 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVFuseNet: Improving End-to-End Object Detection and Motion Forecasting through Multi-View Fusion of LiDAR Data
Apr 21, 2021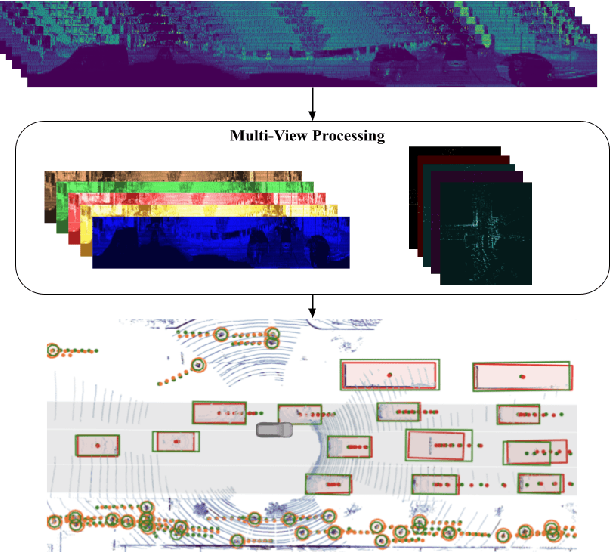
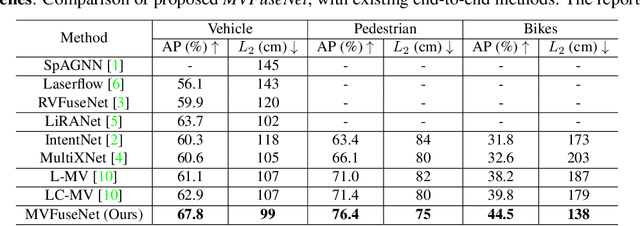
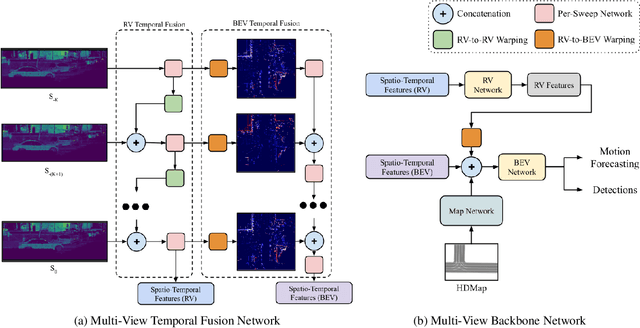
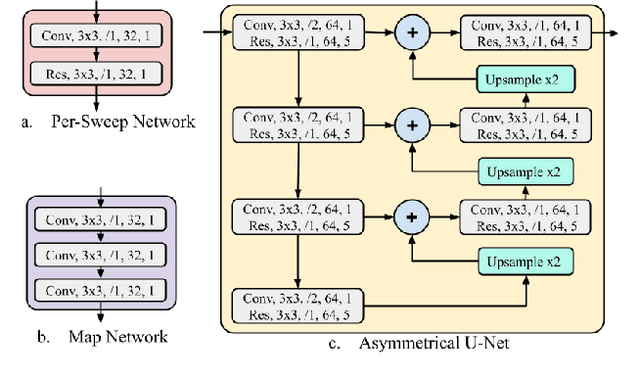
In this work, we propose \textit{MVFuseNet}, a novel end-to-end method for joint object detection and motion forecasting from a temporal sequence of LiDAR data. Most existing methods operate in a single view by projecting data in either range view (RV) or bird's eye view (BEV). In contrast, we propose a method that effectively utilizes both RV and BEV for spatio-temporal feature learning as part of a temporal fusion network as well as for multi-scale feature learning in the backbone network. Further, we propose a novel sequential fusion approach that effectively utilizes multiple views in the temporal fusion network. We show the benefits of our multi-view approach for the tasks of detection and motion forecasting on two large-scale self-driving data sets, achieving state-of-the-art results. Furthermore, we show that MVFusenet scales well to large operating ranges while maintaining real-time performance.
RV-FuseNet: Range View based Fusion of Time-Series LiDAR Data for Joint 3D Object Detection and Motion Forecasting
May 21, 2020
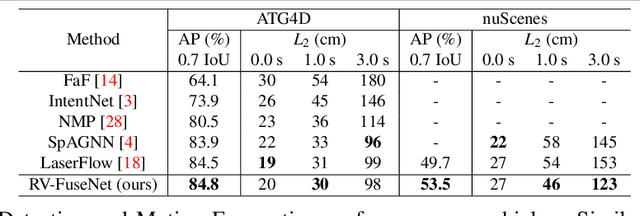
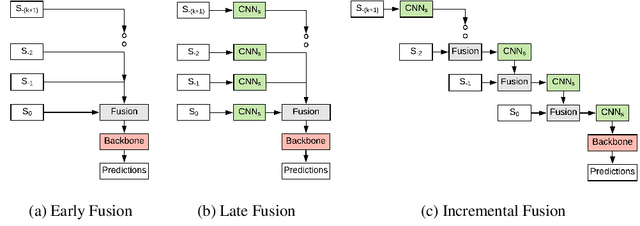

Autonomous vehicles rely on robust real-time detection and future motion prediction of traffic participants to safely navigate urban environments. We present a novel end-to-end approach that uses raw time-series LiDAR data to jointly solve both detection and prediction. We use the range view representation of LiDAR instead of voxelization since it does not discard information and is more efficient due to its compactness. However, for time-series fusion the data needs to be projected to a common viewpoint, and often this viewpoint is different from where it was captured leading to distortions. These distortions have an adverse impact on performance. Thus, we propose a novel architecture which reduces the impact of distortions by sequentially projecting each sweep into the viewpoint of the next sweep in time. We demonstrate that our sequential fusion approach is superior to methods that directly project all the data into the most recent viewpoint. Furthermore, we compare our approach to existing state-of-the art methods on multiple autonomous driving datasets and show competitive results.
SDVTracker: Real-Time Multi-Sensor Association and Tracking for Self-Driving Vehicles
Mar 09, 2020
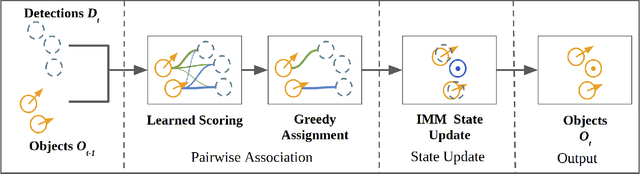
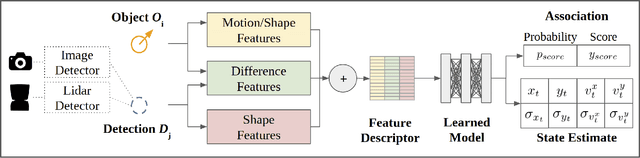
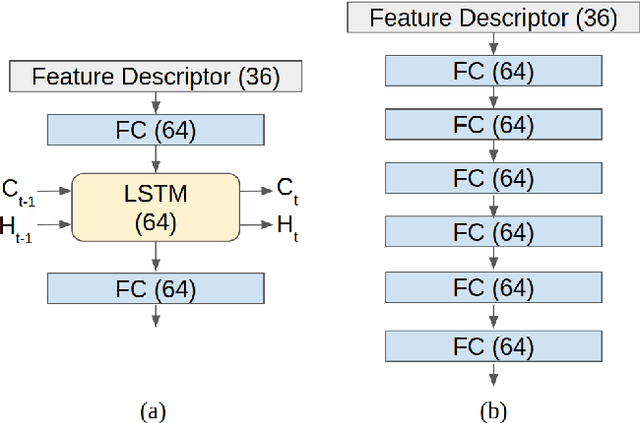
Accurate motion state estimation of Vulnerable Road Users (VRUs), is a critical requirement for autonomous vehicles that navigate in urban environments. Due to their computational efficiency, many traditional autonomy systems perform multi-object tracking using Kalman Filters which frequently rely on hand-engineered association. However, such methods fail to generalize to crowded scenes and multi-sensor modalities, often resulting in poor state estimates which cascade to inaccurate predictions. We present a practical and lightweight tracking system, SDVTracker, that uses a deep learned model for association and state estimation in conjunction with an Interacting Multiple Model (IMM) filter. The proposed tracking method is fast, robust and generalizes across multiple sensor modalities and different VRU classes. In this paper, we detail a model that jointly optimizes both association and state estimation with a novel loss, an algorithm for determining ground-truth supervision, and a training procedure. We show this system significantly outperforms hand-engineered methods on a real-world urban driving dataset while running in less than 2.5 ms on CPU for a scene with 100 actors, making it suitable for self-driving applications where low latency and high accuracy is critical.