 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Vehicle Orientation Estimation for Joint Detection-Prediction Models
Nov 05, 2020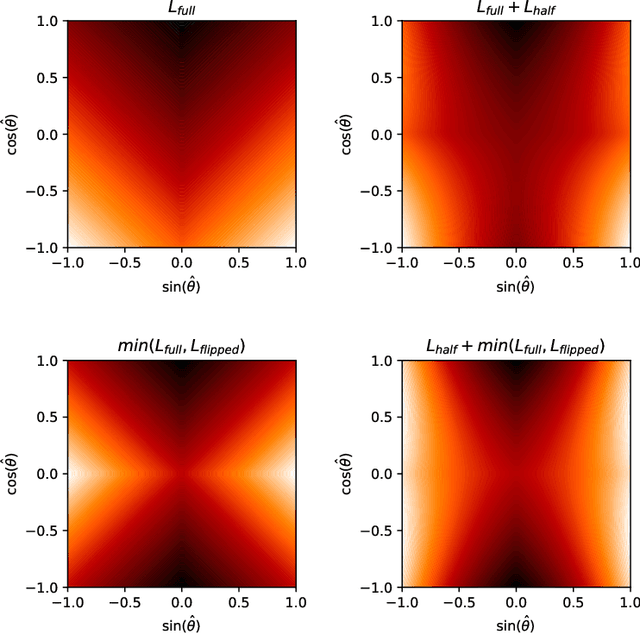
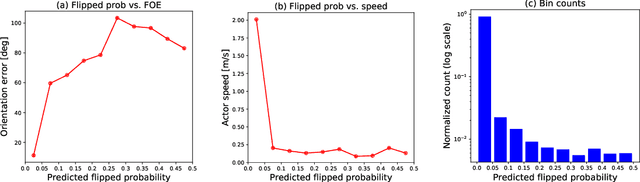


Object detection is a critical component of a self-driving system, tasked with inferring the current states of the surrounding traffic actors. While there exist a number of studies on the problem of inferring the position and shape of vehicle actors, understanding actors' orientation remains a challenge for existing state-of-the-art detectors. Orientation is an important property for downstream modules of an autonomous system, particularly relevant for motion prediction of stationary or reversing actors where current approaches struggle. We focus on this task and present a method that extends the existing models that perform joint object detection and motion prediction, allowing us to more accurately infer vehicle orientations. In addition, the approach is able to quantify prediction uncertainty, outputting the probability that the inferred orientation is flipped, which allows for improved motion prediction and safer autonomous operations. Empirical results show the benefits of the approach, obtaining state-of-the-art performance on the open-sourced nuScenes data set.
LaserFlow: Efficient and Probabilistic Object Detection and Motion Forecasting
Apr 21, 2020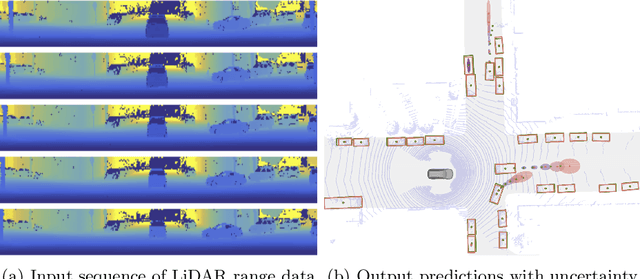
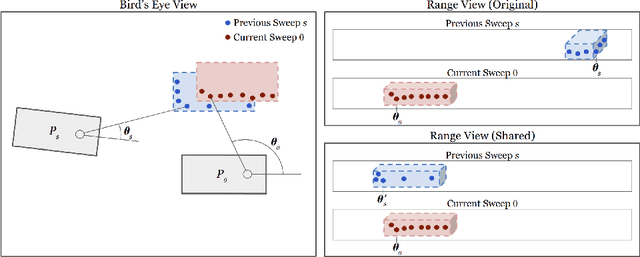
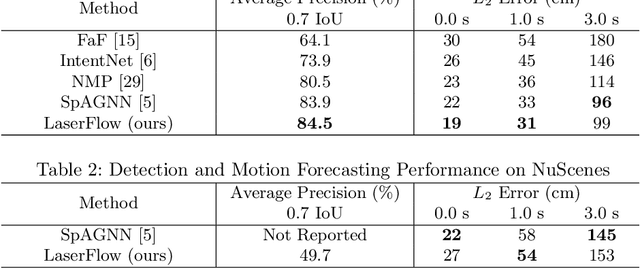
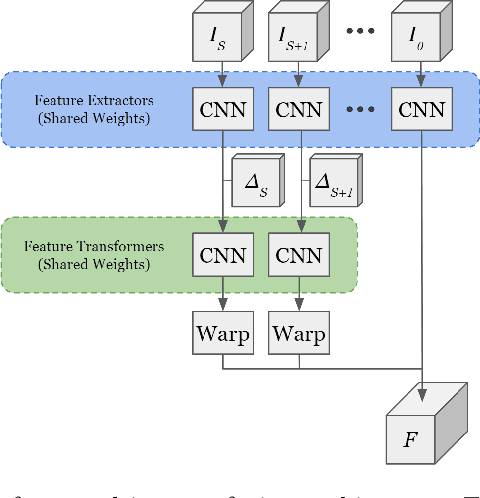
In this work, we present LaserFlow, an efficient method for 3D object detection and motion forecasting from LiDAR. Unlike the previous work, our approach utilizes the native range view representation of the LiDAR, which enables our method to operate at the full range of the sensor in real-time without voxelization or compression of the data. We propose a new multi-sweep fusion architecture, which extracts and merges temporal features directly from the range images. Furthermore, we propose a novel technique for learning a probability distribution over future trajectories inspired by curriculum learning. We evaluate LaserFlow on two autonomous driving datasets and demonstrate competitive results when compared to the existing state-of-the-art methods.
Sensor Fusion for Joint 3D Object Detection and Semantic Segmentation
Apr 25, 2019

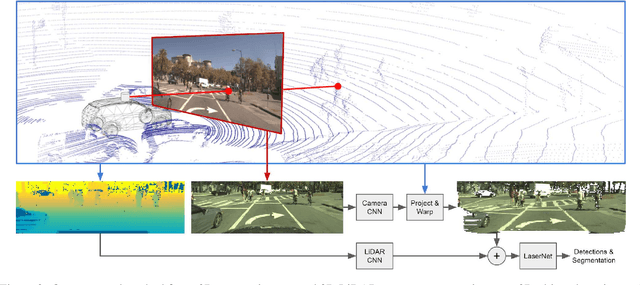
In this paper, we present an extension to LaserNet, an efficient and state-of-the-art LiDAR based 3D object detector. We propose a method for fusing image data with the LiDAR data and show that this sensor fusion method improves the detection performance of the model especially at long ranges. The addition of image data is straightforward and does not require image labels. Furthermore, we expand the capabilities of the model to perform 3D semantic segmentation in addition to 3D object detection. On a large benchmark dataset, we demonstrate our approach achieves state-of-the-art performance on both object detection and semantic segmentation while maintaining a low runtime.