 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogo-LLM: Local and Global Modeling with Large Language Models for Time Series Forecasting
May 16, 2025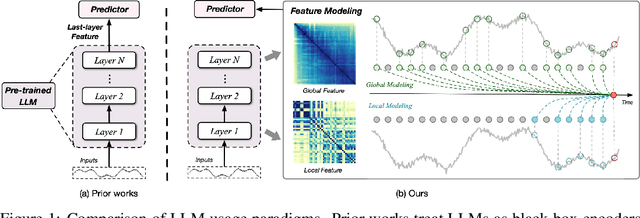
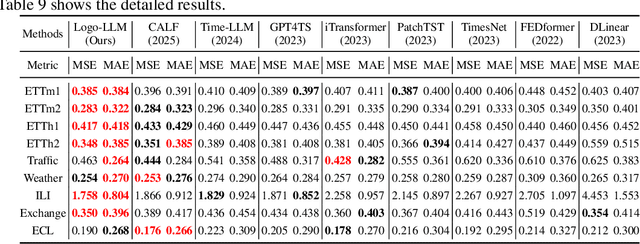
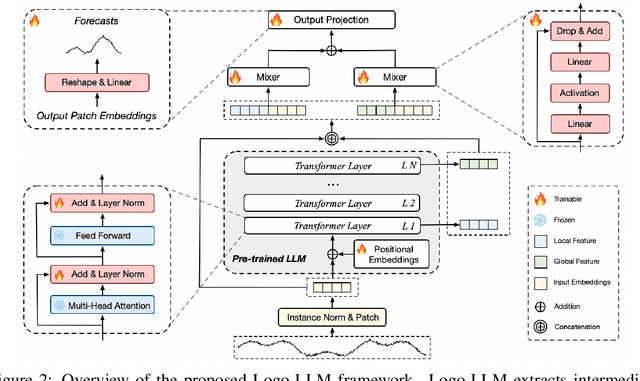
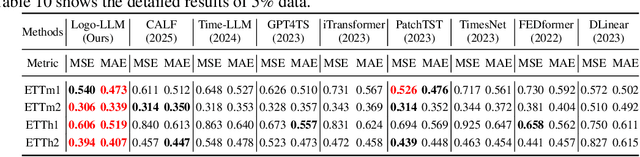
Time series forecasting is critical across multiple domains, where time series data exhibits both local patterns and global dependencies. While Transformer-based methods effectively capture global dependencies, they often overlook short-term local variations in time series. Recent methods that adapt large language models (LLMs) into time series forecasting inherit this limitation by treating LLMs as black-box encoders, relying solely on the final-layer output and underutilizing hierarchical representations. To address this limitation, we propose Logo-LLM, a novel LLM-based framework that explicitly extracts and models multi-scale temporal features from different layers of a pre-trained LLM. Through empirical analysis, we show that shallow layers of LLMs capture local dynamics in time series, while deeper layers encode global trends. Moreover, Logo-LLM introduces lightweight Local-Mixer and Global-Mixer modules to align and integrate features with the temporal input across layers. Extensive experiments demonstrate that Logo-LLM achieves superior performance across diverse benchmarks, with strong generalization in few-shot and zero-shot settings while maintaining low computational overhead.
Attentive-based Multi-level Feature Fusion for Voice Disorder Diagnosis
Oct 07, 2024



Voice disorders negatively impact the quality of daily life in various ways. However, accurately recognizing the category of pathological features from raw audio remains a considerable challenge due to the limited dataset. A promising method to handle this issue is extracting multi-level pathological information from speech in a comprehensive manner by fusing features in the latent space. In this paper, a novel framework is designed to explore the way of high-quality feature fusion for effective and generalized detection performance. Specifically, the proposed model follows a two-stage training paradigm: (1) ECAPA-TDNN and Wav2vec 2.0 which have shown remarkable effectiveness in various domains are employed to learn the universal pathological information from raw audio; (2) An attentive fusion module is dedicatedly designed to establish the interaction between pathological features projected by EcapTdnn and Wav2vec 2.0 respectively and guide the multi-layer fusion, the entire model is jointly fine-tuned from pre-trained features by the automatic voice pathology detection task. Finally, comprehensive experiments on the FEMH and SVD datasets demonstrate that the proposed framework outperforms the competitive baselines, and achieves the accuracy of 90.51% and 87.68%.
ROSE: A Recognition-Oriented Speech Enhancement Framework in Air Traffic Control Using Multi-Objective Learning
Dec 11, 2023Radio speech echo is a specific phenomenon in the air traffic control (ATC) domain, which degrades speech quality and further impacts automatic speech recognition (ASR) accuracy. In this work, a recognition-oriented speech enhancement (ROSE) framework is proposed to improve speech intelligibility and also advance ASR accuracy, which serves as a plug-and-play tool in ATC scenarios and does not require additional retraining of the ASR model. Specifically, an encoder-decoder-based U-Net framework is proposed to eliminate the radio speech echo based on the real-world collected corpus. By incorporating the SE-oriented and ASR-oriented loss, ROSE is implemented in a multi-objective manner by learning shared representations across the two optimization objectives. An attention-based skip-fusion (ABSF) mechanism is applied to skip connections to refine the features. A channel and sequence attention (CSAtt) block is innovatively designed to guide the model to focus on informative representations and suppress disturbing features. The experimental results show that the ROSE significantly outperforms other state-of-the-art methods for both the SE and ASR tasks. In addition, the proposed approach can contribute to the desired performance improvements on public datasets.
WinNet:time series forecasting with a window-enhanced period extracting and interacting
Nov 01, 2023Recently, Transformer-based methods have significantly improved state-of-the-art time series forecasting results, but they suffer from high computational costs and the inability to capture the long and short periodicity of time series. We present a highly accurate and simply structured CNN-based model for long-term time series forecasting tasks, called WinNet, including (i) Inter-Intra Period Encoder (I2PE) to transform 1D sequence into 2D tensor with long and short periodicity according to the predefined periodic window, (ii) Two-Dimensional Period Decomposition (TDPD) to model period-trend and oscillation terms, and (iii) Decomposition Correlation Block (DCB) to leverage the correlations of the period-trend and oscillation terms to support the prediction tasks by CNNs. Results on nine benchmark datasets show that the WinNet can achieve SOTA performance and lower computational complexity over CNN-, MLP-, Transformer-based approaches. The WinNet provides potential for the CNN-based methods in the time series forecasting tasks, with perfect tradeoff between performance and efficiency.
FlightBERT++: A Non-autoregressive Multi-Horizon Flight Trajectory Prediction Framework
May 02, 2023Flight Trajectory Prediction (FTP) is an essential task in Air Traffic Control (ATC), which can assist air traffic controllers to manage airspace more safely and efficiently. Existing approaches generally perform multi-horizon FTP tasks in an autoregressive manner, which is prone to suffer from error accumulation and low-efficiency problems. In this paper, a novel framework, called FlightBERT++, is proposed to i) forecast multi-horizon flight trajectories directly in a non-autoregressive way, and ii) improved the limitation of the binary encoding (BE) representation in the FlightBERT framework. Specifically, the proposed framework is implemented by a generalized Encoder-Decoder architecture, in which the encoder learns the temporal-spatial patterns from historical observations and the decoder predicts the flight status for the future time steps. Compared to conventional architecture, an extra horizon-aware contexts generator (HACG) is dedicatedly designed to consider the prior horizon information that enables us to perform multi-horizon non-autoregressive prediction. Additionally, a differential prediction strategy is designed by well considering both the stationarity of the differential sequence and the high-bits errors of the BE representation. Moreover, the Bit-wise Weighted Binary Cross Entropy loss function is proposed to optimize the proposed framework that can further constrain the high-bits errors of the predictions. Finally, the proposed framework is validated on a real-world flight trajectory dataset. The experimental results show that the proposed framework outperformed the competitive baselines.
SIA-FTP: A Spoken Instruction Aware Flight Trajectory Prediction Framework
May 02, 2023Ground-air negotiation via speech communication is a vital prerequisite for ensuring safety and efficiency in air traffic control (ATC) operations. However, with the increase in traffic flow, incorrect instructions caused by human factors bring a great threat to ATC safety. Existing flight trajectory prediction (FTP) approaches primarily rely on the flight status of historical trajectory, leading to significant delays in the prediction of real-time maneuvering instruction, which is not conducive to conflict detection. A major reason is that spoken instructions and flight trajectories are presented in different modalities in the current air traffic control (ATC) system, bringing great challenges to considering the maneuvering instruction in the FTP tasks. In this paper, a spoken instruction-aware FTP framework, called SIA-FTP, is innovatively proposed to support high-maneuvering FTP tasks by incorporating instant spoken instruction. To address the modality gap and minimize the data requirements, a 3-stage learning paradigm is proposed to implement the SIA-FTP framework in a progressive manner, including trajectory-based FTP pretraining, intent-oriented instruction embedding learning, and multi-modal finetuning. Specifically, the FTP model and the instruction embedding with maneuvering semantics are pre-trained using volumes of well-resourced trajectory and text data in the 1st and 2nd stages. In succession, a multi-modal fusion strategy is proposed to incorporate the pre-trained instruction embedding into the FTP model and integrate the two pre-trained networks into a joint model. Finally, the joint model is finetuned using the limited trajectory-instruction data to enhance the FTP performance within maneuvering instruction scenarios. The experimental results demonstrated that the proposed framework presents an impressive performance improvement in high-maneuvering scenarios.
Enhancing multilingual speech recognition in air traffic control by sentence-level language identification
Apr 29, 2023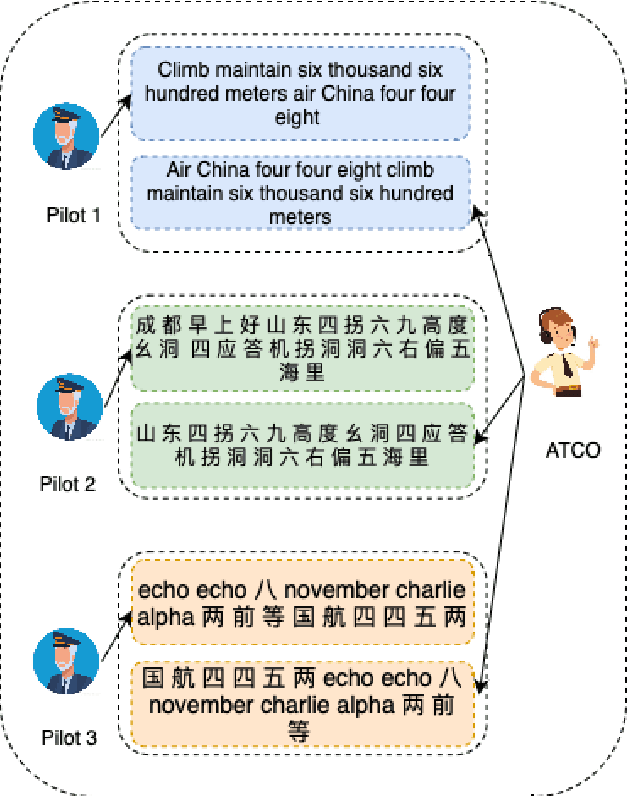
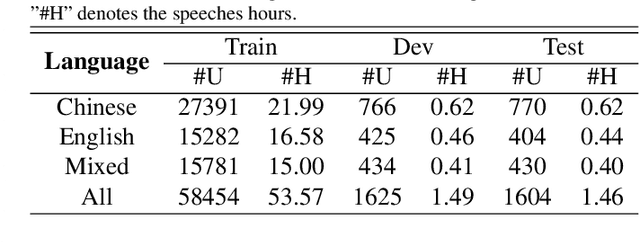
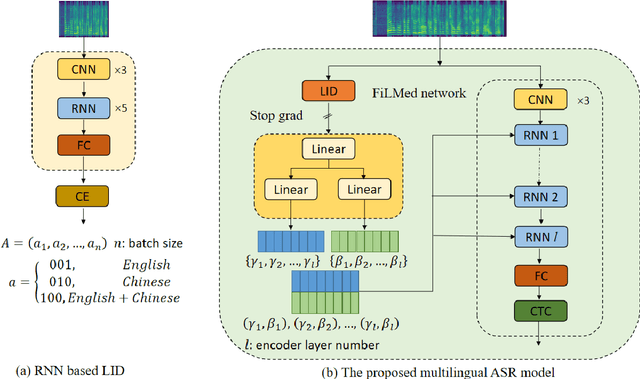
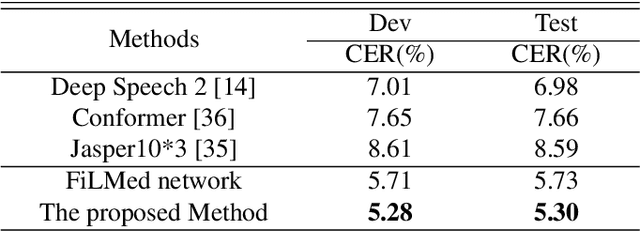
Automatic speech recognition (ASR) technique is becoming increasingly popular to improve the efficiency and safety of air traffic control (ATC) operations. However, the conversation between ATC controllers and pilots using multilingual speech brings a great challenge to building high-accuracy ASR systems. In this work, we present a two-stage multilingual ASR framework. The first stage is to train a language identifier (LID), that based on a recurrent neural network (RNN) to obtain sentence language identification in the form of one-hot encoding. The second stage aims to train an RNN-based end-to-end multilingual recognition model that utilizes sentence language features generated by LID to enhance input features. In this work, We introduce Featurewise Linear Modulation (FiLM) to improve the performance of multilingual ASR by utilizing sentence language identification. Furthermore, we introduce a new sentence language identification learning module called SLIL, which consists of a FiLM layer and a Squeeze-and-Excitation Networks layer. Extensive experiments on the ATCSpeech dataset show that our proposed method outperforms the baseline model. Compared to the vanilla FiLMed backbone model, the proposed multilingual ASR model obtains about 7.50% character error rate relative performance improvement.
Speech recognition for air traffic control via feature learning and end-to-end training
Nov 04, 2021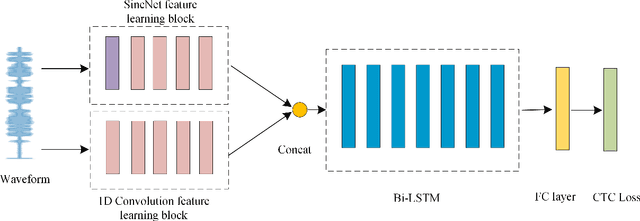
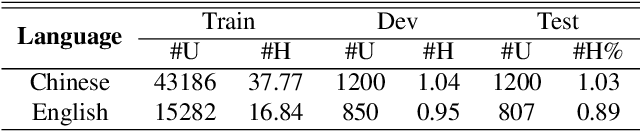
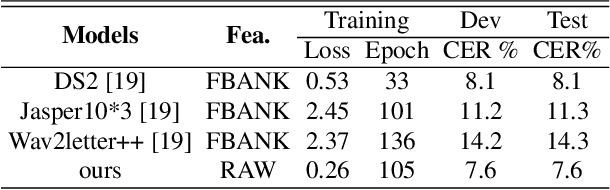
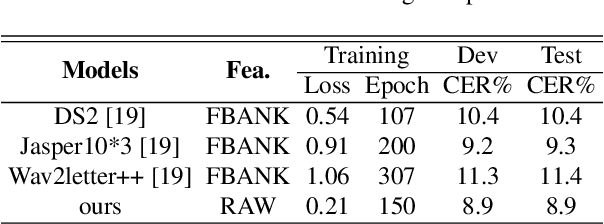
In this work, we propose a new automatic speech recognition (ASR) system based on feature learning and an end-to-end training procedure for air traffic control (ATC) systems. The proposed model integrates the feature learning block, recurrent neural network (RNN), and connectionist temporal classification loss to build an end-to-end ASR model. Facing the complex environments of ATC speech, instead of the handcrafted features, a learning block is designed to extract informative features from raw waveforms for acoustic modeling. Both the SincNet and 1D convolution blocks are applied to process the raw waveforms, whose outputs are concatenated to the RNN layers for the temporal modeling. Thanks to the ability to learn representations from raw waveforms, the proposed model can be optimized in a complete end-to-end manner, i.e., from waveform to text. Finally, the multilingual issue in the ATC domain is also considered to achieve the ASR task by constructing a combined vocabulary of Chinese characters and English letters. The proposed approach is validated on a multilingual real-world corpus (ATCSpeech), and the experimental results demonstrate that the proposed approach outperforms other baselines, achieving a 6.9\% character error rate.
A Comparative Study of Speaker Role Identification in Air Traffic Communication Using Deep Learning Approaches
Nov 03, 2021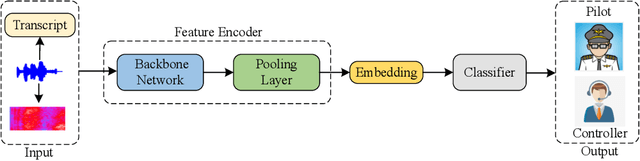

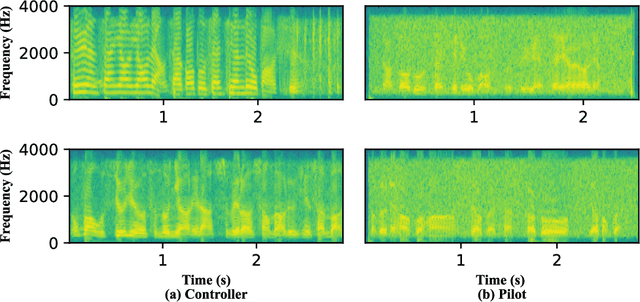

Automatic spoken instruction understanding (SIU) of the controller-pilot conversations in the air traffic control (ATC) requires not only recognizing the words and semantics of the speech but also determining the role of the speaker. However, few of the published works on the automatic understanding systems in air traffic communication focus on speaker role identification (SRI). In this paper, we formulate the SRI task of controller-pilot communication as a binary classification problem. Furthermore, the text-based, speech-based, and speech and text based multi-modal methods are proposed to achieve a comprehensive comparison of the SRI task. To ablate the impacts of the comparative approaches, various advanced neural network architectures are applied to optimize the implementation of text-based and speech-based methods. Most importantly, a multi-modal speaker role identification network (MMSRINet) is designed to achieve the SRI task by considering both the speech and textual modality features. To aggregate modality features, the modal fusion module is proposed to fuse and squeeze acoustic and textual representations by modal attention mechanism and self-attention pooling layer, respectively. Finally, the comparative approaches are validated on the ATCSpeech corpus collected from a real-world ATC environment. The experimental results demonstrate that all the comparative approaches are worked for the SRI task, and the proposed MMSRINet shows the competitive performance and robustness than the other methods on both seen and unseen data, achieving 98.56%, and 98.08% accuracy, respectively.
ATCSpeechNet: A multilingual end-to-end speech recognition framework for air traffic control systems
Feb 17, 2021
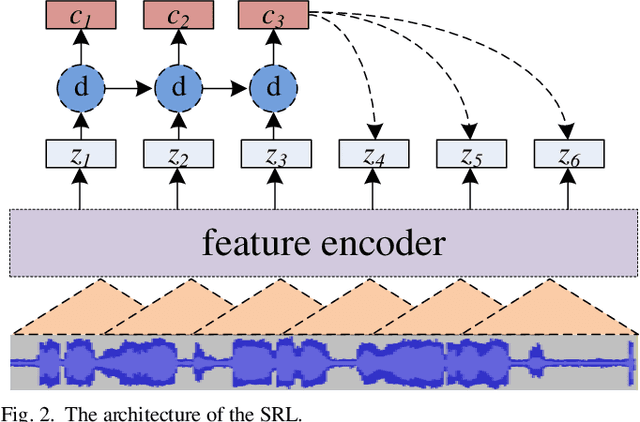
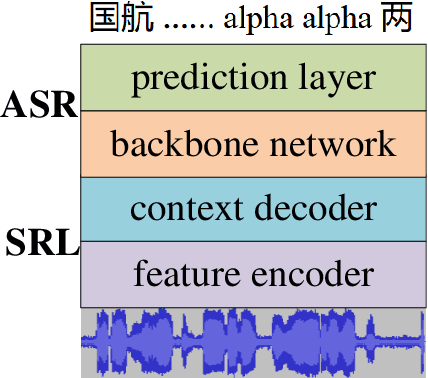

In this paper, a multilingual end-to-end framework, called as ATCSpeechNet, is proposed to tackle the issue of translating communication speech into human-readable text in air traffic control (ATC) systems. In the proposed framework, we focus on integrating the multilingual automatic speech recognition (ASR) into one model, in which an end-to-end paradigm is developed to convert speech waveform into text directly, without any feature engineering or lexicon. In order to make up for the deficiency of the handcrafted feature engineering caused by ATC challenges, a speech representation learning (SRL) network is proposed to capture robust and discriminative speech representations from the raw wave. The self-supervised training strategy is adopted to optimize the SRL network from unlabeled data, and further to predict the speech features, i.e., wave-to-feature. An end-to-end architecture is improved to complete the ASR task, in which a grapheme-based modeling unit is applied to address the multilingual ASR issue. Facing the problem of small transcribed samples in the ATC domain, an unsupervised approach with mask prediction is applied to pre-train the backbone network of the ASR model on unlabeled data by a feature-to-feature process. Finally, by integrating the SRL with ASR, an end-to-end multilingual ASR framework is formulated in a supervised manner, which is able to translate the raw wave into text in one model, i.e., wave-to-text. Experimental results on the ATCSpeech corpus demonstrate that the proposed approach achieves a high performance with a very small labeled corpus and less resource consumption, only 4.20% label error rate on the 58-hour transcribed corpus. Compared to the baseline model, the proposed approach obtains over 100% relative performance improvement which can be further enhanced with the increasing of the size of the transcribed samples.