 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogo-LLM: Local and Global Modeling with Large Language Models for Time Series Forecasting
May 16, 2025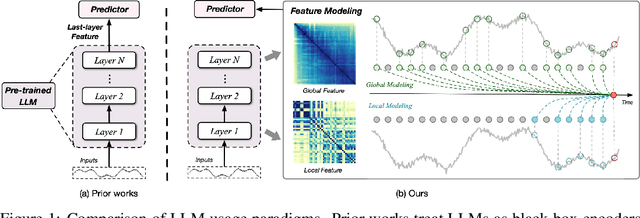
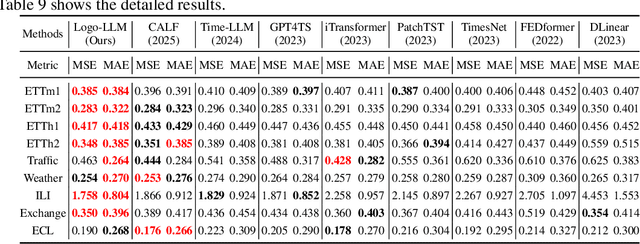
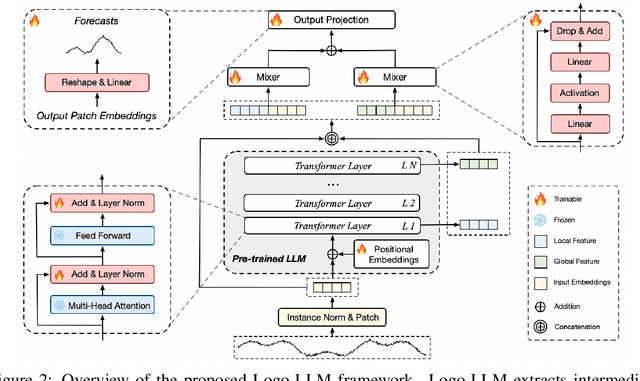
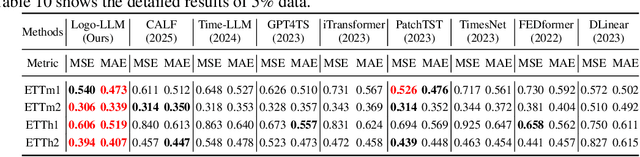
Time series forecasting is critical across multiple domains, where time series data exhibits both local patterns and global dependencies. While Transformer-based methods effectively capture global dependencies, they often overlook short-term local variations in time series. Recent methods that adapt large language models (LLMs) into time series forecasting inherit this limitation by treating LLMs as black-box encoders, relying solely on the final-layer output and underutilizing hierarchical representations. To address this limitation, we propose Logo-LLM, a novel LLM-based framework that explicitly extracts and models multi-scale temporal features from different layers of a pre-trained LLM. Through empirical analysis, we show that shallow layers of LLMs capture local dynamics in time series, while deeper layers encode global trends. Moreover, Logo-LLM introduces lightweight Local-Mixer and Global-Mixer modules to align and integrate features with the temporal input across layers. Extensive experiments demonstrate that Logo-LLM achieves superior performance across diverse benchmarks, with strong generalization in few-shot and zero-shot settings while maintaining low computational overhead.
DR-RAG: Applying Dynamic Document Relevance to Retrieval-Augmented Generation for Question-Answering
Jun 12, 2024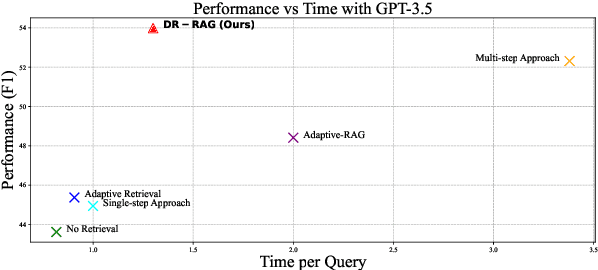

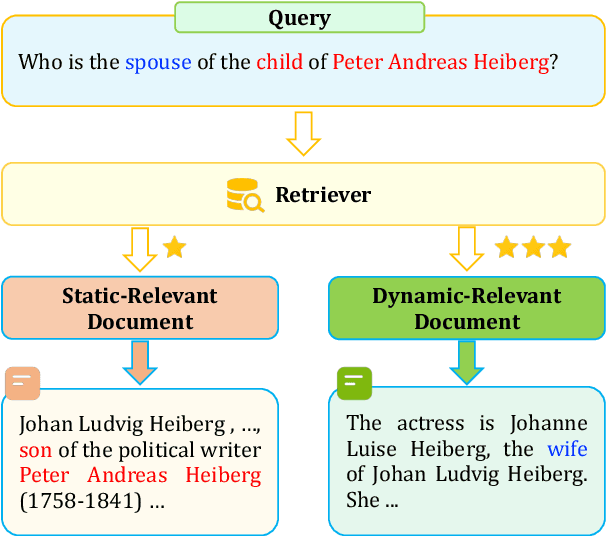

Retrieval-Augmented Generation (RAG) has significantly demonstrated the performance of Large Language Models (LLMs) in the knowledge-intensive tasks, such as Question-Answering (QA). RAG expands the query context by incorporating external knowledge bases to enhance the response accuracy. However, it would be inefficient to access LLMs multiple times for each query and unreliable to retrieve all the relevant documents by a single query. We find that even though there is low relevance between some critical documents and query, it is possible to retrieve the remaining documents by combining parts of the documents with the query. To mine the relevance, a two-stage retrieval framework called Dynamic-Relevant Retrieval-Augmented Generation (DR-RAG) is proposed to improve document retrieval recall and the accuracy of answers while maintaining efficiency. Also, a small classifier is applied to two different selection strategies to determine the contribution of the retrieved documents to answering the query and retrieve the relatively relevant documents. Meanwhile, DR-RAG call the LLMs only once, which significantly improves the efficiency of the experiment. The experimental results on multi-hop QA datasets show that DR-RAG can significantly improve the accuracy of the answers and achieve new progress in QA systems.
Effective Unsupervised Constrained Text Generation based on Perturbed Masking
Apr 24, 2024Unsupervised constrained text generation aims to generate text under a given set of constraints without any supervised data. Current state-of-the-art methods stochastically sample edit positions and actions, which may cause unnecessary search steps. In this paper, we propose PMCTG to improve effectiveness by searching for the best edit position and action in each step. Specifically, PMCTG extends perturbed masking technique to effectively search for the most incongruent token to edit. Then it introduces four multi-aspect scoring functions to select edit action to further reduce search difficulty. Since PMCTG does not require supervised data, it could be applied to different generation tasks. We show that under the unsupervised setting, PMCTG achieves new state-of-the-art results in two representative tasks, namely keywords-to-sentence generation and paraphrasing.
WinNet:time series forecasting with a window-enhanced period extracting and interacting
Nov 01, 2023Recently, Transformer-based methods have significantly improved state-of-the-art time series forecasting results, but they suffer from high computational costs and the inability to capture the long and short periodicity of time series. We present a highly accurate and simply structured CNN-based model for long-term time series forecasting tasks, called WinNet, including (i) Inter-Intra Period Encoder (I2PE) to transform 1D sequence into 2D tensor with long and short periodicity according to the predefined periodic window, (ii) Two-Dimensional Period Decomposition (TDPD) to model period-trend and oscillation terms, and (iii) Decomposition Correlation Block (DCB) to leverage the correlations of the period-trend and oscillation terms to support the prediction tasks by CNNs. Results on nine benchmark datasets show that the WinNet can achieve SOTA performance and lower computational complexity over CNN-, MLP-, Transformer-based approaches. The WinNet provides potential for the CNN-based methods in the time series forecasting tasks, with perfect tradeoff between performance and efficiency.
MIGA: A Unified Multi-task Generation Framework for Conversational Text-to-SQL
Dec 19, 2022



Conversational text-to-SQL is designed to translate multi-turn natural language questions into their corresponding SQL queries. Most state-of-the-art conversational text- to-SQL methods are incompatible with generative pre-trained language models (PLMs), such as T5. In this paper, we present a two-stage unified MultI-task Generation frAmework (MIGA) that leverages PLMs' ability to tackle conversational text-to-SQL. In the pre-training stage, MIGA first decomposes the main task into several related sub-tasks and then unifies them into the same sequence-to-sequence (Seq2Seq) paradigm with task-specific natural language prompts to boost the main task from multi-task training. Later in the fine-tuning stage, we propose four SQL perturbations to alleviate the error propagation problem. MIGA tends to achieve state-of-the-art performance on two benchmarks (SparC and CoSQL). We also provide extensive analyses and discussions to shed light on some new perspectives for conversational text-to-SQL.
A Clarifying Question Selection System from NTES_ALONG in Convai3 Challenge
Oct 28, 2020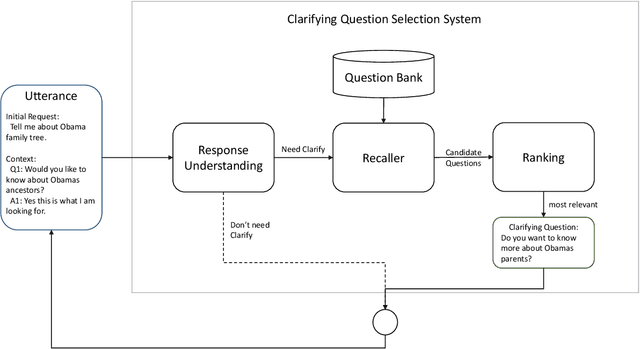
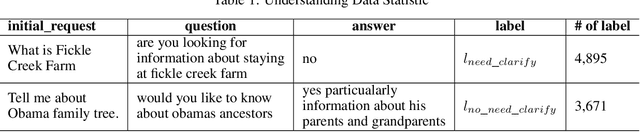

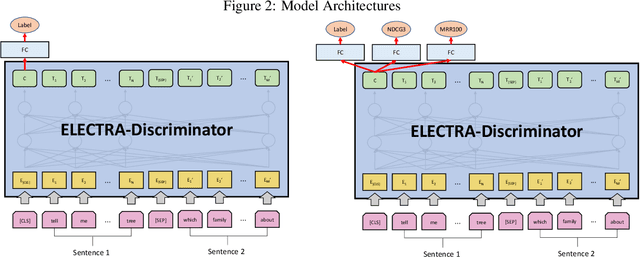
This paper presents the participation of NTES\_ALONG team for the ClariQ challenge at Search-oriented Conversational AI (SCAI) EMNLP workshop in 2020. The challenge asks for a complete conversational information retrieval system that can understanding and generating clarification questions. We propose a clarifying question selection system which consists of response understanding, candidate question recalling and clarifying question ranking. We fine-tune a RoBERTa model to understand user's responses and use an enhanced BM25 model to recall the candidate questions. In clarifying question ranking stage, we reconstruct the training dataset and propose two models based on ELECTRA. Finally we ensemble the models by summing up their output probabilities and choose the question with the highest probability as the clarification question. Experiments show that our ensemble ranking model outperforms in the document relevance task and achieves the best recall@[20,30] metrics in question relevance task.