 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigma-MoE-Tiny Technical Report
Dec 19, 2025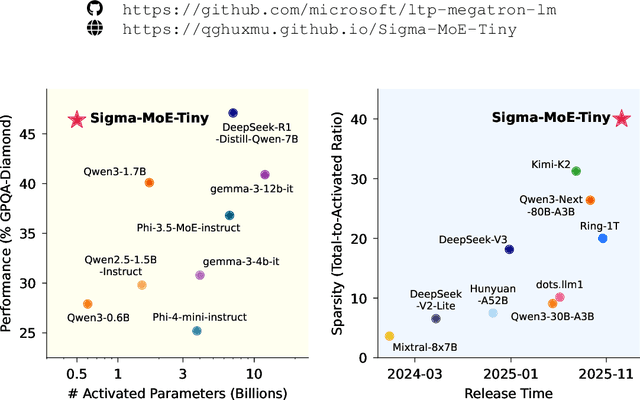

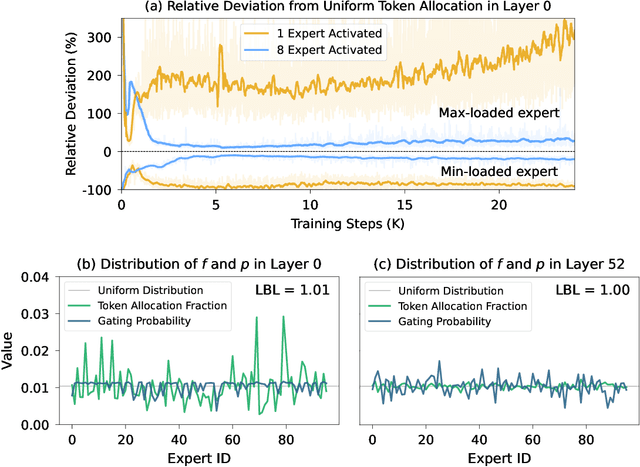
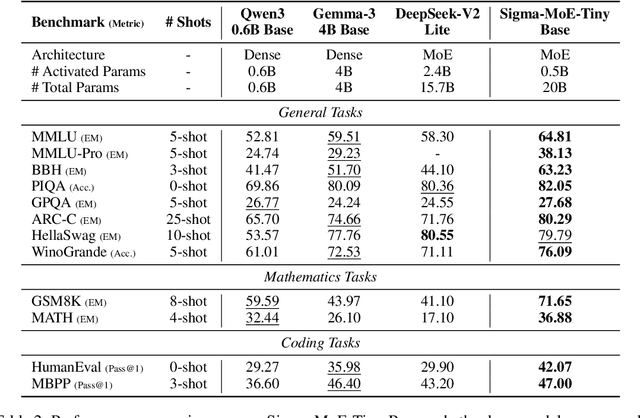
Mixture-of-Experts (MoE) has emerged as a promising paradigm for foundation models due to its efficient and powerful scalability. In this work, we present Sigma-MoE-Tiny, an MoE language model that achieves the highest sparsity compared to existing open-source models. Sigma-MoE-Tiny employs fine-grained expert segmentation with up to 96 experts per layer, while activating only one expert for each token, resulting in 20B total parameters with just 0.5B activated. The major challenge introduced by such extreme sparsity lies in expert load balancing. We find that the widely-used load balancing loss tends to become ineffective in the lower layers under this setting. To address this issue, we propose a progressive sparsification schedule aiming to balance expert utilization and training stability. Sigma-MoE-Tiny is pre-trained on a diverse and high-quality corpus, followed by post-training to further unlock its capabilities. The entire training process remains remarkably stable, with no occurrence of irrecoverable loss spikes. Comprehensive evaluations reveal that, despite activating only 0.5B parameters, Sigma-MoE-Tiny achieves top-tier performance among counterparts of comparable or significantly larger scale. In addition, we provide an in-depth discussion of load balancing in highly sparse MoE models, offering insights for advancing sparsity in future MoE architectures. Project page: https://qghuxmu.github.io/Sigma-MoE-Tiny Code: https://github.com/microsoft/ltp-megatron-lm
SIGMA: An AI-Empowered Training Stack on Early-Life Hardware
Dec 15, 2025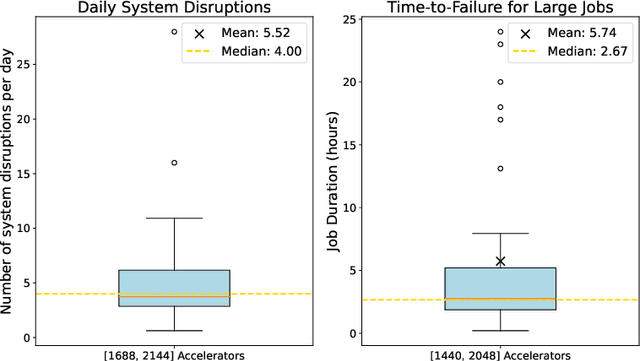

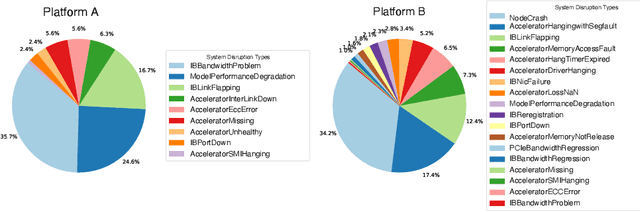

An increasing variety of AI accelerators is being considered for large-scale training. However, enabling large-scale training on early-life AI accelerators faces three core challenges: frequent system disruptions and undefined failure modes that undermine reliability; numerical errors and training instabilities that threaten correctness and convergence; and the complexity of parallelism optimization combined with unpredictable local noise that degrades efficiency. To address these challenges, SIGMA is an open-source training stack designed to improve the reliability, stability, and efficiency of large-scale distributed training on early-life AI hardware. The core of this initiative is the LUCIA TRAINING PLATFORM (LTP), the system optimized for clusters with early-life AI accelerators. Since its launch in March 2025, LTP has significantly enhanced training reliability and operational productivity. Over the past five months, it has achieved an impressive 94.45% effective cluster accelerator utilization, while also substantially reducing node recycling and job-recovery times. Building on the foundation of LTP, the LUCIA TRAINING FRAMEWORK (LTF) successfully trained SIGMA-MOE, a 200B MoE model, using 2,048 AI accelerators. This effort delivered remarkable stability and efficiency outcomes, achieving 21.08% MFU, state-of-the-art downstream accuracy, and encountering only one stability incident over a 75-day period. Together, these advances establish SIGMA, which not only tackles the critical challenges of large-scale training but also establishes a new benchmark for AI infrastructure and platform innovation, offering a robust, cost-effective alternative to prevailing established accelerator stacks and significantly advancing AI capabilities and scalability. The source code of SIGMA is available at https://github.com/microsoft/LuciaTrainingPlatform.
Aerial Grasping via Maximizing Delta-Arm Workspace Utilization
Jun 18, 2025The workspace limits the operational capabilities and range of motion for the systems with robotic arms. Maximizing workspace utilization has the potential to provide more optimal solutions for aerial manipulation tasks, increasing the system's flexibility and operational efficiency. In this paper, we introduce a novel planning framework for aerial grasping that maximizes workspace utilization. We formulate an optimization problem to optimize the aerial manipulator's trajectory, incorporating task constraints to achieve efficient manipulation. To address the challenge of incorporating the delta arm's non-convex workspace into optimization constraints, we leverage a Multilayer Perceptron (MLP) to map position points to feasibility probabilities.Furthermore, we employ Reversible Residual Networks (RevNet) to approximate the complex forward kinematics of the delta arm, utilizing efficient model gradients to eliminate workspace constraints. We validate our methods in simulations and real-world experiments to demonstrate their effectiveness.
Benchmarking AI scientists in omics data-driven biological research
May 13, 2025The rise of large language models and multi-agent systems has sparked growing interest in AI scientists capable of autonomous biological research. However, existing benchmarks either focus on reasoning without data or on data analysis with predefined statistical answers, lacking realistic, data-driven evaluation settings. Here, we introduce the Biological AI Scientist Benchmark (BaisBench), a benchmark designed to assess AI scientists' ability to generate biological discoveries through data analysis and reasoning with external knowledge. BaisBench comprises two tasks: cell type annotation on 31 expert-labeled single-cell datasets, and scientific discovery through answering 198 multiple-choice questions derived from the biological insights of 41 recent single-cell studies. Systematic experiments on state-of-the-art AI scientists and LLM agents showed that while promising, current models still substantially underperform human experts on both tasks. We hope BaisBench will fill this gap and serve as a foundation for advancing and evaluating AI models for scientific discovery. The benchmark can be found at: https://github.com/EperLuo/BaisBench.
Argos: Agentic Time-Series Anomaly Detection with Autonomous Rule Generation via Large Language Models
Jan 24, 2025



Observability in cloud infrastructure is critical for service providers, driving the widespread adoption of anomaly detection systems for monitoring metrics. However, existing systems often struggle to simultaneously achieve explainability, reproducibility, and autonomy, which are three indispensable properties for production use. We introduce Argos, an agentic system for detecting time-series anomalies in cloud infrastructure by leveraging large language models (LLMs). Argos proposes to use explainable and reproducible anomaly rules as intermediate representation and employs LLMs to autonomously generate such rules. The system will efficiently train error-free and accuracy-guaranteed anomaly rules through multiple collaborative agents and deploy the trained rules for low-cost online anomaly detection. Through evaluation results, we demonstrate that Argos outperforms state-of-the-art methods, increasing $F_1$ scores by up to $9.5\%$ and $28.3\%$ on public anomaly detection datasets and an internal dataset collected from Microsoft, respectively.
Attentive-based Multi-level Feature Fusion for Voice Disorder Diagnosis
Oct 07, 2024



Voice disorders negatively impact the quality of daily life in various ways. However, accurately recognizing the category of pathological features from raw audio remains a considerable challenge due to the limited dataset. A promising method to handle this issue is extracting multi-level pathological information from speech in a comprehensive manner by fusing features in the latent space. In this paper, a novel framework is designed to explore the way of high-quality feature fusion for effective and generalized detection performance. Specifically, the proposed model follows a two-stage training paradigm: (1) ECAPA-TDNN and Wav2vec 2.0 which have shown remarkable effectiveness in various domains are employed to learn the universal pathological information from raw audio; (2) An attentive fusion module is dedicatedly designed to establish the interaction between pathological features projected by EcapTdnn and Wav2vec 2.0 respectively and guide the multi-layer fusion, the entire model is jointly fine-tuned from pre-trained features by the automatic voice pathology detection task. Finally, comprehensive experiments on the FEMH and SVD datasets demonstrate that the proposed framework outperforms the competitive baselines, and achieves the accuracy of 90.51% and 87.68%.
FP8-LM: Training FP8 Large Language Models
Oct 27, 2023



In this paper, we explore FP8 low-bit data formats for efficient training of large language models (LLMs). Our key insight is that most variables, such as gradients and optimizer states, in LLM training can employ low-precision data formats without compromising model accuracy and requiring no changes to hyper-parameters. Specifically, we propose a new FP8 automatic mixed-precision framework for training LLMs. This framework offers three levels of FP8 utilization to streamline mixed-precision and distributed parallel training for LLMs. It gradually incorporates 8-bit gradients, optimizer states, and distributed learning in an incremental manner. Experiment results show that, during the training of GPT-175B model on H100 GPU platform, our FP8 mixed-precision training framework not only achieved a remarkable 42% reduction in real memory usage but also ran 64% faster than the widely adopted BF16 framework (i.e., Megatron-LM), surpassing the speed of Nvidia Transformer Engine by 17%. This largely reduces the training costs for large foundation models. Furthermore, our FP8 mixed-precision training methodology is generic. It can be seamlessly applied to other tasks such as LLM instruction tuning and reinforcement learning with human feedback, offering savings in fine-tuning expenses. Our FP8 low-precision training framework is open-sourced at {https://github.com/Azure/MS-AMP}{aka.ms/MS.AMP}.
Tutel: Adaptive Mixture-of-Experts at Scale
Jun 07, 2022
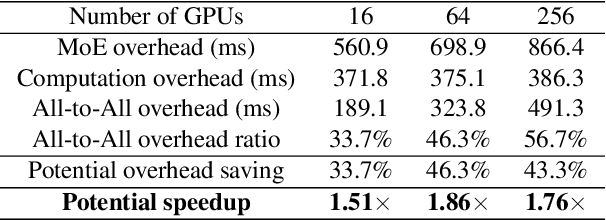
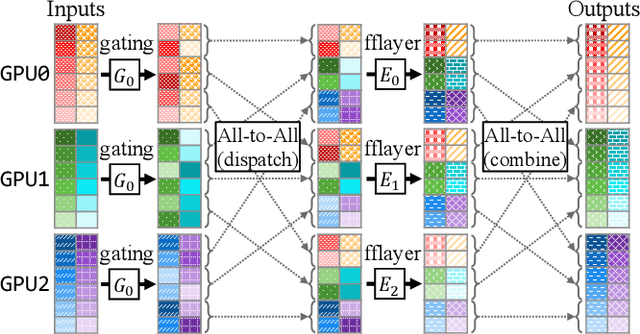

In recent years, Mixture-of-Experts (MoE) has emerged as a promising technique for deep learning that can scale the model capacity to trillion-plus parameters while reducing the computing cost via sparse computation. While MoE opens a new frontier of exceedingly large models, its implementation over thousands of GPUs has been limited due to mismatch between the dynamic nature of MoE and static parallelism/pipelining of the system. We present Tutel, a highly scalable stack design and implementation for MoE with dynamically adaptive parallelism and pipelining. Tutel delivers adaptive parallelism switching and adaptive pipelining at runtime, which achieves up to 1.74x and 2.00x single MoE layer speedup, respectively. We also propose a novel two-dimensional hierarchical algorithm for MoE communication speedup that outperforms the previous state-of-the-art up to 20.7x over 2,048 GPUs. Aggregating all techniques, Tutel finally delivers 4.96x and 5.75x speedup of a single MoE layer on 16 GPUs and 2,048 GPUs, respectively, over Fairseq: Meta's Facebook AI Research Sequence-to-Sequence Toolkit (Tutel is now partially adopted by Fairseq). Tutel source code is available in public: https://github.com/microsoft/tutel . Our evaluation shows that Tutel efficiently and effectively runs a real-world MoE-based model named SwinV2-MoE, built upon Swin Transformer V2, a state-of-the-art computer vision architecture. On efficiency, Tutel accelerates SwinV2-MoE, achieving up to 1.55x and 2.11x speedup in training and inference over Fairseq, respectively. On effectiveness, the SwinV2-MoE model achieves superior accuracy in both pre-training and down-stream computer vision tasks such as COCO object detection than the counterpart dense model, indicating the readiness of Tutel for end-to-end real-world model training and inference. SwinV2-MoE is open sourced in https://github.com/microsoft/Swin-Transformer .