 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVFuseNet: Improving End-to-End Object Detection and Motion Forecasting through Multi-View Fusion of LiDAR Data
Apr 21, 2021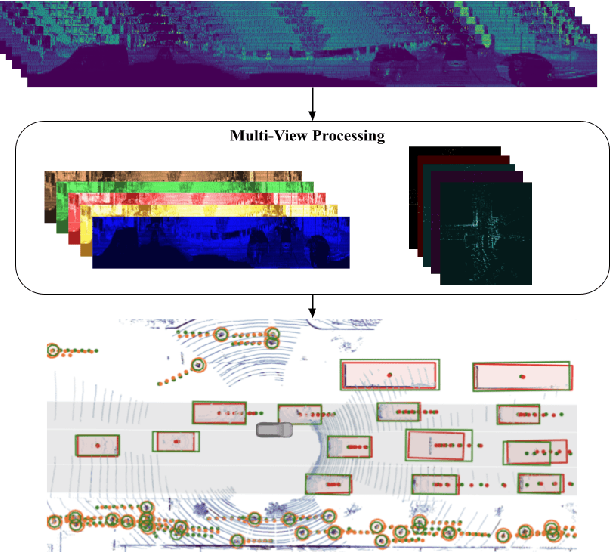
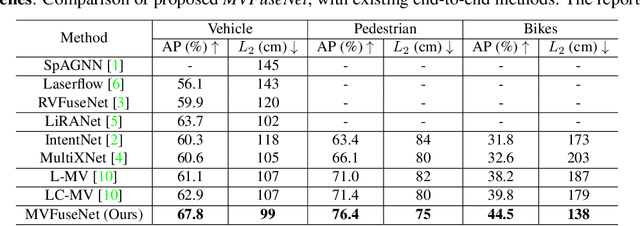
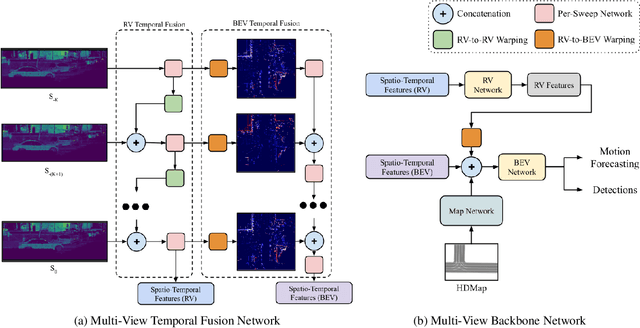
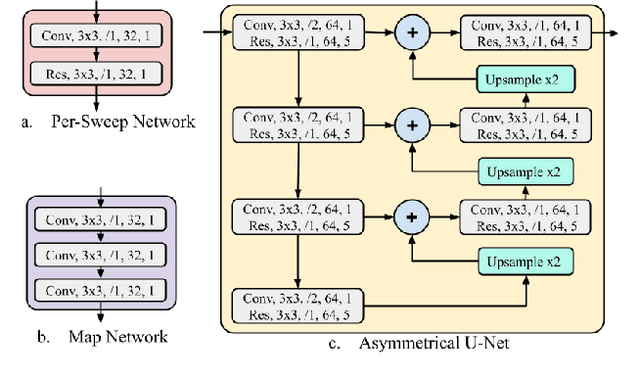
In this work, we propose \textit{MVFuseNet}, a novel end-to-end method for joint object detection and motion forecasting from a temporal sequence of LiDAR data. Most existing methods operate in a single view by projecting data in either range view (RV) or bird's eye view (BEV). In contrast, we propose a method that effectively utilizes both RV and BEV for spatio-temporal feature learning as part of a temporal fusion network as well as for multi-scale feature learning in the backbone network. Further, we propose a novel sequential fusion approach that effectively utilizes multiple views in the temporal fusion network. We show the benefits of our multi-view approach for the tasks of detection and motion forecasting on two large-scale self-driving data sets, achieving state-of-the-art results. Furthermore, we show that MVFusenet scales well to large operating ranges while maintaining real-time performance.
LiRaNet: End-to-End Trajectory Prediction using Spatio-Temporal Radar Fusion
Oct 15, 2020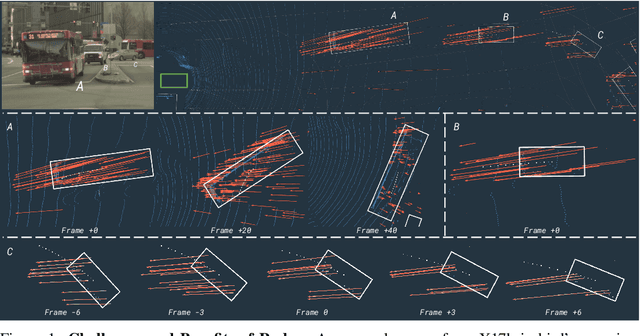
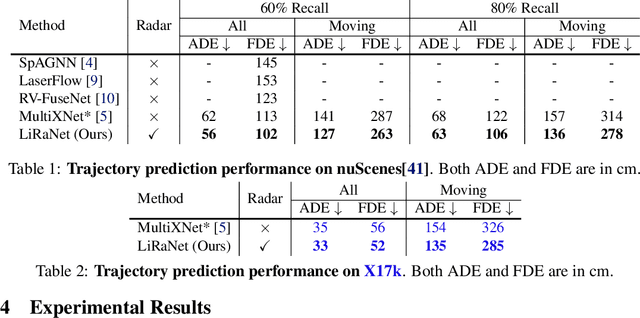
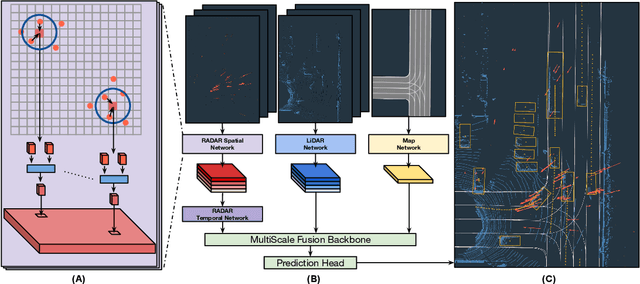

In this paper, we present LiRaNet, a novel end-to-end trajectory prediction method which utilizes radar sensor information along with widely used lidar and high definition (HD) maps. Automotive radar provides rich, complementary information, allowing for longer range vehicle detection as well as instantaneous radial velocity measurements. However, there are factors that make the fusion of lidar and radar information challenging, such as the relatively low angular resolution of radar measurements, their sparsity and the lack of exact time synchronization with lidar. To overcome these challenges, we propose an efficient spatio-temporal radar feature extraction scheme which achieves state-of-the-art performance on multiple large-scale datasets.Further, by incorporating radar information, we show a 52% reduction in prediction error for objects with high acceleration and a 16% reduction in prediction error for objects at longer range.
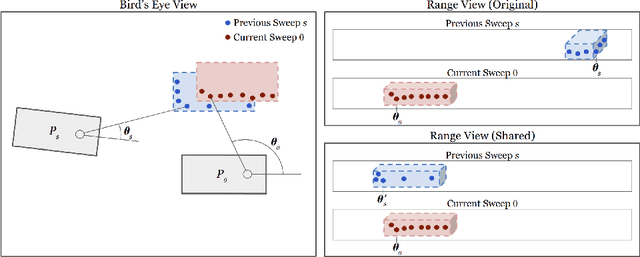
RV-FuseNet: Range View based Fusion of Time-Series LiDAR Data for Joint 3D Object Detection and Motion Forecasting
May 21, 2020
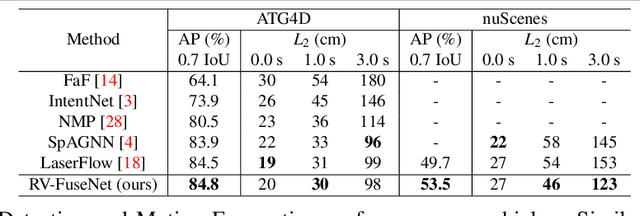
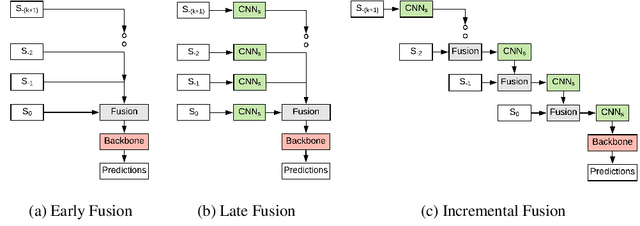

Autonomous vehicles rely on robust real-time detection and future motion prediction of traffic participants to safely navigate urban environments. We present a novel end-to-end approach that uses raw time-series LiDAR data to jointly solve both detection and prediction. We use the range view representation of LiDAR instead of voxelization since it does not discard information and is more efficient due to its compactness. However, for time-series fusion the data needs to be projected to a common viewpoint, and often this viewpoint is different from where it was captured leading to distortions. These distortions have an adverse impact on performance. Thus, we propose a novel architecture which reduces the impact of distortions by sequentially projecting each sweep into the viewpoint of the next sweep in time. We demonstrate that our sequential fusion approach is superior to methods that directly project all the data into the most recent viewpoint. Furthermore, we compare our approach to existing state-of-the art methods on multiple autonomous driving datasets and show competitive results.
LaserFlow: Efficient and Probabilistic Object Detection and Motion Forecasting
Apr 21, 2020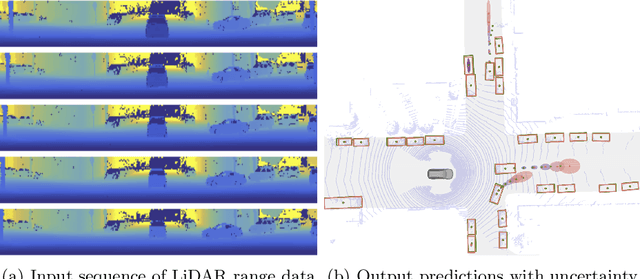
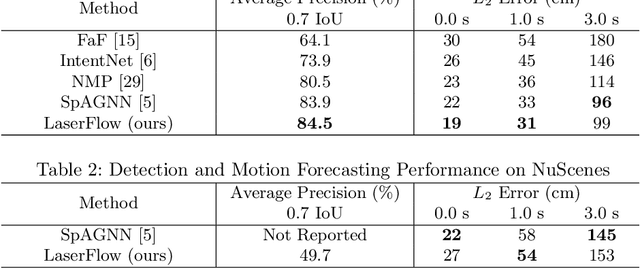
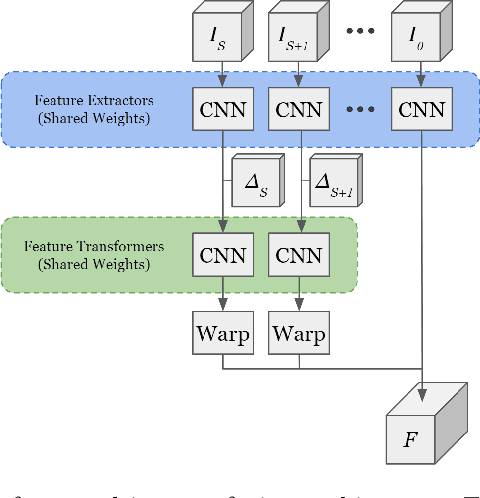
In this work, we present LaserFlow, an efficient method for 3D object detection and motion forecasting from LiDAR. Unlike the previous work, our approach utilizes the native range view representation of the LiDAR, which enables our method to operate at the full range of the sensor in real-time without voxelization or compression of the data. We propose a new multi-sweep fusion architecture, which extracts and merges temporal features directly from the range images. Furthermore, we propose a novel technique for learning a probability distribution over future trajectories inspired by curriculum learning. We evaluate LaserFlow on two autonomous driving datasets and demonstrate competitive results when compared to the existing state-of-the-art methods.
Sensor Fusion for Joint 3D Object Detection and Semantic Segmentation
Apr 25, 2019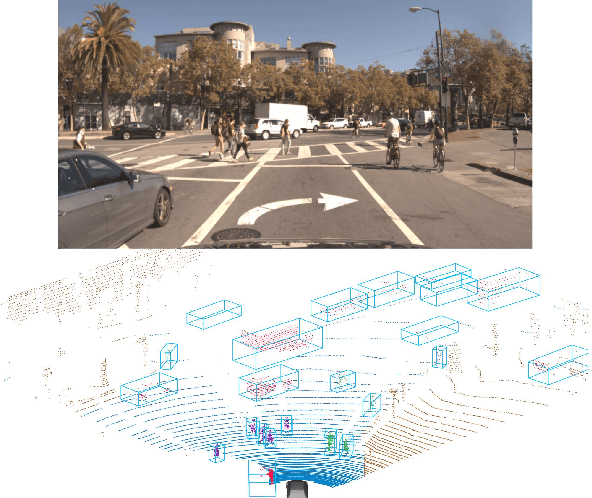

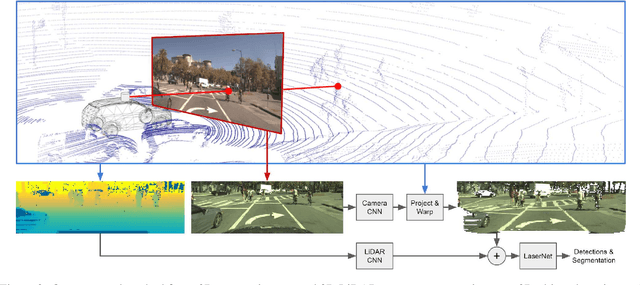
In this paper, we present an extension to LaserNet, an efficient and state-of-the-art LiDAR based 3D object detector. We propose a method for fusing image data with the LiDAR data and show that this sensor fusion method improves the detection performance of the model especially at long ranges. The addition of image data is straightforward and does not require image labels. Furthermore, we expand the capabilities of the model to perform 3D semantic segmentation in addition to 3D object detection. On a large benchmark dataset, we demonstrate our approach achieves state-of-the-art performance on both object detection and semantic segmentation while maintaining a low runtime.
LaserNet: An Efficient Probabilistic 3D Object Detector for Autonomous Driving
Mar 20, 2019

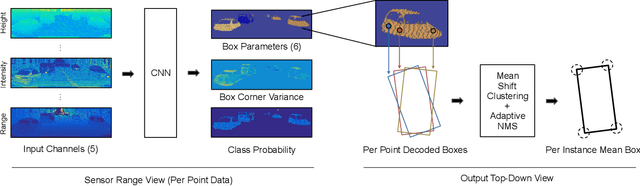
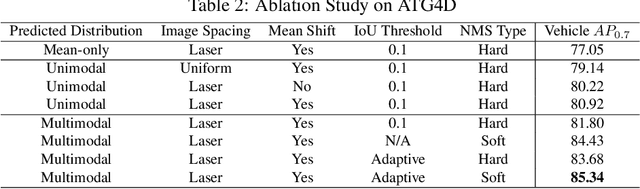
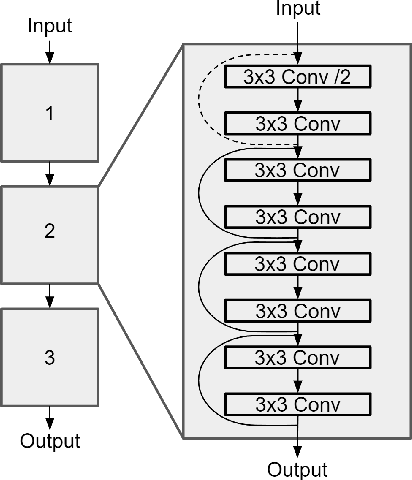
In this paper, we present LaserNet, a computationally efficient method for 3D object detection from LiDAR data for autonomous driving. The efficiency results from processing LiDAR data in the native range view of the sensor, where the input data is naturally compact. Operating in the range view involves well known challenges for learning, including occlusion and scale variation, but it also provides contextual information based on how the sensor data was captured. Our approach uses a fully convolutional network to predict a multimodal distribution over 3D boxes for each point and then it efficiently fuses these distributions to generate a prediction for each object. Experiments show that modeling each detection as a distribution rather than a single deterministic box leads to better overall detection performance. Benchmark results show that this approach has significantly lower runtime than other recent detectors and that it achieves state-of-the-art performance when compared on a large dataset that has enough data to overcome the challenges of training on the range view.
Resolving Language and Vision Ambiguities Together: Joint Segmentation & Prepositional Attachment Resolution in Captioned Scenes
Sep 26, 2016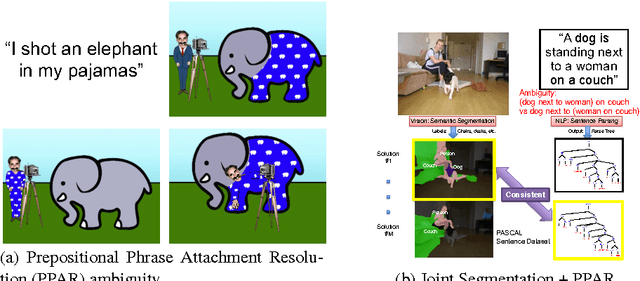
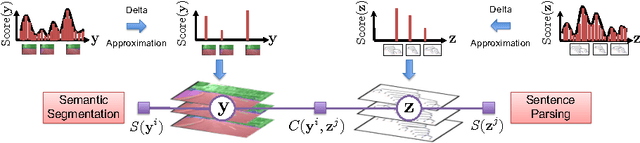
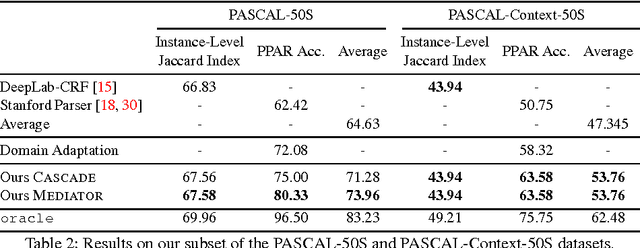
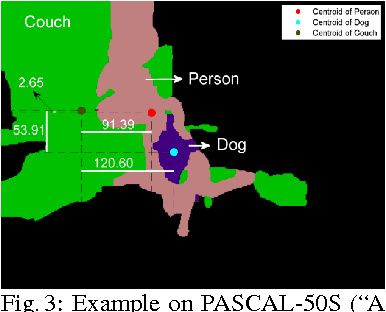
We present an approach to simultaneously perform semantic segmentation and prepositional phrase attachment resolution for captioned images. Some ambiguities in language cannot be resolved without simultaneously reasoning about an associated image. If we consider the sentence "I shot an elephant in my pajamas", looking at language alone (and not using common sense), it is unclear if it is the person or the elephant wearing the pajamas or both. Our approach produces a diverse set of plausible hypotheses for both semantic segmentation and prepositional phrase attachment resolution that are then jointly reranked to select the most consistent pair. We show that our semantic segmentation and prepositional phrase attachment resolution modules have complementary strengths, and that joint reasoning produces more accurate results than any module operating in isolation. Multiple hypotheses are also shown to be crucial to improved multiple-module reasoning. Our vision and language approach significantly outperforms the Stanford Parser (De Marneffe et al., 2006) by 17.91% (28.69% relative) and 12.83% (25.28% relative) in two different experiments. We also make small improvements over DeepLab-CRF (Chen et al., 2015).