 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVFuseNet: Improving End-to-End Object Detection and Motion Forecasting through Multi-View Fusion of LiDAR Data
Apr 21, 2021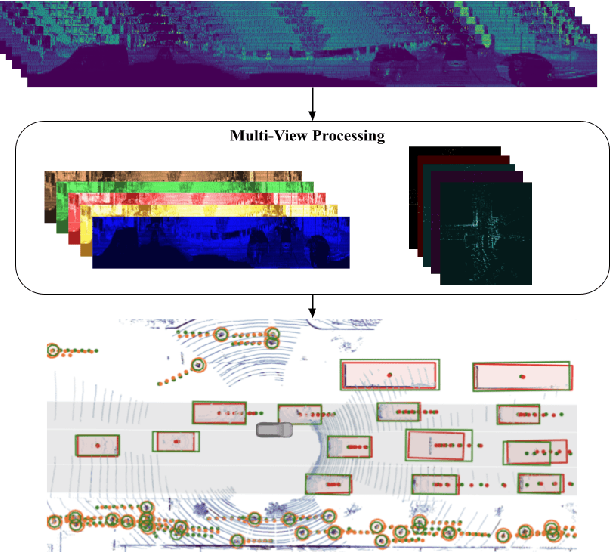
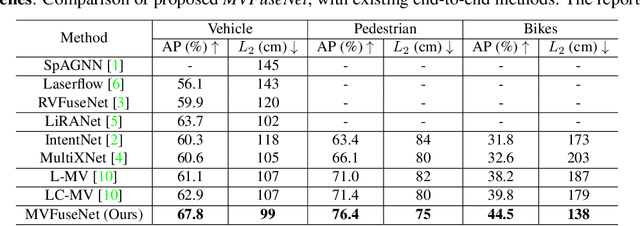
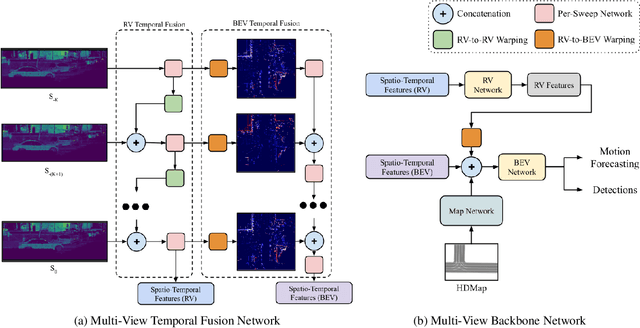
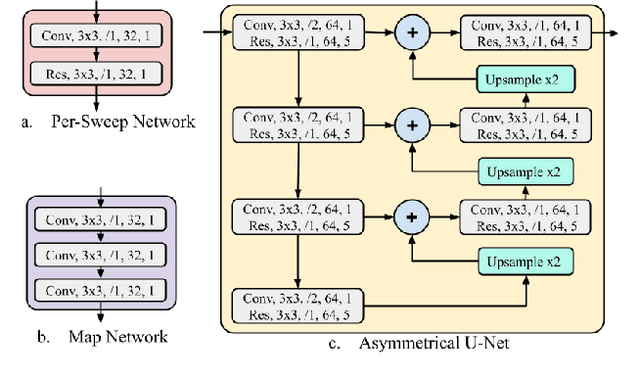
In this work, we propose \textit{MVFuseNet}, a novel end-to-end method for joint object detection and motion forecasting from a temporal sequence of LiDAR data. Most existing methods operate in a single view by projecting data in either range view (RV) or bird's eye view (BEV). In contrast, we propose a method that effectively utilizes both RV and BEV for spatio-temporal feature learning as part of a temporal fusion network as well as for multi-scale feature learning in the backbone network. Further, we propose a novel sequential fusion approach that effectively utilizes multiple views in the temporal fusion network. We show the benefits of our multi-view approach for the tasks of detection and motion forecasting on two large-scale self-driving data sets, achieving state-of-the-art results. Furthermore, we show that MVFusenet scales well to large operating ranges while maintaining real-time performance.
Multi-View Fusion of Sensor Data for Improved Perception and Prediction in Autonomous Driving
Aug 27, 2020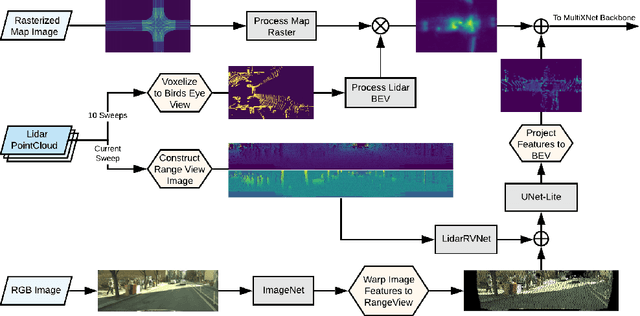
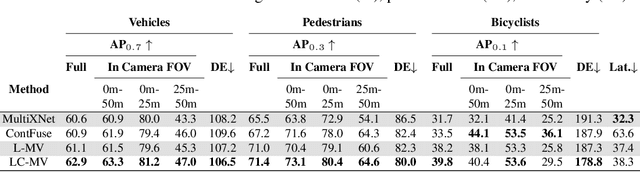
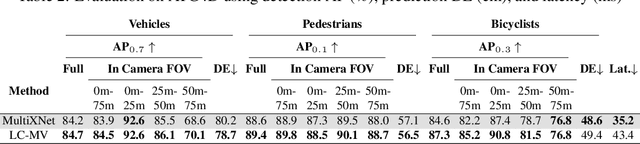
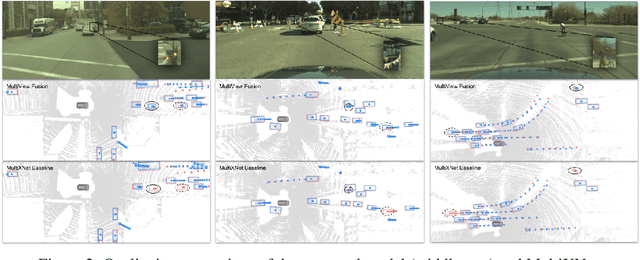
We present an end-to-end method for object detection and trajectory prediction utilizing multi-view representations of LiDAR returns. Our method builds on a state-of-the-art Bird's-Eye View (BEV) network that fuses voxelized features from a sequence of historical LiDAR data as well as rasterized high-definition map to perform detection and prediction tasks. We extend the BEV network with additional LiDAR Range-View (RV) features that use the raw LiDAR information in its native, non-quantized representation. The RV feature map is projected into BEV and fused with the BEV features computed from LiDAR and high-definition map. The fused features are then further processed to output the final detections and trajectories, within a single end-to-end trainable network. In addition, using this framework the RV fusion of LiDAR and camera is performed in a straightforward and computational efficient manner. The proposed approach improves the state-of-the-art on proprietary large-scale real-world data collected by a fleet of self-driving vehicles, as well as on the public nuScenes data set.
LaserFlow: Efficient and Probabilistic Object Detection and Motion Forecasting
Apr 21, 2020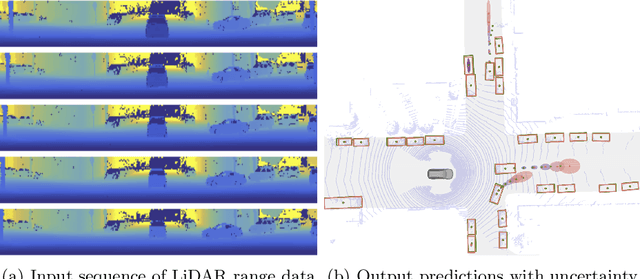
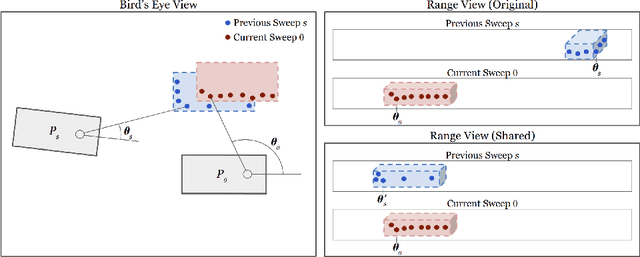
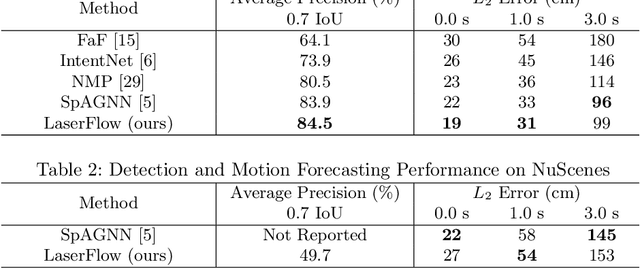
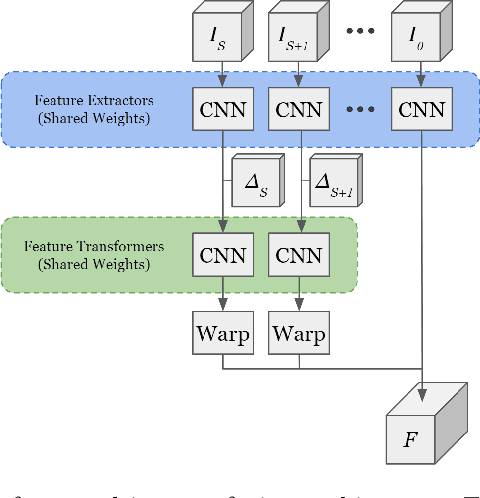
In this work, we present LaserFlow, an efficient method for 3D object detection and motion forecasting from LiDAR. Unlike the previous work, our approach utilizes the native range view representation of the LiDAR, which enables our method to operate at the full range of the sensor in real-time without voxelization or compression of the data. We propose a new multi-sweep fusion architecture, which extracts and merges temporal features directly from the range images. Furthermore, we propose a novel technique for learning a probability distribution over future trajectories inspired by curriculum learning. We evaluate LaserFlow on two autonomous driving datasets and demonstrate competitive results when compared to the existing state-of-the-art methods.