 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Pronged Human Evaluation of ChatGPT Self-Correction in Radiology Report Simplification
Jun 27, 2024



Radiology reports are highly technical documents aimed primarily at doctor-doctor communication. There has been an increasing interest in sharing those reports with patients, necessitating providing them patient-friendly simplifications of the original reports. This study explores the suitability of large language models in automatically generating those simplifications. We examine the usefulness of chain-of-thought and self-correction prompting mechanisms in this domain. We also propose a new evaluation protocol that employs radiologists and laypeople, where radiologists verify the factual correctness of simplifications, and laypeople assess simplicity and comprehension. Our experimental results demonstrate the effectiveness of self-correction prompting in producing high-quality simplifications. Our findings illuminate the preferences of radiologists and laypeople regarding text simplification, informing future research on this topic.
LLMs' Classification Performance is Overclaimed
Jun 23, 2024In many classification tasks designed for AI or human to solve, gold labels are typically included within the label space by default, often posed as "which of the following is correct?" This standard setup has traditionally highlighted the strong performance of advanced AI, particularly top-performing Large Language Models (LLMs), in routine classification tasks. However, when the gold label is intentionally excluded from the label space, it becomes evident that LLMs still attempt to select from the available label candidates, even when none are correct. This raises a pivotal question: Do LLMs truly demonstrate their intelligence in understanding the essence of classification tasks? In this study, we evaluate both closed-source and open-source LLMs across representative classification tasks, arguing that the perceived performance of LLMs is overstated due to their inability to exhibit the expected comprehension of the task. This paper makes a threefold contribution: i) To our knowledge, this is the first work to identify the limitations of LLMs in classification tasks when gold labels are absent. We define this task as Classify-w/o-Gold and propose it as a new testbed for LLMs. ii) We introduce a benchmark, Know-No, comprising two existing classification tasks and one new task, to evaluate Classify-w/o-Gold. iii) This work defines and advocates for a new evaluation metric, OmniAccuracy, which assesses LLMs' performance in classification tasks both when gold labels are present and absent.
X-Shot: A Unified System to Handle Frequent, Few-shot and Zero-shot Learning Simultaneously in Classification
Mar 06, 2024



In recent years, few-shot and zero-shot learning, which learn to predict labels with limited annotated instances, have garnered significant attention. Traditional approaches often treat frequent-shot (freq-shot; labels with abundant instances), few-shot, and zero-shot learning as distinct challenges, optimizing systems for just one of these scenarios. Yet, in real-world settings, label occurrences vary greatly. Some of them might appear thousands of times, while others might only appear sporadically or not at all. For practical deployment, it is crucial that a system can adapt to any label occurrence. We introduce a novel classification challenge: X-shot, reflecting a real-world context where freq-shot, few-shot, and zero-shot labels co-occur without predefined limits. Here, X can span from 0 to positive infinity. The crux of X-shot centers on open-domain generalization and devising a system versatile enough to manage various label scenarios. To solve X-shot, we propose BinBin (Binary INference Based on INstruction following) that leverages the Indirect Supervision from a large collection of NLP tasks via instruction following, bolstered by Weak Supervision provided by large language models. BinBin surpasses previous state-of-the-art techniques on three benchmark datasets across multiple domains. To our knowledge, this is the first work addressing X-shot learning, where X remains variable.
OpenStance: Real-world Zero-shot Stance Detection
Oct 25, 2022Prior studies of zero-shot stance detection identify the attitude of texts towards unseen topics occurring in the same document corpus. Such task formulation has three limitations: (i) Single domain/dataset. A system is optimized on a particular dataset from a single domain; therefore, the resulting system cannot work well on other datasets; (ii) the model is evaluated on a limited number of unseen topics; (iii) it is assumed that part of the topics has rich annotations, which might be impossible in real-world applications. These drawbacks will lead to an impractical stance detection system that fails to generalize to open domains and open-form topics. This work defines OpenStance: open-domain zero-shot stance detection, aiming to handle stance detection in an open world with neither domain constraints nor topic-specific annotations. The key challenge of OpenStance lies in the open-domain generalization: learning a system with fully unspecific supervision but capable of generalizing to any dataset. To solve OpenStance, we propose to combine indirect supervision, from textual entailment datasets, and weak supervision, from data generated automatically by pre-trained Language Models. Our single system, without any topic-specific supervision, outperforms the supervised method on three popular datasets. To our knowledge, this is the first work that studies stance detection under the open-domain zero-shot setting. All data and code are publicly released.
Learning Semi-Structured Representations of Radiology Reports
Dec 20, 2021



Beyond their primary diagnostic purpose, radiology reports have been an invaluable source of information in medical research. Given a corpus of radiology reports, researchers are often interested in identifying a subset of reports describing a particular medical finding. Because the space of medical findings in radiology reports is vast and potentially unlimited, recent studies proposed mapping free-text statements in radiology reports to semi-structured strings of terms taken from a limited vocabulary. This paper aims to present an approach for the automatic generation of semi-structured representations of radiology reports. The approach consists of matching sentences from radiology reports to manually created semi-structured representations, followed by learning a sequence-to-sequence neural model that maps matched sentences to their semi-structured representations. We evaluated the proposed approach on the OpenI corpus of manually annotated chest x-ray radiology reports. The results indicate that the proposed approach is superior to several baselines, both in terms of (1) quantitative measures such as BLEU, ROUGE, and METEOR and (2) qualitative judgment of a radiologist. The results also demonstrate that the trained model produces reasonable semi-structured representations on an out-of-sample corpus of chest x-ray radiology reports from a different medical provider.
Multi-Modal Trajectory Prediction of NBA Players
Aug 18, 2020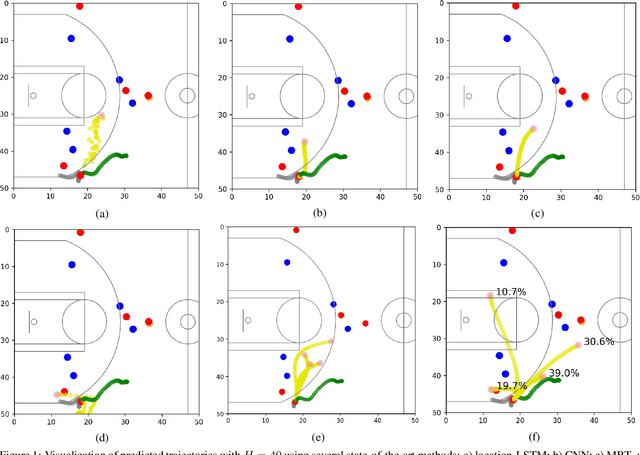
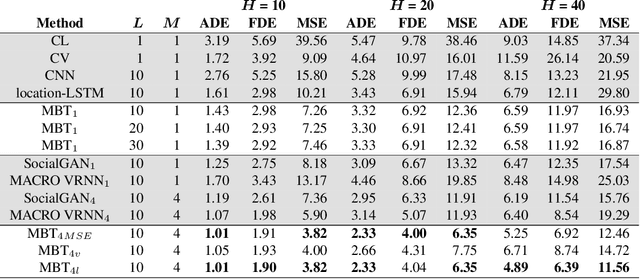
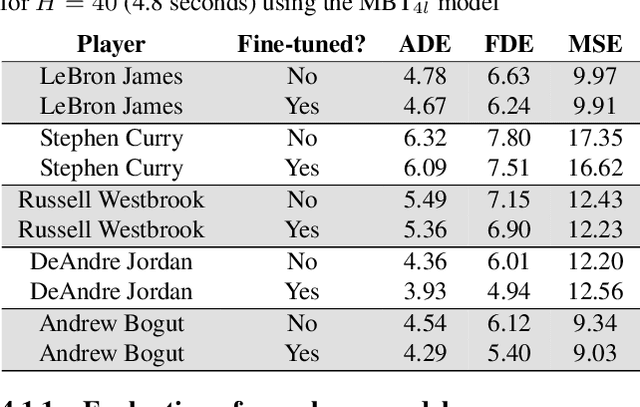
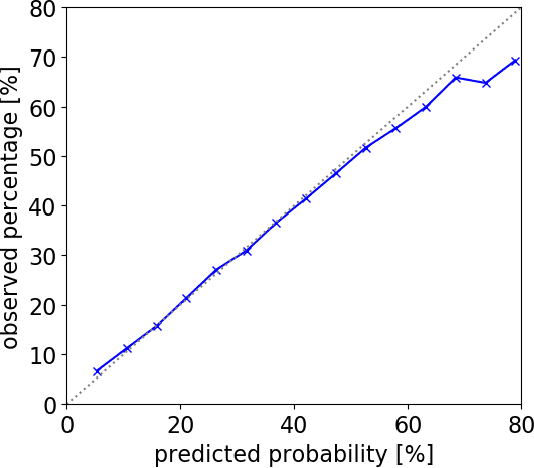
National Basketball Association (NBA) players are highly motivated and skilled experts that solve complex decision making problems at every time point during a game. As a step towards understanding how players make their decisions, we focus on their movement trajectories during games. We propose a method that captures the multi-modal behavior of players, where they might consider multiple trajectories and select the most advantageous one. The method is built on an LSTM-based architecture predicting multiple trajectories and their probabilities, trained by a multi-modal loss function that updates the best trajectories. Experiments on large, fine-grained NBA tracking data show that the proposed method outperforms the state-of-the-art. In addition, the results indicate that the approach generates more realistic trajectories and that it can learn individual playing styles of specific players.
Semi-supervised Discovery of Informative Tweets During the Emerging Disasters
Oct 12, 2016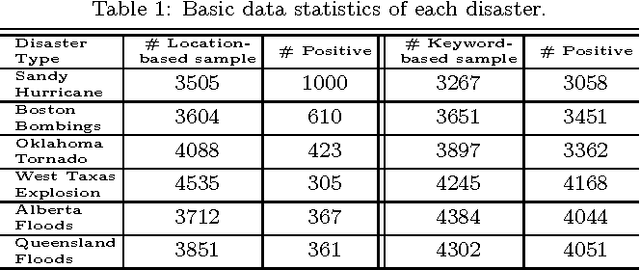
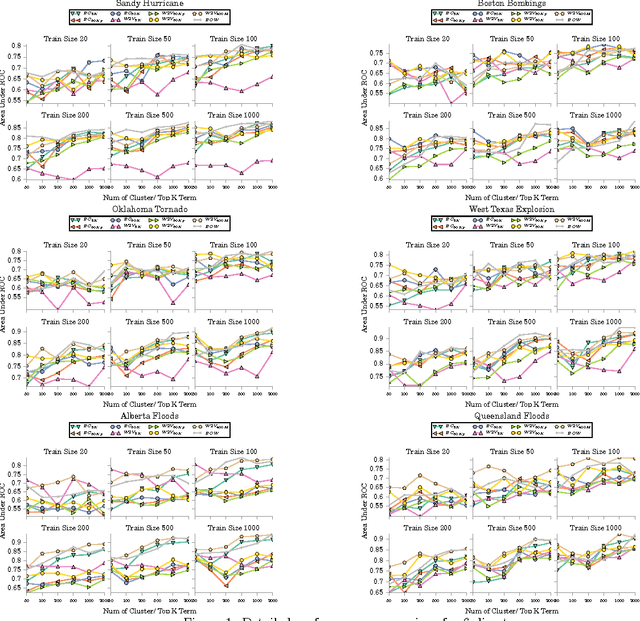
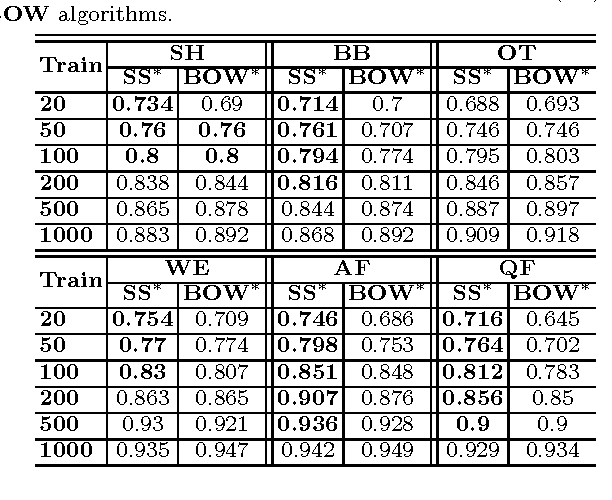
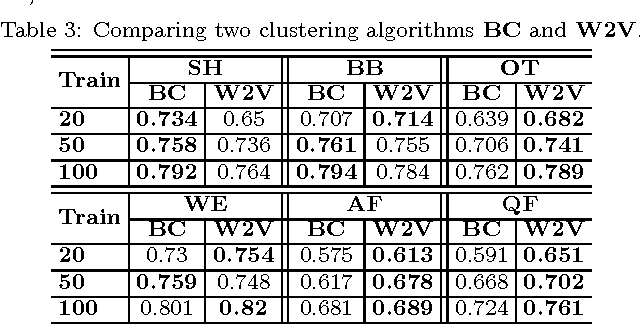
The first objective towards the effective use of microblogging services such as Twitter for situational awareness during the emerging disasters is discovery of the disaster-related postings. Given the wide range of possible disasters, using a pre-selected set of disaster-related keywords for the discovery is suboptimal. An alternative that we focus on in this work is to train a classifier using a small set of labeled postings that are becoming available as a disaster is emerging. Our hypothesis is that utilizing large quantities of historical microblogs could improve the quality of classification, as compared to training a classifier only on the labeled data. We propose to use unlabeled microblogs to cluster words into a limited number of clusters and use the word clusters as features for classification. To evaluate the proposed semi-supervised approach, we used Twitter data from 6 different disasters. Our results indicate that when the number of labeled tweets is 100 or less, the proposed approach is superior to the standard classification based on the bag or words feature representation. Our results also reveal that the choice of the unlabeled corpus, the choice of word clustering algorithm, and the choice of hyperparameters can have a significant impact on the classification accuracy.
Non-linear Label Ranking for Large-scale Prediction of Long-Term User Interests
Jun 29, 2016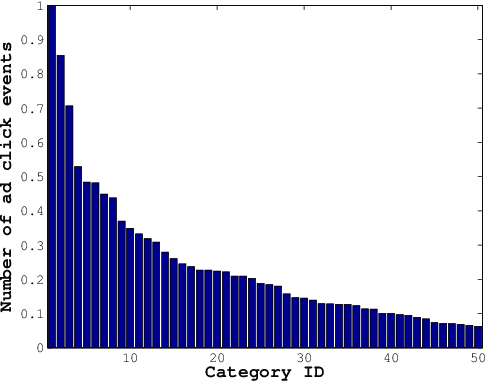
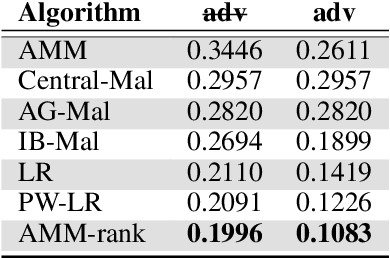

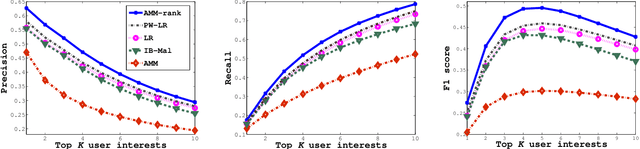
We consider the problem of personalization of online services from the viewpoint of ad targeting, where we seek to find the best ad categories to be shown to each user, resulting in improved user experience and increased advertisers' revenue. We propose to address this problem as a task of ranking the ad categories depending on a user's preference, and introduce a novel label ranking approach capable of efficiently learning non-linear, highly accurate models in large-scale settings. Experiments on a real-world advertising data set with more than 3.2 million users show that the proposed algorithm outperforms the existing solutions in terms of both rank loss and top-K retrieval performance, strongly suggesting the benefit of using the proposed model on large-scale ranking problems.