 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVFuseNet: Improving End-to-End Object Detection and Motion Forecasting through Multi-View Fusion of LiDAR Data
Paper and Code
Apr 21, 2021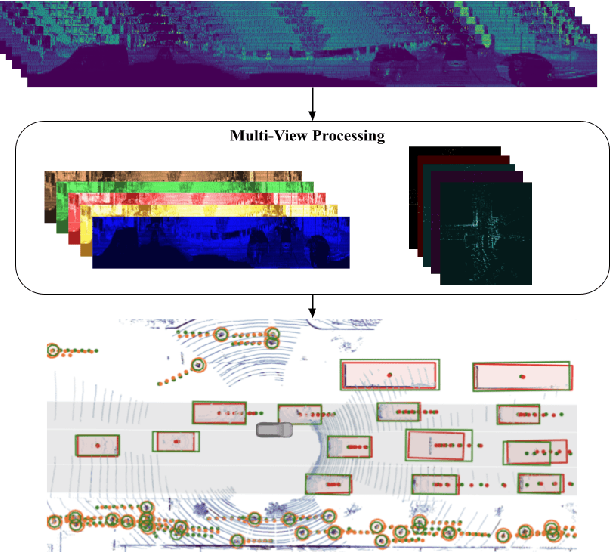
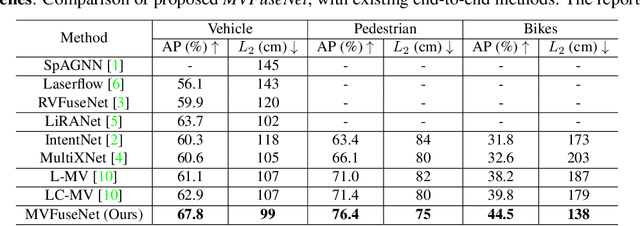
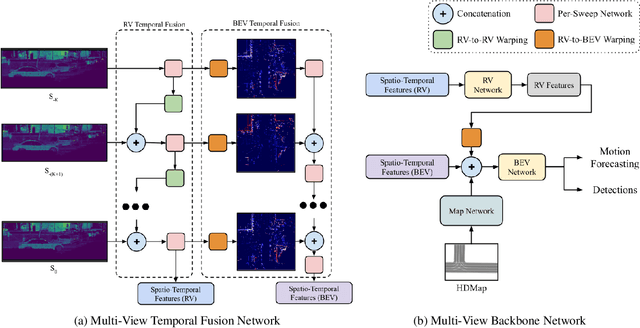
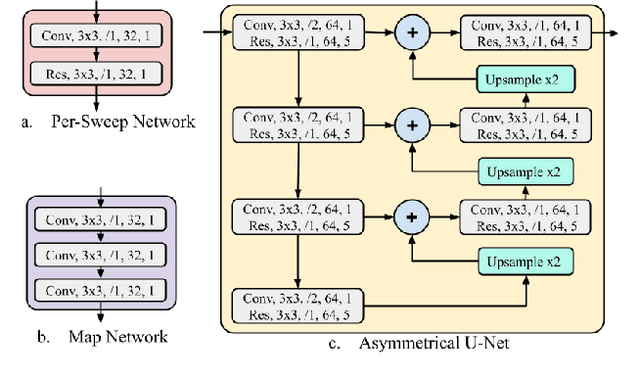
In this work, we propose \textit{MVFuseNet}, a novel end-to-end method for joint object detection and motion forecasting from a temporal sequence of LiDAR data. Most existing methods operate in a single view by projecting data in either range view (RV) or bird's eye view (BEV). In contrast, we propose a method that effectively utilizes both RV and BEV for spatio-temporal feature learning as part of a temporal fusion network as well as for multi-scale feature learning in the backbone network. Further, we propose a novel sequential fusion approach that effectively utilizes multiple views in the temporal fusion network. We show the benefits of our multi-view approach for the tasks of detection and motion forecasting on two large-scale self-driving data sets, achieving state-of-the-art results. Furthermore, we show that MVFusenet scales well to large operating ranges while maintaining real-time performance.