 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Track Their Output Length? A Dynamic Feedback Mechanism for Precise Length Regulation
Jan 07, 2026Precisely controlling the length of generated text is a common requirement in real-world applications. However, despite significant advancements in following human instructions, Large Language Models (LLMs) still struggle with this task. In this work, we demonstrate that LLMs often fail to accurately measure their response lengths, leading to poor adherence to length constraints. To address this issue, we propose a novel length regulation approach that incorporates dynamic length feedback during generation, enabling adaptive adjustments to meet target lengths. Experiments on summarization and biography tasks show our training-free approach significantly improves precision in achieving target token, word, or sentence counts without compromising quality. Additionally, we demonstrate that further supervised fine-tuning allows our method to generalize effectively to broader text-generation tasks.
Sigma-MoE-Tiny Technical Report
Dec 19, 2025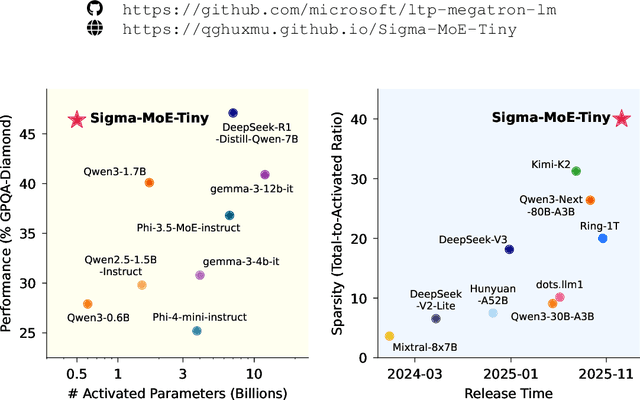

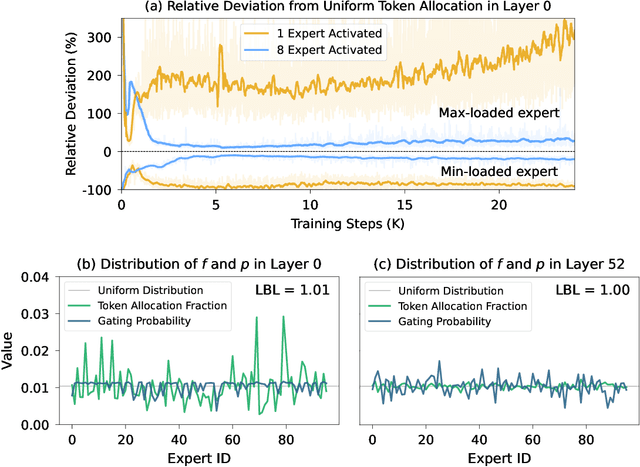
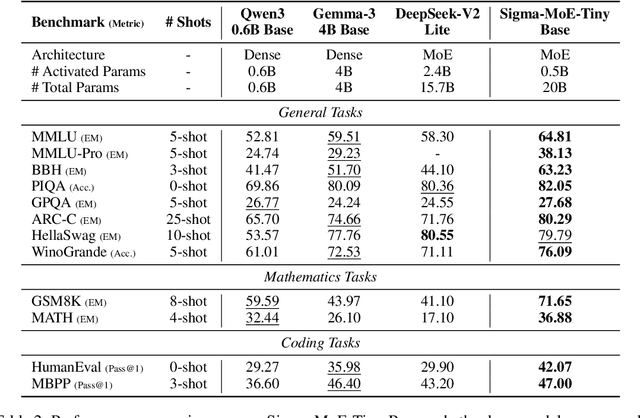
Mixture-of-Experts (MoE) has emerged as a promising paradigm for foundation models due to its efficient and powerful scalability. In this work, we present Sigma-MoE-Tiny, an MoE language model that achieves the highest sparsity compared to existing open-source models. Sigma-MoE-Tiny employs fine-grained expert segmentation with up to 96 experts per layer, while activating only one expert for each token, resulting in 20B total parameters with just 0.5B activated. The major challenge introduced by such extreme sparsity lies in expert load balancing. We find that the widely-used load balancing loss tends to become ineffective in the lower layers under this setting. To address this issue, we propose a progressive sparsification schedule aiming to balance expert utilization and training stability. Sigma-MoE-Tiny is pre-trained on a diverse and high-quality corpus, followed by post-training to further unlock its capabilities. The entire training process remains remarkably stable, with no occurrence of irrecoverable loss spikes. Comprehensive evaluations reveal that, despite activating only 0.5B parameters, Sigma-MoE-Tiny achieves top-tier performance among counterparts of comparable or significantly larger scale. In addition, we provide an in-depth discussion of load balancing in highly sparse MoE models, offering insights for advancing sparsity in future MoE architectures. Project page: https://qghuxmu.github.io/Sigma-MoE-Tiny Code: https://github.com/microsoft/ltp-megatron-lm
Training Matryoshka Mixture-of-Experts for Elastic Inference-Time Expert Utilization
Sep 30, 2025Mixture-of-Experts (MoE) has emerged as a promising paradigm for efficiently scaling large language models without a proportional increase in computational cost. However, the standard training strategy of Top-K router prevents MoE models from realizing their full potential for elastic inference. When the number of activated experts is altered at inference time, these models exhibit precipitous performance degradation. In this work, we introduce Matryoshka MoE (M-MoE), a training framework that instills a coarse-to-fine structure directly into the expert ensemble. By systematically varying the number of activated experts during training, M-MoE compels the model to learn a meaningful ranking: top-ranked experts collaborate to provide essential, coarse-grained capabilities, while subsequent experts add progressively finer-grained detail. We explore this principle at multiple granularities, identifying a layer-wise randomization strategy as the most effective. Our experiments demonstrate that a single M-MoE model achieves remarkable elasticity, with its performance at various expert counts closely matching that of an entire suite of specialist models, but at only a fraction of the total training cost. This flexibility not only unlocks elastic inference but also enables optimizing performance by allocating different computational budgets to different model layers. Our work paves the way for more practical and adaptable deployments of large-scale MoE models.
Towards Better Document-level Relation Extraction via Iterative Inference
Nov 26, 2022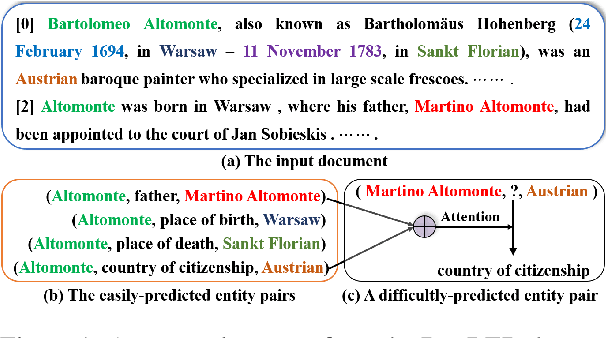
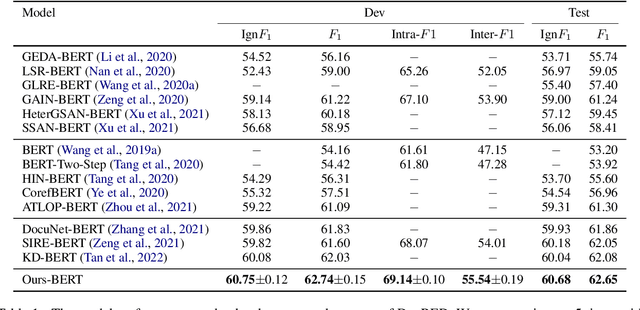
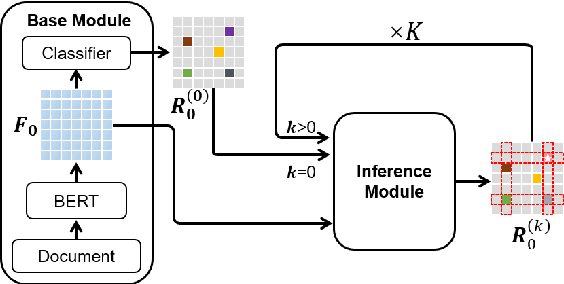
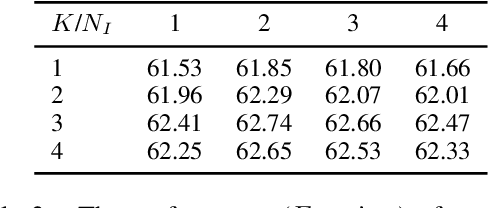
Document-level relation extraction (RE) aims to extract the relations between entities from the input document that usually containing many difficultly-predicted entity pairs whose relations can only be predicted through relational inference. Existing methods usually directly predict the relations of all entity pairs of input document in a one-pass manner, ignoring the fact that predictions of some entity pairs heavily depend on the predicted results of other pairs. To deal with this issue, in this paper, we propose a novel document-level RE model with iterative inference. Our model is mainly composed of two modules: 1) a base module expected to provide preliminary relation predictions on entity pairs; 2) an inference module introduced to refine these preliminary predictions by iteratively dealing with difficultly-predicted entity pairs depending on other pairs in an easy-to-hard manner. Unlike previous methods which only consider feature information of entity pairs, our inference module is equipped with two Extended Cross Attention units, allowing it to exploit both feature information and previous predictions of entity pairs during relational inference. Furthermore, we adopt a two-stage strategy to train our model. At the first stage, we only train our base module. During the second stage, we train the whole model, where contrastive learning is introduced to enhance the training of inference module. Experimental results on three commonly-used datasets show that our model consistently outperforms other competitive baselines.