 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Speaker Role Identification in Air Traffic Communication Using Deep Learning Approaches
Paper and Code
Nov 03, 2021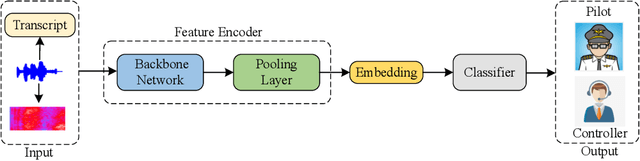


Automatic spoken instruction understanding (SIU) of the controller-pilot conversations in the air traffic control (ATC) requires not only recognizing the words and semantics of the speech but also determining the role of the speaker. However, few of the published works on the automatic understanding systems in air traffic communication focus on speaker role identification (SRI). In this paper, we formulate the SRI task of controller-pilot communication as a binary classification problem. Furthermore, the text-based, speech-based, and speech and text based multi-modal methods are proposed to achieve a comprehensive comparison of the SRI task. To ablate the impacts of the comparative approaches, various advanced neural network architectures are applied to optimize the implementation of text-based and speech-based methods. Most importantly, a multi-modal speaker role identification network (MMSRINet) is designed to achieve the SRI task by considering both the speech and textual modality features. To aggregate modality features, the modal fusion module is proposed to fuse and squeeze acoustic and textual representations by modal attention mechanism and self-attention pooling layer, respectively. Finally, the comparative approaches are validated on the ATCSpeech corpus collected from a real-world ATC environment. The experimental results demonstrate that all the comparative approaches are worked for the SRI task, and the proposed MMSRINet shows the competitive performance and robustness than the other methods on both seen and unseen data, achieving 98.56%, and 98.08% accuracy, respectively.