 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Unsupervised Constrained Text Generation based on Perturbed Masking
Apr 24, 2024Unsupervised constrained text generation aims to generate text under a given set of constraints without any supervised data. Current state-of-the-art methods stochastically sample edit positions and actions, which may cause unnecessary search steps. In this paper, we propose PMCTG to improve effectiveness by searching for the best edit position and action in each step. Specifically, PMCTG extends perturbed masking technique to effectively search for the most incongruent token to edit. Then it introduces four multi-aspect scoring functions to select edit action to further reduce search difficulty. Since PMCTG does not require supervised data, it could be applied to different generation tasks. We show that under the unsupervised setting, PMCTG achieves new state-of-the-art results in two representative tasks, namely keywords-to-sentence generation and paraphrasing.
How to choose "Good" Samples for Text Data Augmentation
Feb 02, 2023



Deep learning-based text classification models need abundant labeled data to obtain competitive performance. Unfortunately, annotating large-size corpus is time-consuming and laborious. To tackle this, multiple researches try to use data augmentation to expand the corpus size. However, data augmentation may potentially produce some noisy augmented samples. There are currently no works exploring sample selection for augmented samples in nature language processing field. In this paper, we propose a novel self-training selection framework with two selectors to select the high-quality samples from data augmentation. Specifically, we firstly use an entropy-based strategy and the model prediction to select augmented samples. Considering some samples with high quality at the above step may be wrongly filtered, we propose to recall them from two perspectives of word overlap and semantic similarity. Experimental results show the effectiveness and simplicity of our framework.
MIGA: A Unified Multi-task Generation Framework for Conversational Text-to-SQL
Dec 19, 2022



Conversational text-to-SQL is designed to translate multi-turn natural language questions into their corresponding SQL queries. Most state-of-the-art conversational text- to-SQL methods are incompatible with generative pre-trained language models (PLMs), such as T5. In this paper, we present a two-stage unified MultI-task Generation frAmework (MIGA) that leverages PLMs' ability to tackle conversational text-to-SQL. In the pre-training stage, MIGA first decomposes the main task into several related sub-tasks and then unifies them into the same sequence-to-sequence (Seq2Seq) paradigm with task-specific natural language prompts to boost the main task from multi-task training. Later in the fine-tuning stage, we propose four SQL perturbations to alleviate the error propagation problem. MIGA tends to achieve state-of-the-art performance on two benchmarks (SparC and CoSQL). We also provide extensive analyses and discussions to shed light on some new perspectives for conversational text-to-SQL.
Yunshan Cup 2020: Overview of the Part-of-Speech Tagging Task for Low-resourced Languages
Apr 06, 2022
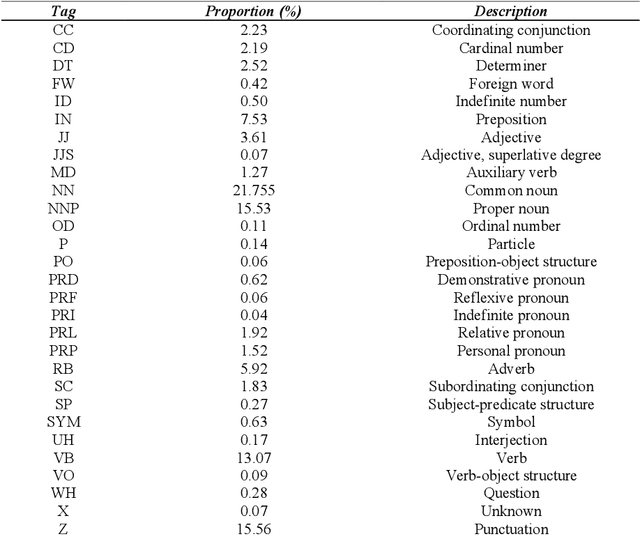
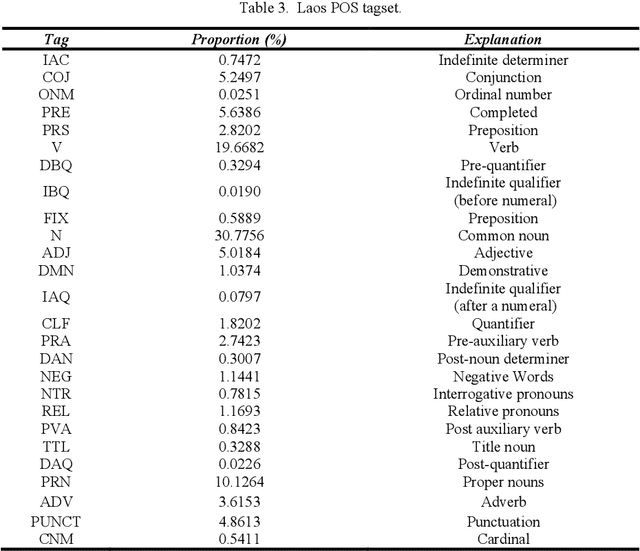
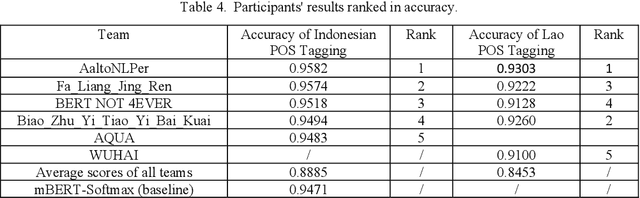
The Yunshan Cup 2020 track focused on creating a framework for evaluating different methods of part-of-speech (POS). There were two tasks for this track: (1) POS tagging for the Indonesian language, and (2) POS tagging for the Lao tagging. The Indonesian dataset is comprised of 10000 sentences from Indonesian news within 29 tags. And the Lao dataset consists of 8000 sentences within 27 tags. 25 teams registered for the task. The methods of participants ranged from feature-based to neural networks using either classical machine learning techniques or ensemble methods. The best performing results achieve an accuracy of 95.82% for Indonesian and 93.03%, showing that neural sequence labeling models significantly outperform classic feature-based methods and rule-based methods.
A Dual-Contrastive Framework for Low-Resource Cross-Lingual Named Entity Recognition
Apr 02, 2022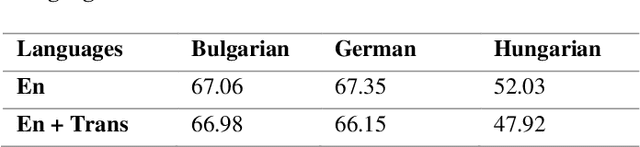
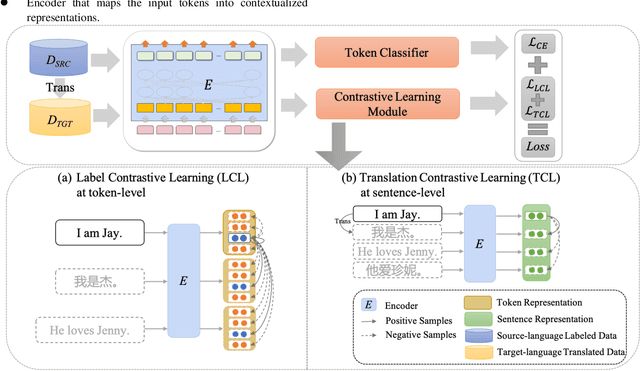
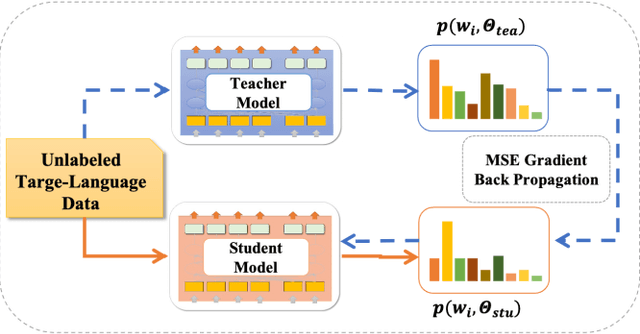
Cross-lingual Named Entity Recognition (NER) has recently become a research hotspot because it can alleviate the data-hungry problem for low-resource languages. However, few researches have focused on the scenario where the source-language labeled data is also limited in some specific domains. A common approach for this scenario is to generate more training data through translation or generation-based data augmentation method. Unfortunately, we find that simply combining source-language data and the corresponding translation cannot fully exploit the translated data and the improvements obtained are somewhat limited. In this paper, we describe our novel dual-contrastive framework ConCNER for cross-lingual NER under the scenario of limited source-language labeled data. Specifically, based on the source-language samples and their translations, we design two contrastive objectives for cross-language NER at different grammatical levels, namely Translation Contrastive Learning (TCL) to close sentence representations between translated sentence pairs and Label Contrastive Learning (LCL) to close token representations within the same labels. Furthermore, we utilize knowledge distillation method where the NER model trained above is used as the teacher to train a student model on unlabeled target-language data to better fit the target language. We conduct extensive experiments on a wide variety of target languages, and the results demonstrate that ConCNER tends to outperform multiple baseline methods. For reproducibility, our code for this paper is available at https://github.com/GKLMIP/ConCNER.
CL-XABSA: Contrastive Learning for Cross-lingual Aspect-based Sentiment Analysis
Apr 02, 2022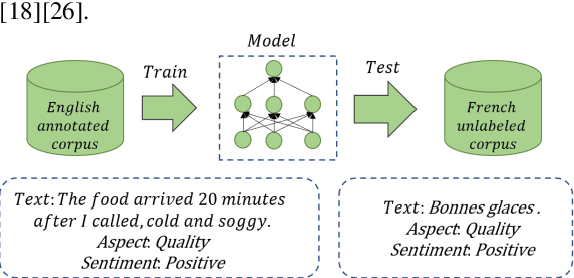
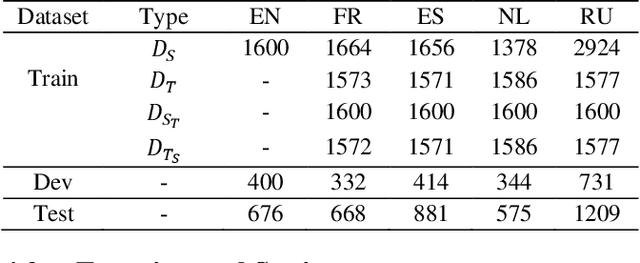
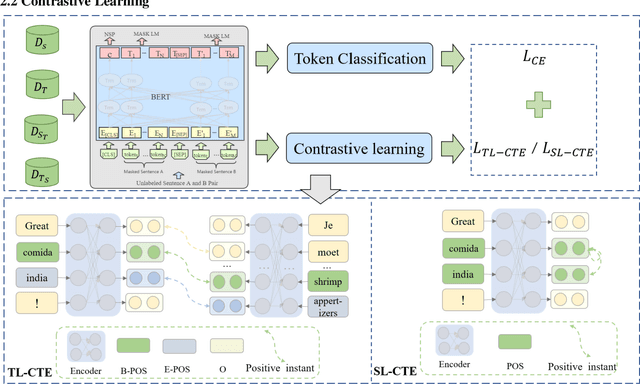
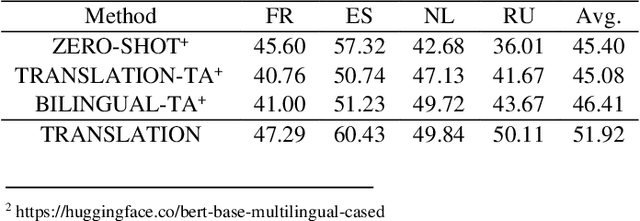
As an extensive research in the field of Natural language processing (NLP), aspect-based sentiment analysis (ABSA) is the task of predicting the sentiment expressed in a text relative to the corresponding aspect. Unfortunately, most languages lack of sufficient annotation resources, thus more and more recent researchers focus on cross-lingual aspect-based sentiment analysis (XABSA). However, most recent researches only concentrate on cross-lingual data alignment instead of model alignment. To this end, we propose a novel framework, CL-XABSA: Contrastive Learning for Cross-lingual Aspect-Based Sentiment Analysis. Specifically, we design two contrastive strategies, token level contrastive learning of token embeddings (TL-CTE) and sentiment level contrastive learning of token embeddings (SL-CTE), to regularize the semantic space of source and target language to be more uniform. Since our framework can receive datasets in multiple languages during training, our framework can be adapted not only for XABSA task, but also for multilingual aspect-based sentiment analysis (MABSA). To further improve the performance of our model, we perform knowledge distillation technology leveraging data from unlabeled target language. In the distillation XABSA task, we further explore the comparative effectiveness of different data (source dataset, translated dataset, and code-switched dataset). The results demonstrate that the proposed method has a certain improvement in the three tasks of XABSA, distillation XABSA and MABSA. For reproducibility, our code for this paper is available at https://github.com/GKLMIP/CL-XABSA.
LaoPLM: Pre-trained Language Models for Lao
Oct 14, 2021

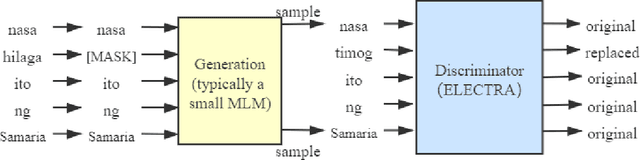

Trained on the large corpus, pre-trained language models (PLMs) can capture different levels of concepts in context and hence generate universal language representations. They can benefit multiple downstream natural language processing (NLP) tasks. Although PTMs have been widely used in most NLP applications, especially for high-resource languages such as English, it is under-represented in Lao NLP research. Previous work on Lao has been hampered by the lack of annotated datasets and the sparsity of language resources. In this work, we construct a text classification dataset to alleviate the resource-scare situation of the Lao language. We additionally present the first transformer-based PTMs for Lao with four versions: BERT-small, BERT-base, ELECTRA-small and ELECTRA-base, and evaluate it over two downstream tasks: part-of-speech tagging and text classification. Experiments demonstrate the effectiveness of our Lao models. We will release our models and datasets to the community, hoping to facilitate the future development of Lao NLP applications.
An Open-Source Dataset and A Multi-Task Model for Malay Named Entity Recognition
Sep 03, 2021



Named entity recognition (NER) is a fundamental task of natural language processing (NLP). However, most state-of-the-art research is mainly oriented to high-resource languages such as English and has not been widely applied to low-resource languages. In Malay language, relevant NER resources are limited. In this work, we propose a dataset construction framework, which is based on labeled datasets of homologous languages and iterative optimization, to build a Malay NER dataset (MYNER) comprising 28,991 sentences (over 384 thousand tokens). Additionally, to better integrate boundary information for NER, we propose a multi-task (MT) model with a bidirectional revision (Bi-revision) mechanism for Malay NER task. Specifically, an auxiliary task, boundary detection, is introduced to improve NER training in both explicit and implicit ways. Furthermore, a gated ignoring mechanism is proposed to conduct conditional label transfer and alleviate error propagation by the auxiliary task. Experimental results demonstrate that our model achieves comparable results over baselines on MYNER. The dataset and the model in this paper would be publicly released as a benchmark dataset.