 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagineBench: Evaluating Reinforcement Learning with Large Language Model Rollouts
May 15, 2025A central challenge in reinforcement learning (RL) is its dependence on extensive real-world interaction data to learn task-specific policies. While recent work demonstrates that large language models (LLMs) can mitigate this limitation by generating synthetic experience (noted as imaginary rollouts) for mastering novel tasks, progress in this emerging field is hindered due to the lack of a standard benchmark. To bridge this gap, we introduce ImagineBench, the first comprehensive benchmark for evaluating offline RL algorithms that leverage both real rollouts and LLM-imaginary rollouts. The key features of ImagineBench include: (1) datasets comprising environment-collected and LLM-imaginary rollouts; (2) diverse domains of environments covering locomotion, robotic manipulation, and navigation tasks; and (3) natural language task instructions with varying complexity levels to facilitate language-conditioned policy learning. Through systematic evaluation of state-of-the-art offline RL algorithms, we observe that simply applying existing offline RL algorithms leads to suboptimal performance on unseen tasks, achieving 35.44% success rate in hard tasks in contrast to 64.37% of method training on real rollouts for hard tasks. This result highlights the need for algorithm advancements to better leverage LLM-imaginary rollouts. Additionally, we identify key opportunities for future research: including better utilization of imaginary rollouts, fast online adaptation and continual learning, and extension to multi-modal tasks. Our code is publicly available at https://github.com/LAMDA-RL/ImagineBench.
CLASS: Enhancing Cross-Modal Text-Molecule Retrieval Performance and Training Efficiency
Feb 17, 2025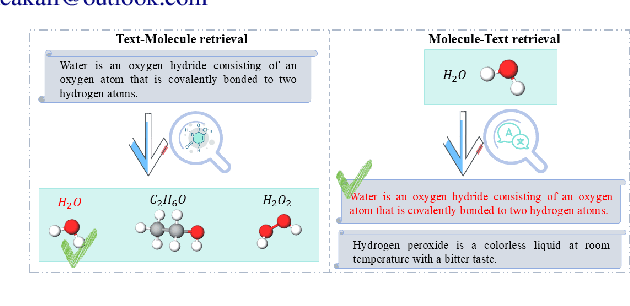
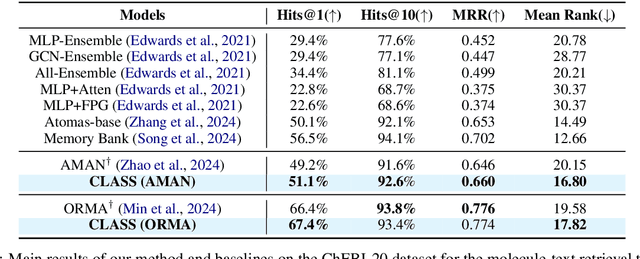
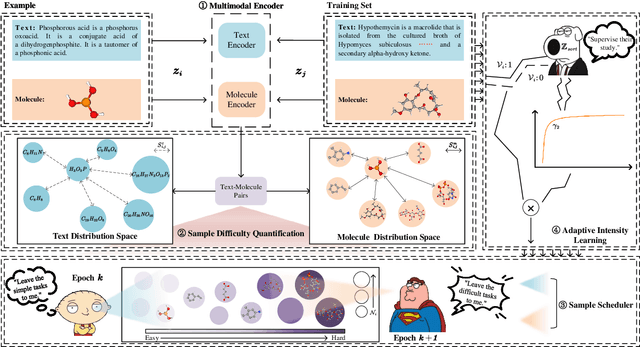
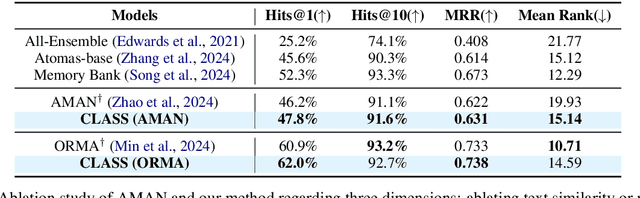
Cross-modal text-molecule retrieval task bridges molecule structures and natural language descriptions. Existing methods predominantly focus on aligning text modality and molecule modality, yet they overlook adaptively adjusting the learning states at different training stages and enhancing training efficiency. To tackle these challenges, this paper proposes a Curriculum Learning-bAsed croSS-modal text-molecule training framework (CLASS), which can be integrated with any backbone to yield promising performance improvement. Specifically, we quantify the sample difficulty considering both text modality and molecule modality, and design a sample scheduler to introduce training samples via an easy-to-difficult paradigm as the training advances, remarkably reducing the scale of training samples at the early stage of training and improving training efficiency. Moreover, we introduce adaptive intensity learning to increase the training intensity as the training progresses, which adaptively controls the learning intensity across all curriculum stages. Experimental results on the ChEBI-20 dataset demonstrate that our proposed method gains superior performance, simultaneously achieving prominent time savings.
A Simple Yet Effective Corpus Construction Framework for Indonesian Grammatical Error Correction
Oct 28, 2024Currently, the majority of research in grammatical error correction (GEC) is concentrated on universal languages, such as English and Chinese. Many low-resource languages lack accessible evaluation corpora. How to efficiently construct high-quality evaluation corpora for GEC in low-resource languages has become a significant challenge. To fill these gaps, in this paper, we present a framework for constructing GEC corpora. Specifically, we focus on Indonesian as our research language and construct an evaluation corpus for Indonesian GEC using the proposed framework, addressing the limitations of existing evaluation corpora in Indonesian. Furthermore, we investigate the feasibility of utilizing existing large language models (LLMs), such as GPT-3.5-Turbo and GPT-4, to streamline corpus annotation efforts in GEC tasks. The results demonstrate significant potential for enhancing the performance of LLMs in low-resource language settings. Our code and corpus can be obtained from https://github.com/GKLMIP/GEC-Construction-Framework.
Energy-Guided Diffusion Sampling for Offline-to-Online Reinforcement Learning
Jul 17, 2024



Combining offline and online reinforcement learning (RL) techniques is indeed crucial for achieving efficient and safe learning where data acquisition is expensive. Existing methods replay offline data directly in the online phase, resulting in a significant challenge of data distribution shift and subsequently causing inefficiency in online fine-tuning. To address this issue, we introduce an innovative approach, \textbf{E}nergy-guided \textbf{DI}ffusion \textbf{S}ampling (EDIS), which utilizes a diffusion model to extract prior knowledge from the offline dataset and employs energy functions to distill this knowledge for enhanced data generation in the online phase. The theoretical analysis demonstrates that EDIS exhibits reduced suboptimality compared to solely utilizing online data or directly reusing offline data. EDIS is a plug-in approach and can be combined with existing methods in offline-to-online RL setting. By implementing EDIS to off-the-shelf methods Cal-QL and IQL, we observe a notable 20% average improvement in empirical performance on MuJoCo, AntMaze, and Adroit environments. Code is available at \url{https://github.com/liuxhym/EDIS}.
$\text{Alpha}^2$: Discovering Logical Formulaic Alphas using Deep Reinforcement Learning
Jun 26, 2024



Alphas are pivotal in providing signals for quantitative trading. The industry highly values the discovery of formulaic alphas for their interpretability and ease of analysis, compared with the expressive yet overfitting-prone black-box alphas. In this work, we focus on discovering formulaic alphas. Prior studies on automatically generating a collection of formulaic alphas were mostly based on genetic programming (GP), which is known to suffer from the problems of being sensitive to the initial population, converting to local optima, and slow computation speed. Recent efforts employing deep reinforcement learning (DRL) for alpha discovery have not fully addressed key practical considerations such as alpha correlations and validity, which are crucial for their effectiveness. In this work, we propose a novel framework for alpha discovery using DRL by formulating the alpha discovery process as program construction. Our agent, $\text{Alpha}^2$, assembles an alpha program optimized for an evaluation metric. A search algorithm guided by DRL navigates through the search space based on value estimates for potential alpha outcomes. The evaluation metric encourages both the performance and the diversity of alphas for a better final trading strategy. Our formulation of searching alphas also brings the advantage of pre-calculation dimensional analysis, ensuring the logical soundness of alphas, and pruning the vast search space to a large extent. Empirical experiments on real-world stock markets demonstrates $\text{Alpha}^2$'s capability to identify a diverse set of logical and effective alphas, which significantly improves the performance of the final trading strategy. The code of our method is available at https://github.com/x35f/alpha2.
HateDebias: On the Diversity and Variability of Hate Speech Debiasing
Jun 07, 2024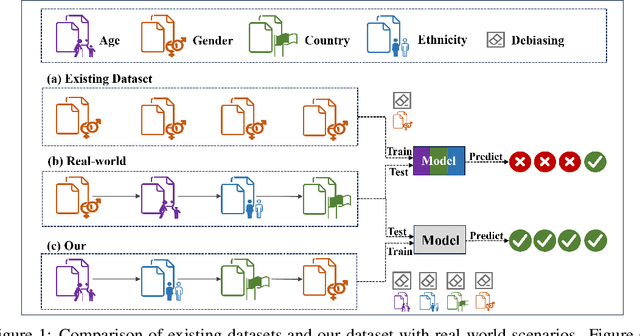



Hate speech on social media is ubiquitous but urgently controlled. Without detecting and mitigating the biases brought by hate speech, different types of ethical problems. While a number of datasets have been proposed to address the problem of hate speech detection, these datasets seldom consider the diversity and variability of bias, making it far from real-world scenarios. To fill this gap, we propose a benchmark, named HateDebias, to analyze the model ability of hate speech detection under continuous, changing environments. Specifically, to meet the diversity of biases, we collect existing hate speech detection datasets with different types of biases. To further meet the variability (i.e., the changing of bias attributes in datasets), we reorganize datasets to follow the continuous learning setting. We evaluate the detection accuracy of models trained on the datasets with a single type of bias with the performance on the HateDebias, where a significant performance drop is observed. To provide a potential direction for debiasing, we further propose a debiasing framework based on continuous learning and bias information regularization, as well as the memory replay strategies to ensure the debiasing ability of the model. Experiment results on the proposed benchmark show that the aforementioned method can improve several baselines with a distinguished margin, highlighting its effectiveness in real-world applications.
A BERT-based Unsupervised Grammatical Error Correction Framework
Mar 30, 2023



Grammatical error correction (GEC) is a challenging task of natural language processing techniques. While more attempts are being made in this approach for universal languages like English or Chinese, relatively little work has been done for low-resource languages for the lack of large annotated corpora. In low-resource languages, the current unsupervised GEC based on language model scoring performs well. However, the pre-trained language model is still to be explored in this context. This study proposes a BERT-based unsupervised GEC framework, where GEC is viewed as multi-class classification task. The framework contains three modules: data flow construction module, sentence perplexity scoring module, and error detecting and correcting module. We propose a novel scoring method for pseudo-perplexity to evaluate a sentence's probable correctness and construct a Tagalog corpus for Tagalog GEC research. It obtains competitive performance on the Tagalog corpus we construct and open-source Indonesian corpus and it demonstrates that our framework is complementary to baseline method for low-resource GEC task.
How To Guide Your Learner: Imitation Learning with Active Adaptive Expert Involvement
Mar 03, 2023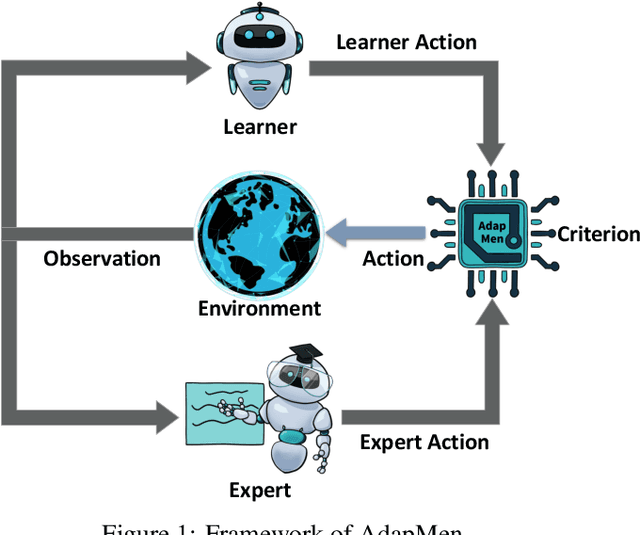

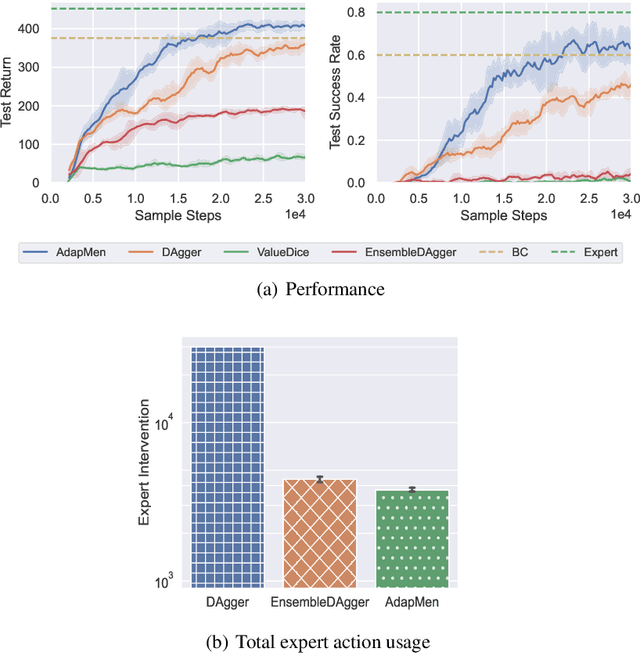

Imitation learning aims to mimic the behavior of experts without explicit reward signals. Passive imitation learning methods which use static expert datasets typically suffer from compounding error, low sample efficiency, and high hyper-parameter sensitivity. In contrast, active imitation learning methods solicit expert interventions to address the limitations. However, recent active imitation learning methods are designed based on human intuitions or empirical experience without theoretical guarantee. In this paper, we propose a novel active imitation learning framework based on a teacher-student interaction model, in which the teacher's goal is to identify the best teaching behavior and actively affect the student's learning process. By solving the optimization objective of this framework, we propose a practical implementation, naming it AdapMen. Theoretical analysis shows that AdapMen can improve the error bound and avoid compounding error under mild conditions. Experiments on the MetaDrive benchmark and Atari 2600 games validate our theoretical analysis and show that our method achieves near-expert performance with much less expert involvement and total sampling steps than previous methods. The code is available at https://github.com/liuxhym/AdapMen.
How to choose "Good" Samples for Text Data Augmentation
Feb 02, 2023



Deep learning-based text classification models need abundant labeled data to obtain competitive performance. Unfortunately, annotating large-size corpus is time-consuming and laborious. To tackle this, multiple researches try to use data augmentation to expand the corpus size. However, data augmentation may potentially produce some noisy augmented samples. There are currently no works exploring sample selection for augmented samples in nature language processing field. In this paper, we propose a novel self-training selection framework with two selectors to select the high-quality samples from data augmentation. Specifically, we firstly use an entropy-based strategy and the model prediction to select augmented samples. Considering some samples with high quality at the above step may be wrongly filtered, we propose to recall them from two perspectives of word overlap and semantic similarity. Experimental results show the effectiveness and simplicity of our framework.
A Chinese Spelling Check Framework Based on Reverse Contrastive Learning
Oct 25, 2022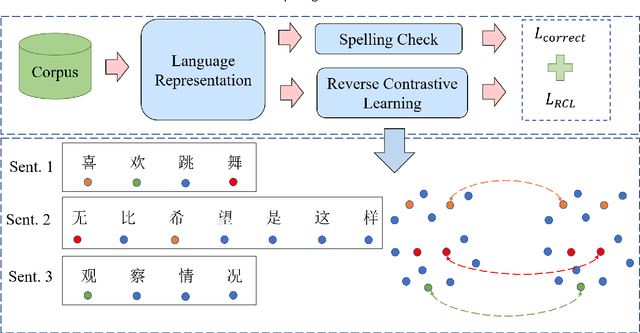
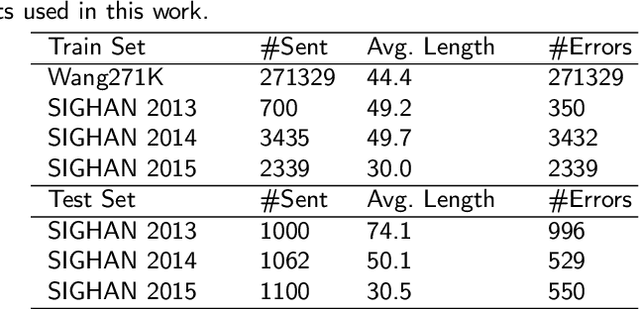
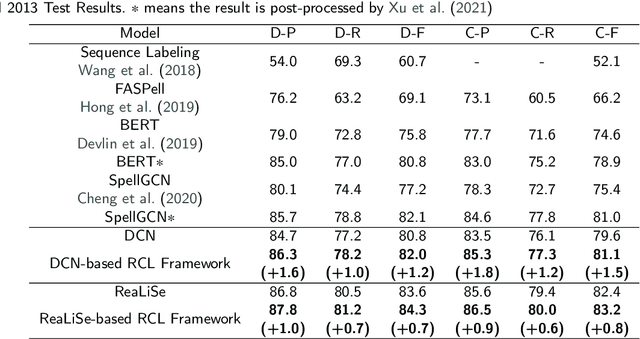
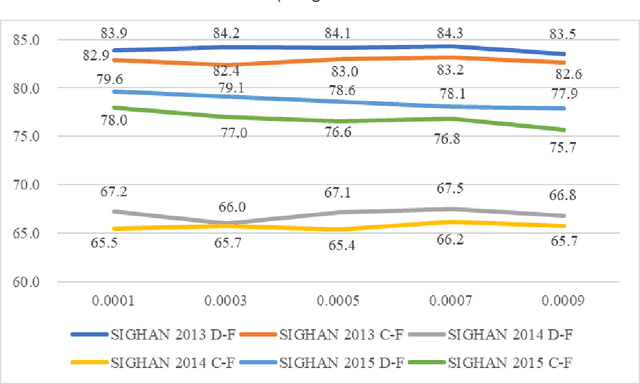
Chinese spelling check is a task to detect and correct spelling mistakes in Chinese text. Existing research aims to enhance the text representation and use multi-source information to improve the detection and correction capabilities of models, but does not pay too much attention to improving their ability to distinguish between confusable words. Contrastive learning, whose aim is to minimize the distance in representation space between similar sample pairs, has recently become a dominant technique in natural language processing. Inspired by contrastive learning, we present a novel framework for Chinese spelling checking, which consists of three modules: language representation, spelling check and reverse contrastive learning. Specifically, we propose a reverse contrastive learning strategy, which explicitly forces the model to minimize the agreement between the similar examples, namely, the phonetically and visually confusable characters. Experimental results show that our framework is model-agnostic and could be combined with existing Chinese spelling check models to yield state-of-the-art performance.