 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Active Emergency Vehicles using Per-Frame CNNs and Output Smoothing
Dec 28, 2022



While inferring common actor states (such as position or velocity) is an important and well-explored task of the perception system aboard a self-driving vehicle (SDV), it may not always provide sufficient information to the SDV. This is especially true in the case of active emergency vehicles (EVs), where light-based signals also need to be captured to provide a full context. We consider this problem and propose a sequential methodology for the detection of active EVs, using an off-the-shelf CNN model operating at a frame level and a downstream smoother that accounts for the temporal aspect of flashing EV lights. We also explore model improvements through data augmentation and training with additional hard samples.
Convolutions for Spatial Interaction Modeling
Apr 15, 2021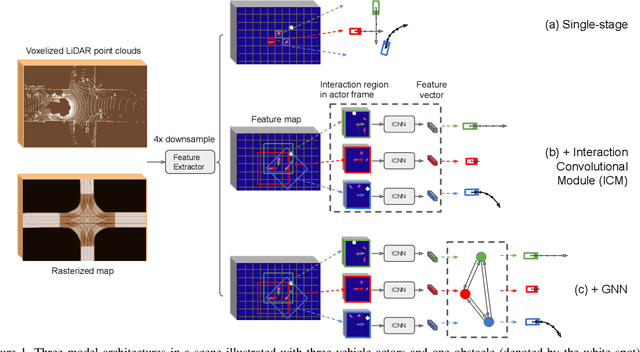

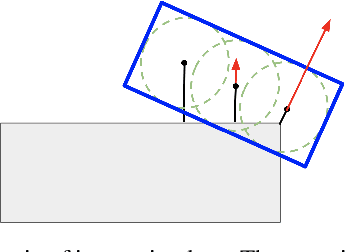
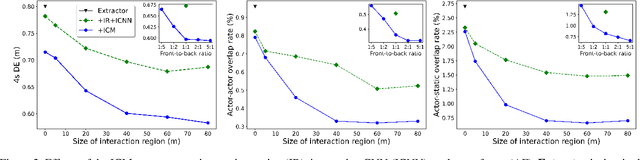
In many different fields interactions between objects play a critical role in determining their behavior. Graph neural networks (GNNs) have emerged as a powerful tool for modeling interactions, although often at the cost of adding considerable complexity and latency. In this paper, we consider the problem of spatial interaction modeling in the context of predicting the motion of actors around autonomous vehicles, and investigate alternative approaches to GNNs. We revisit convolutions and show that they can demonstrate comparable performance to graph networks in modeling spatial interactions with lower latency, thus providing an effective and efficient alternative in time-critical systems. Moreover, we propose a novel interaction loss to further improve the interaction modeling of the considered methods.
Investigating the Effect of Sensor Modalities in Multi-Sensor Detection-Prediction Models
Jan 09, 2021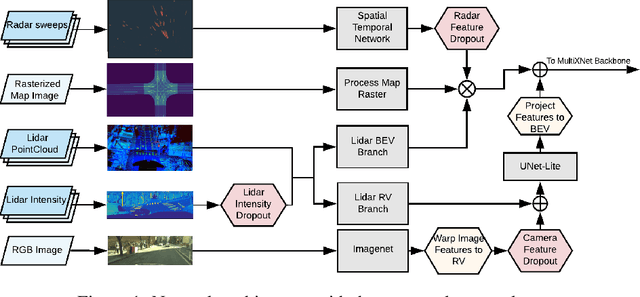
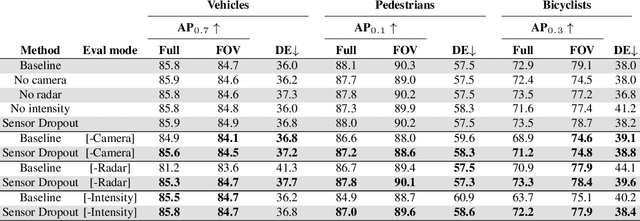
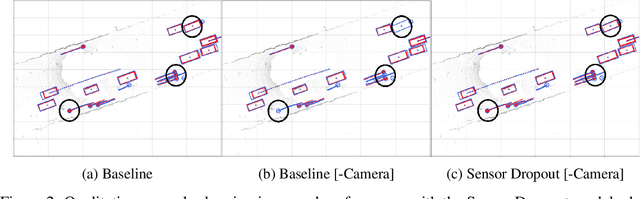
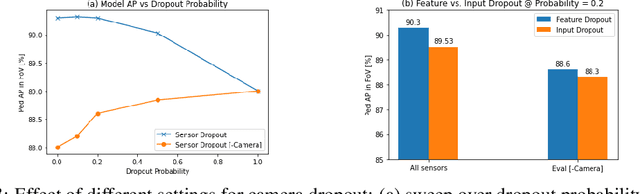
Detection of surrounding objects and their motion prediction are critical components of a self-driving system. Recently proposed models that jointly address these tasks rely on a number of sensors to achieve state-of-the-art performance. However, this increases system complexity and may result in a brittle model that overfits to any single sensor modality while ignoring others, leading to reduced generalization. We focus on this important problem and analyze the contribution of sensor modalities towards the model performance. In addition, we investigate the use of sensor dropout to mitigate the above-mentioned issues, leading to a more robust, better-performing model on real-world driving data.
Ellipse Loss for Scene-Compliant Motion Prediction
Nov 05, 2020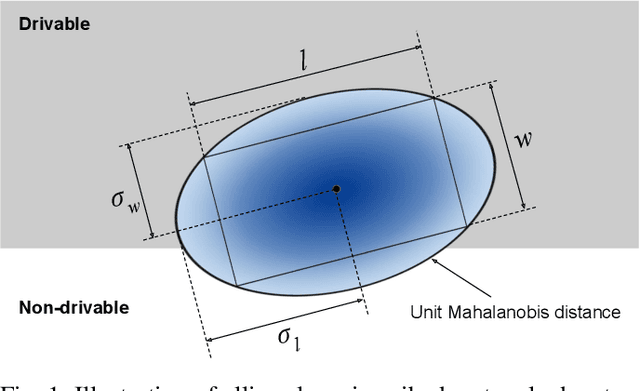
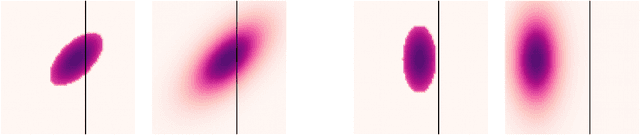

Motion prediction is a critical part of self-driving technology, responsible for inferring future behavior of traffic actors in autonomous vehicle's surroundings. In order to ensure safe and efficient operations, prediction models need to output accurate trajectories that obey the map constraints. In this paper, we address this task and propose a novel ellipse loss that allows the models to better reason about scene compliance and predict more realistic trajectories. Ellipse loss penalizes off-road predictions directly in a supervised manner, by projecting the output trajectories into the top-down map frame using a differentiable trajectory rasterizer module. Moreover, it takes into account the actor dimension and orientation, providing more direct training signals to the model. We applied ellipse loss to a recently proposed state-of-the-art joint detection-prediction model to showcase its benefits. Evaluation results on a large-scale autonomous driving data set strongly indicate that our method allows for more accurate and more realistic trajectory predictions.
Uncertainty-Aware Vehicle Orientation Estimation for Joint Detection-Prediction Models
Nov 05, 2020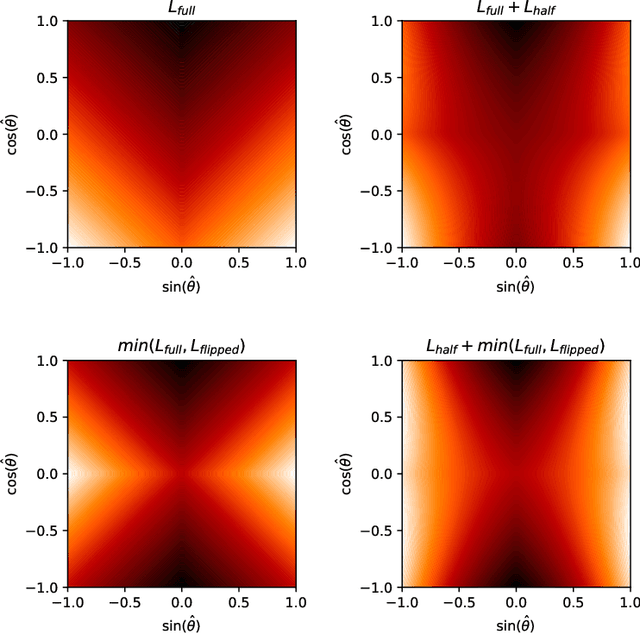
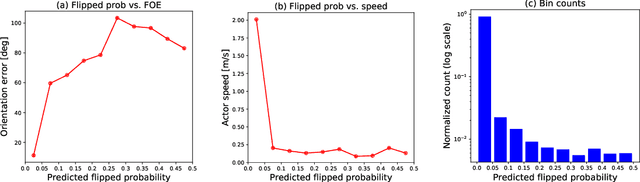


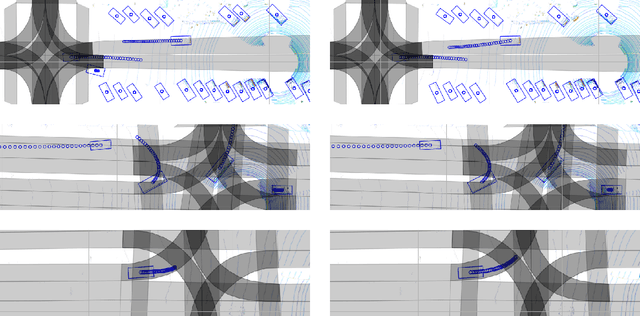
Object detection is a critical component of a self-driving system, tasked with inferring the current states of the surrounding traffic actors. While there exist a number of studies on the problem of inferring the position and shape of vehicle actors, understanding actors' orientation remains a challenge for existing state-of-the-art detectors. Orientation is an important property for downstream modules of an autonomous system, particularly relevant for motion prediction of stationary or reversing actors where current approaches struggle. We focus on this task and present a method that extends the existing models that perform joint object detection and motion prediction, allowing us to more accurately infer vehicle orientations. In addition, the approach is able to quantify prediction uncertainty, outputting the probability that the inferred orientation is flipped, which allows for improved motion prediction and safer autonomous operations. Empirical results show the benefits of the approach, obtaining state-of-the-art performance on the open-sourced nuScenes data set.
Temporally-Continuous Probabilistic Prediction using Polynomial Trajectory Parameterization
Nov 01, 2020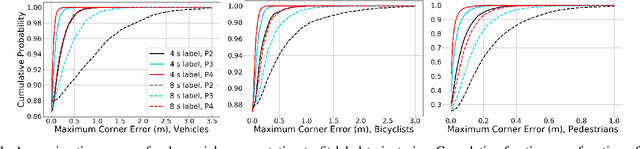
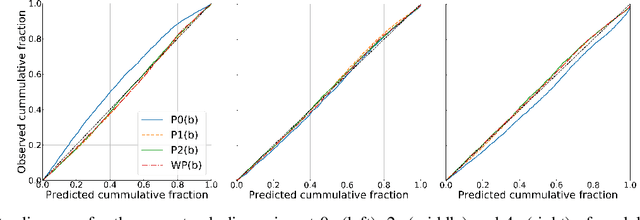
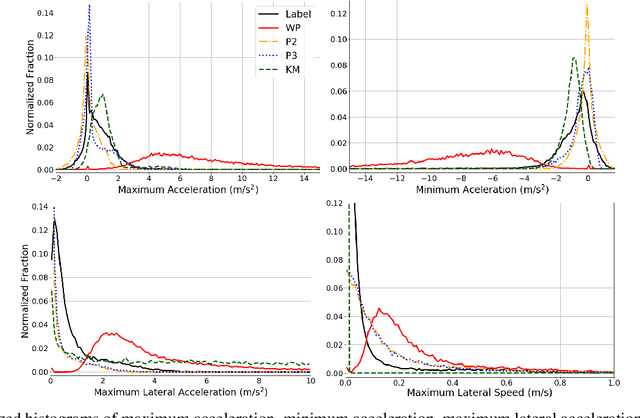
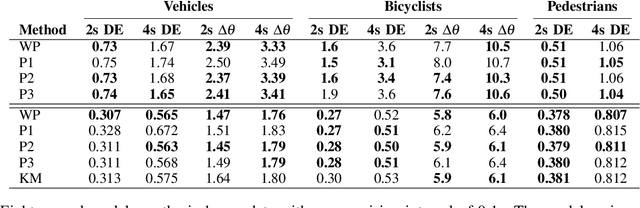
A commonly-used representation for motion prediction of actors is a sequence of waypoints (comprising positions and orientations) for each actor at discrete future time-points. While this approach is simple and flexible, it can exhibit unrealistic higher-order derivatives (such as acceleration) and approximation errors at intermediate time steps. To address this issue we propose a simple and general representation for temporally continuous probabilistic trajectory prediction that is based on polynomial trajectory parameterization. We evaluate the proposed representation on supervised trajectory prediction tasks using two large self-driving data sets. The results show realistic higher-order derivatives and better accuracy at interpolated time-points, as well as the benefits of the inferred noise distributions over the trajectories. Extensive experimental studies based on existing state-of-the-art models demonstrate the effectiveness of the proposed approach relative to other representations in predicting the future motions of vehicle, bicyclist, and pedestrian traffic actors.
Multi-View Fusion of Sensor Data for Improved Perception and Prediction in Autonomous Driving
Aug 27, 2020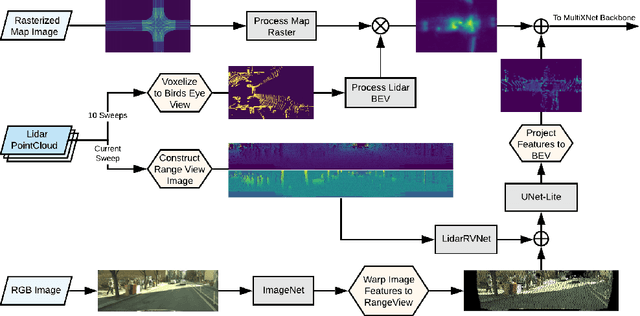
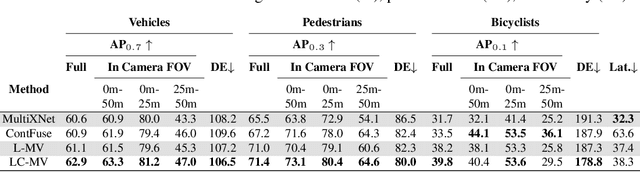
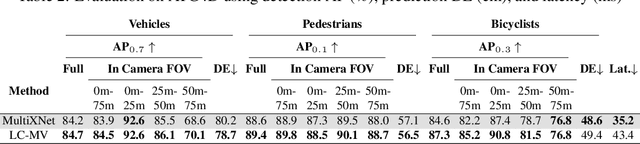
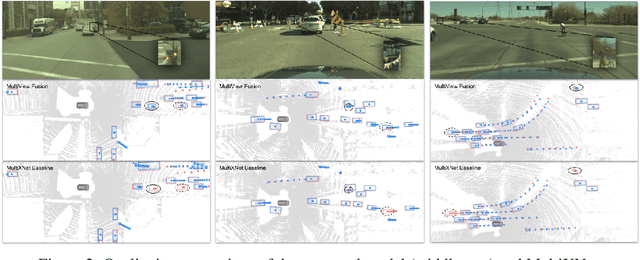
We present an end-to-end method for object detection and trajectory prediction utilizing multi-view representations of LiDAR returns. Our method builds on a state-of-the-art Bird's-Eye View (BEV) network that fuses voxelized features from a sequence of historical LiDAR data as well as rasterized high-definition map to perform detection and prediction tasks. We extend the BEV network with additional LiDAR Range-View (RV) features that use the raw LiDAR information in its native, non-quantized representation. The RV feature map is projected into BEV and fused with the BEV features computed from LiDAR and high-definition map. The fused features are then further processed to output the final detections and trajectories, within a single end-to-end trainable network. In addition, using this framework the RV fusion of LiDAR and camera is performed in a straightforward and computational efficient manner. The proposed approach improves the state-of-the-art on proprietary large-scale real-world data collected by a fleet of self-driving vehicles, as well as on the public nuScenes data set.
Multi-Modal Trajectory Prediction of NBA Players
Aug 18, 2020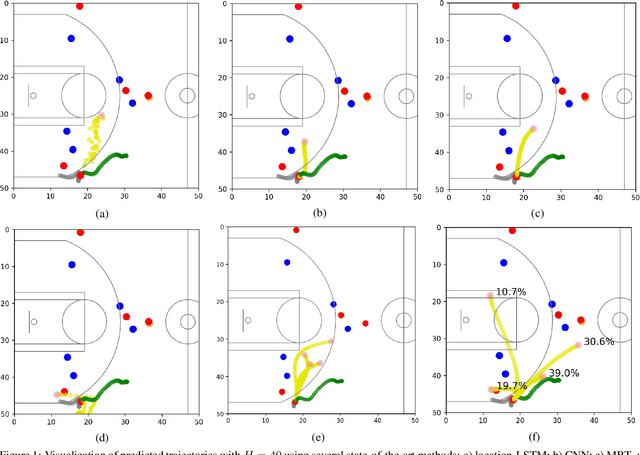
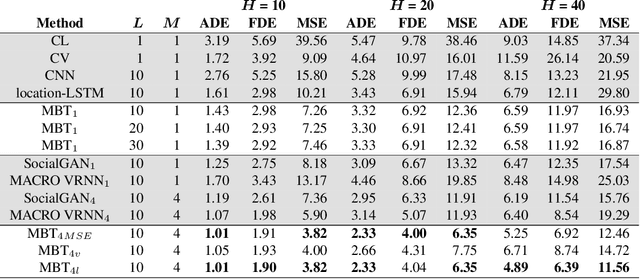
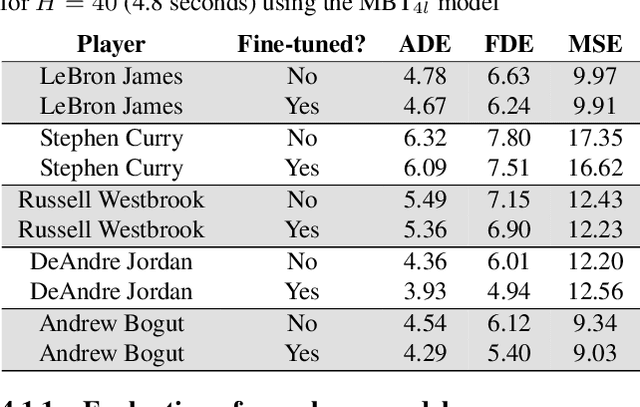
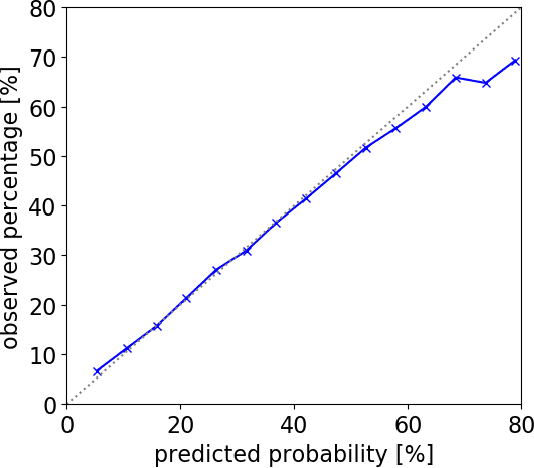
National Basketball Association (NBA) players are highly motivated and skilled experts that solve complex decision making problems at every time point during a game. As a step towards understanding how players make their decisions, we focus on their movement trajectories during games. We propose a method that captures the multi-modal behavior of players, where they might consider multiple trajectories and select the most advantageous one. The method is built on an LSTM-based architecture predicting multiple trajectories and their probabilities, trained by a multi-modal loss function that updates the best trajectories. Experiments on large, fine-grained NBA tracking data show that the proposed method outperforms the state-of-the-art. In addition, the results indicate that the approach generates more realistic trajectories and that it can learn individual playing styles of specific players.
MultiXNet: Multiclass Multistage Multimodal Motion Prediction
Jun 10, 2020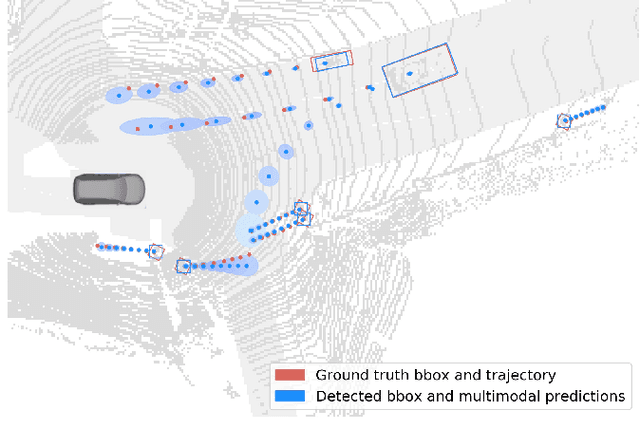
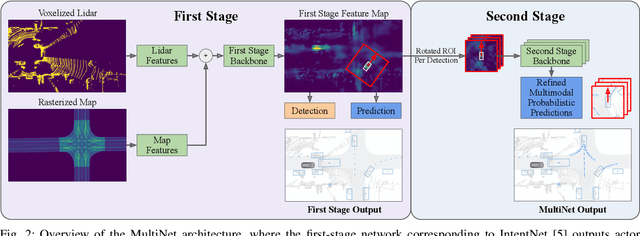
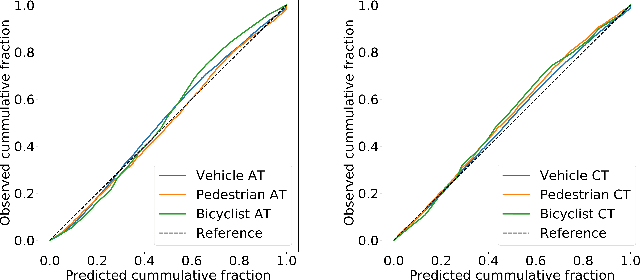
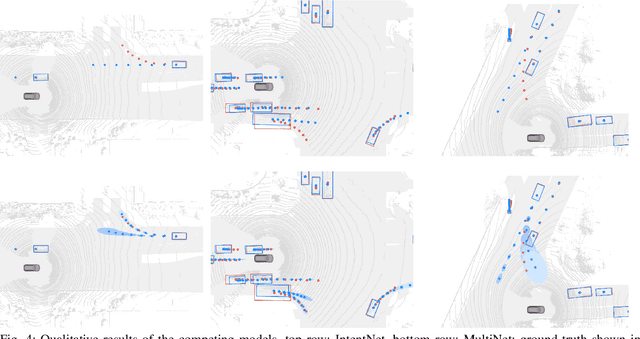
One of the critical pieces of the self-driving puzzle is understanding the surroundings of the self-driving vehicle (SDV) and predicting how these surroundings will change in the near future. To address this task we propose MultiXNet, an end-to-end approach for detection and motion prediction based directly on lidar sensor data. This approach builds on prior work by handling multiple classes of traffic actors, adding a jointly trained second-stage trajectory refinement step, and producing a multimodal probability distribution over future actor motion that includes both multiple discrete traffic behaviors and calibrated continuous uncertainties. The method was evaluated on a large-scale, real-world data set collected by a fleet of SDVs in several cities, with the results indicating that it outperforms existing state-of-the-art approaches.
Improving Movement Predictions of Traffic Actors in Bird's-Eye View Models using GANs and Differentiable Trajectory Rasterization
Apr 14, 2020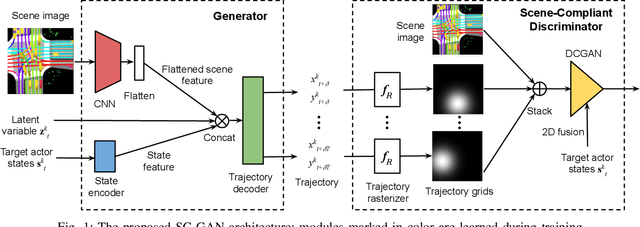

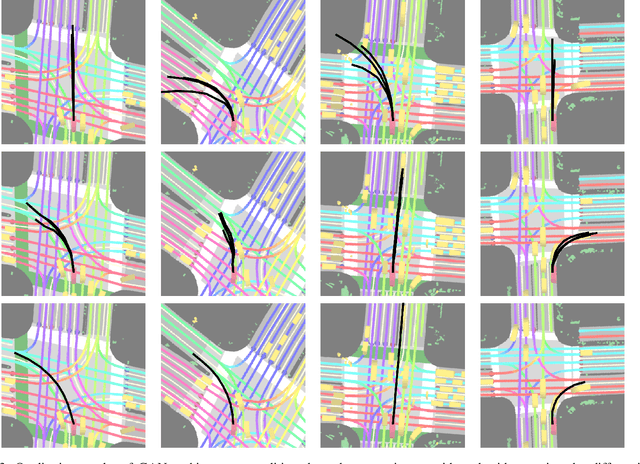
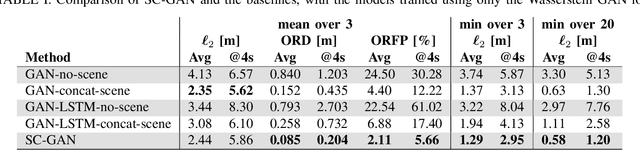
One of the most critical pieces of the self-driving puzzle is the task of predicting future movement of surrounding traffic actors, which allows the autonomous vehicle to safely and effectively plan its future route in a complex world. Recently, a number of algorithms have been proposed to address this important problem, spurred by a growing interest of researchers from both industry and academia. Methods based on top-down scene rasterization on one side and Generative Adversarial Networks (GANs) on the other have shown to be particularly successful, obtaining state-of-the-art accuracies on the task of traffic movement prediction. In this paper we build upon these two directions and propose a raster-based conditional GAN architecture, powered by a novel differentiable rasterizer module at the input of the conditional discriminator that maps generated trajectories into the raster space in a differentiable manner. This simplifies the task for the discriminator as trajectories that are not scene-compliant are easier to discern, and allows the gradients to flow back forcing the generator to output better, more realistic trajectories. We evaluated the proposed method on a large-scale, real-world data set, showing that it outperforms state-of-the-art GAN-based baselines.