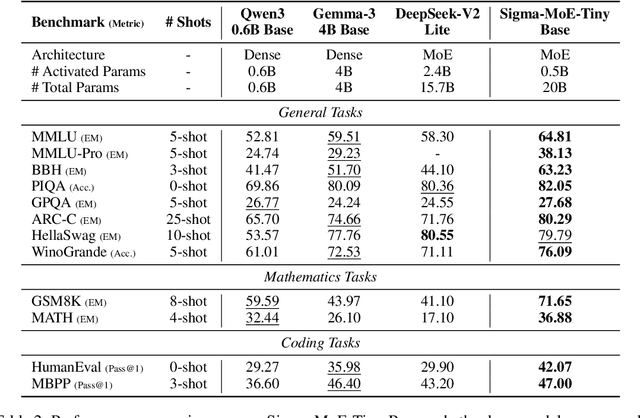
Mixture-of-Experts (MoE) has emerged as a promising paradigm for foundation models due to its efficient and powerful scalability. In this work, we present Sigma-MoE-Tiny, an MoE language model that achieves the highest sparsity compared to existing open-source models. Sigma-MoE-Tiny employs fine-grained expert segmentation with up to 96 experts per layer, while activating only one expert for each token, resulting in 20B total parameters with just 0.5B activated. The major challenge introduced by such extreme sparsity lies in expert load balancing. We find that the widely-used load balancing loss tends to become ineffective in the lower layers under this setting. To address this issue, we propose a progressive sparsification schedule aiming to balance expert utilization and training stability. Sigma-MoE-Tiny is pre-trained on a diverse and high-quality corpus, followed by post-training to further unlock its capabilities. The entire training process remains remarkably stable, with no occurrence of irrecoverable loss spikes. Comprehensive evaluations reveal that, despite activating only 0.5B parameters, Sigma-MoE-Tiny achieves top-tier performance among counterparts of comparable or significantly larger scale. In addition, we provide an in-depth discussion of load balancing in highly sparse MoE models, offering insights for advancing sparsity in future MoE architectures. Project page: https://qghuxmu.github.io/Sigma-MoE-Tiny Code: https://github.com/microsoft/ltp-megatron-lm
SIGMA: An AI-Empowered Training Stack on Early-Life Hardware
Dec 15, 2025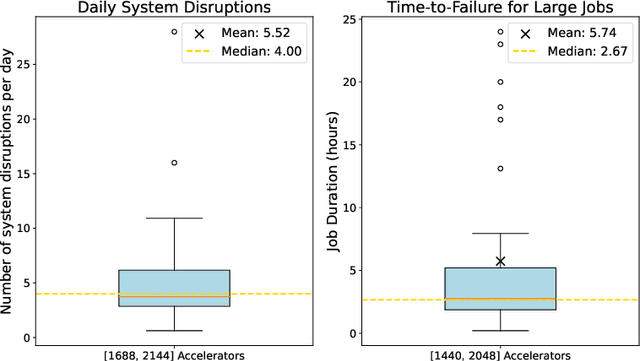

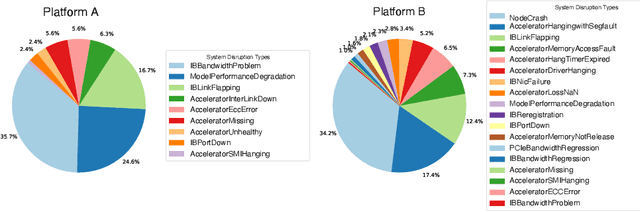

An increasing variety of AI accelerators is being considered for large-scale training. However, enabling large-scale training on early-life AI accelerators faces three core challenges: frequent system disruptions and undefined failure modes that undermine reliability; numerical errors and training instabilities that threaten correctness and convergence; and the complexity of parallelism optimization combined with unpredictable local noise that degrades efficiency. To address these challenges, SIGMA is an open-source training stack designed to improve the reliability, stability, and efficiency of large-scale distributed training on early-life AI hardware. The core of this initiative is the LUCIA TRAINING PLATFORM (LTP), the system optimized for clusters with early-life AI accelerators. Since its launch in March 2025, LTP has significantly enhanced training reliability and operational productivity. Over the past five months, it has achieved an impressive 94.45% effective cluster accelerator utilization, while also substantially reducing node recycling and job-recovery times. Building on the foundation of LTP, the LUCIA TRAINING FRAMEWORK (LTF) successfully trained SIGMA-MOE, a 200B MoE model, using 2,048 AI accelerators. This effort delivered remarkable stability and efficiency outcomes, achieving 21.08% MFU, state-of-the-art downstream accuracy, and encountering only one stability incident over a 75-day period. Together, these advances establish SIGMA, which not only tackles the critical challenges of large-scale training but also establishes a new benchmark for AI infrastructure and platform innovation, offering a robust, cost-effective alternative to prevailing established accelerator stacks and significantly advancing AI capabilities and scalability. The source code of SIGMA is available at https://github.com/microsoft/LuciaTrainingPlatform.