 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade-KDE: Robust Time-Series Restoration under Out-of-Distribution Impulse Corruptions
May 22, 2026Real-world time-series data in industrial sensing, healthcare, and energy systems is often corrupted by a mixture of Gaussian noise and occasional large-magnitude impulse outliers. For tasks that depend on local shape, such as ECG morphology analysis and battery degradation monitoring, the main requirement is not only low reconstruction error but also preservation of derivative peaks and task-critical features. We propose Cascade-KDE, a training-free restoration framework for corrupted time series. The method first estimates a two-dimensional temporal-amplitude density, then applies a Density-Truncated Robust Expectation to limit the influence of distant abnormal points, and finally refines the sequence through an exponential cascade with adaptive stopping. This design aims to improve robustness under out-of-distribution impulse corruptions while keeping the restored trajectory close to the original local structure. Across several benchmark datasets, the proposed method shows consistent gains over classical filters and representative learning-based baselines on curve fidelity, derivative preservation, downstream classification, and runtime efficiency. These results suggest that bounded density-based restoration is a practical option for feature-preserving preprocessing in noisy time-series pipelines.
Disentangling Task Conflicts in Multi-Task LoRA via Orthogonal Gradient Projection
Jan 14, 2026Multi-Task Learning (MTL) combined with Low-Rank Adaptation (LoRA) has emerged as a promising direction for parameter-efficient deployment of Large Language Models (LLMs). By sharing a single adapter across multiple tasks, one can significantly reduce storage overhead. However, this approach suffers from negative transfer, where conflicting gradient updates from distinct tasks degrade the performance of individual tasks compared to single-task fine-tuning. This problem is exacerbated in LoRA due to the low-rank constraint, which limits the optimization landscape's capacity to accommodate diverse task requirements. In this paper, we propose Ortho-LoRA, a gradient projection method specifically tailored for the bipartite structure of LoRA. Ortho-LoRA dynamically projects conflicting task gradients onto the orthogonal complement of each other within the intrinsic LoRA subspace. Extensive experiments on the GLUE benchmark demonstrate that Ortho-LoRA effectively mitigates task interference, outperforming standard joint training and recovering 95\% of the performance gap between multi-task and single-task baselines with negligible computational overhead.
Two-Pronged Human Evaluation of ChatGPT Self-Correction in Radiology Report Simplification
Jun 27, 2024



Radiology reports are highly technical documents aimed primarily at doctor-doctor communication. There has been an increasing interest in sharing those reports with patients, necessitating providing them patient-friendly simplifications of the original reports. This study explores the suitability of large language models in automatically generating those simplifications. We examine the usefulness of chain-of-thought and self-correction prompting mechanisms in this domain. We also propose a new evaluation protocol that employs radiologists and laypeople, where radiologists verify the factual correctness of simplifications, and laypeople assess simplicity and comprehension. Our experimental results demonstrate the effectiveness of self-correction prompting in producing high-quality simplifications. Our findings illuminate the preferences of radiologists and laypeople regarding text simplification, informing future research on this topic.
NPF-200: A Multi-Modal Eye Fixation Dataset and Method for Non-Photorealistic Videos
Aug 23, 2023Non-photorealistic videos are in demand with the wave of the metaverse, but lack of sufficient research studies. This work aims to take a step forward to understand how humans perceive non-photorealistic videos with eye fixation (\ie, saliency detection), which is critical for enhancing media production, artistic design, and game user experience. To fill in the gap of missing a suitable dataset for this research line, we present NPF-200, the first large-scale multi-modal dataset of purely non-photorealistic videos with eye fixations. Our dataset has three characteristics: 1) it contains soundtracks that are essential according to vision and psychological studies; 2) it includes diverse semantic content and videos are of high-quality; 3) it has rich motions across and within videos. We conduct a series of analyses to gain deeper insights into this task and compare several state-of-the-art methods to explore the gap between natural images and non-photorealistic data. Additionally, as the human attention system tends to extract visual and audio features with different frequencies, we propose a universal frequency-aware multi-modal non-photorealistic saliency detection model called NPSNet, demonstrating the state-of-the-art performance of our task. The results uncover strengths and weaknesses of multi-modal network design and multi-domain training, opening up promising directions for future works. {Our dataset and code can be found at \url{https://github.com/Yangziyu/NPF200}}.
How to choose "Good" Samples for Text Data Augmentation
Feb 02, 2023



Deep learning-based text classification models need abundant labeled data to obtain competitive performance. Unfortunately, annotating large-size corpus is time-consuming and laborious. To tackle this, multiple researches try to use data augmentation to expand the corpus size. However, data augmentation may potentially produce some noisy augmented samples. There are currently no works exploring sample selection for augmented samples in nature language processing field. In this paper, we propose a novel self-training selection framework with two selectors to select the high-quality samples from data augmentation. Specifically, we firstly use an entropy-based strategy and the model prediction to select augmented samples. Considering some samples with high quality at the above step may be wrongly filtered, we propose to recall them from two perspectives of word overlap and semantic similarity. Experimental results show the effectiveness and simplicity of our framework.
A New Evaluation Method: Evaluation Data and Metrics for Chinese Grammar Error Correction
Apr 30, 2022
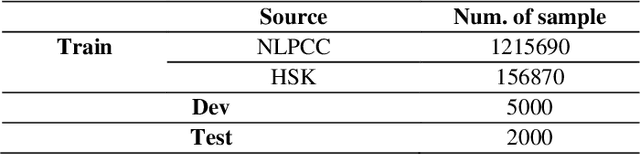
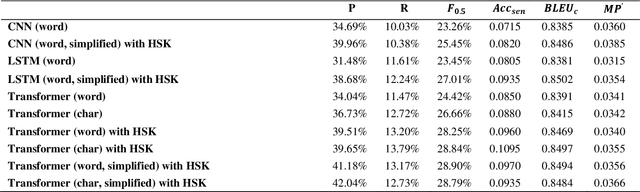

As a fundamental task in natural language processing, Chinese Grammatical Error Correction (CGEC) has gradually received widespread attention and become a research hotspot. However, one obvious deficiency for the existing CGEC evaluation system is that the evaluation values are significantly influenced by the Chinese word segmentation results or different language models. The evaluation values of the same error correction model can vary considerably under different word segmentation systems or different language models. However, it is expected that these metrics should be independent of the word segmentation results and language models, as they may lead to a lack of uniqueness and comparability in the evaluation of different methods. To this end, we propose three novel evaluation metrics for CGEC in two dimensions: reference-based and reference-less. In terms of the reference-based metric, we introduce sentence-level accuracy and char-level BLEU to evaluate the corrected sentences. Besides, in terms of the reference-less metric, we adopt char-level meaning preservation to measure the semantic preservation degree of the corrected sentences. We deeply evaluate and analyze the reasonableness and validity of the three proposed metrics, and we expect them to become a new standard for CGEC.
A Dual-Contrastive Framework for Low-Resource Cross-Lingual Named Entity Recognition
Apr 02, 2022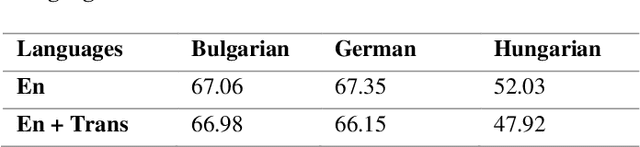
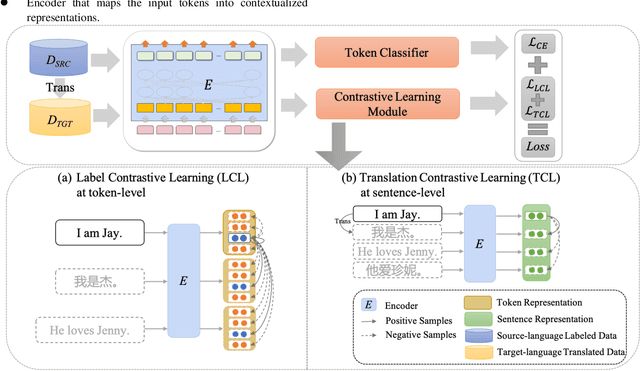
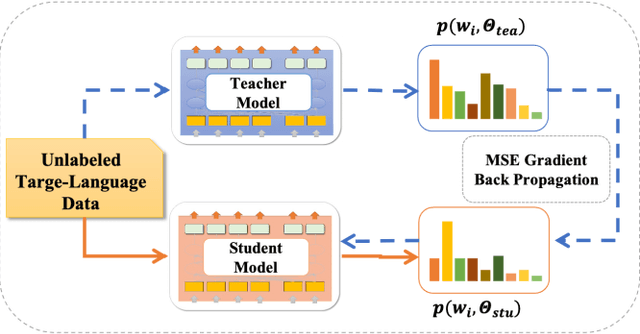
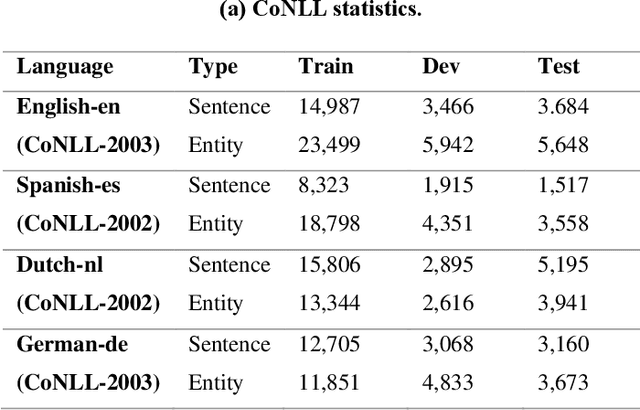
Cross-lingual Named Entity Recognition (NER) has recently become a research hotspot because it can alleviate the data-hungry problem for low-resource languages. However, few researches have focused on the scenario where the source-language labeled data is also limited in some specific domains. A common approach for this scenario is to generate more training data through translation or generation-based data augmentation method. Unfortunately, we find that simply combining source-language data and the corresponding translation cannot fully exploit the translated data and the improvements obtained are somewhat limited. In this paper, we describe our novel dual-contrastive framework ConCNER for cross-lingual NER under the scenario of limited source-language labeled data. Specifically, based on the source-language samples and their translations, we design two contrastive objectives for cross-language NER at different grammatical levels, namely Translation Contrastive Learning (TCL) to close sentence representations between translated sentence pairs and Label Contrastive Learning (LCL) to close token representations within the same labels. Furthermore, we utilize knowledge distillation method where the NER model trained above is used as the teacher to train a student model on unlabeled target-language data to better fit the target language. We conduct extensive experiments on a wide variety of target languages, and the results demonstrate that ConCNER tends to outperform multiple baseline methods. For reproducibility, our code for this paper is available at https://github.com/GKLMIP/ConCNER.
LaoPLM: Pre-trained Language Models for Lao
Oct 14, 2021

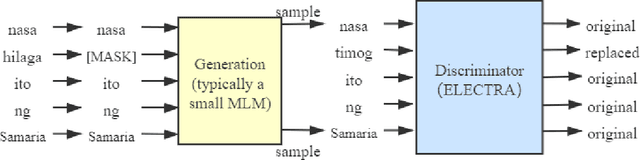

Trained on the large corpus, pre-trained language models (PLMs) can capture different levels of concepts in context and hence generate universal language representations. They can benefit multiple downstream natural language processing (NLP) tasks. Although PTMs have been widely used in most NLP applications, especially for high-resource languages such as English, it is under-represented in Lao NLP research. Previous work on Lao has been hampered by the lack of annotated datasets and the sparsity of language resources. In this work, we construct a text classification dataset to alleviate the resource-scare situation of the Lao language. We additionally present the first transformer-based PTMs for Lao with four versions: BERT-small, BERT-base, ELECTRA-small and ELECTRA-base, and evaluate it over two downstream tasks: part-of-speech tagging and text classification. Experiments demonstrate the effectiveness of our Lao models. We will release our models and datasets to the community, hoping to facilitate the future development of Lao NLP applications.