 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiXNet: Multiclass Multistage Multimodal Motion Prediction
Jun 10, 2020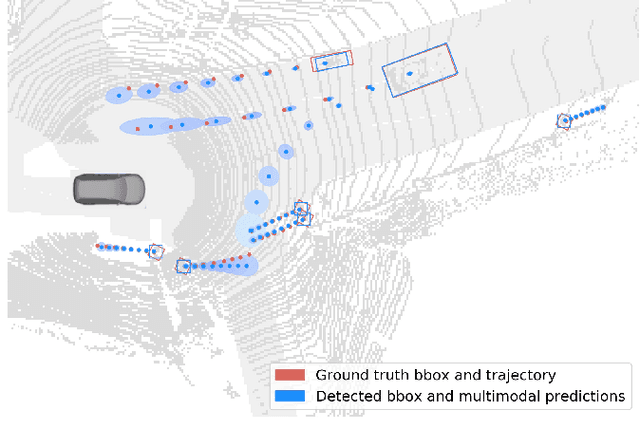
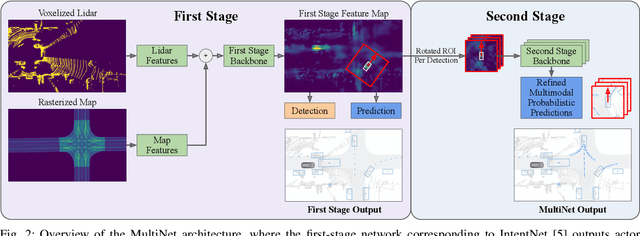
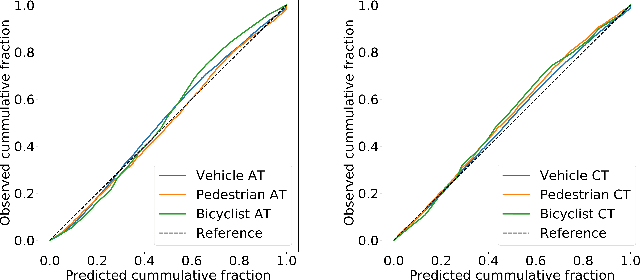
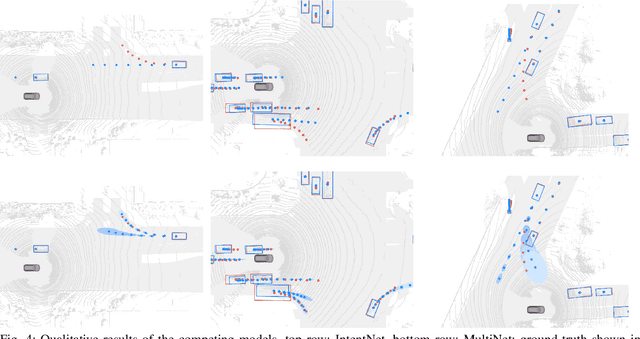
One of the critical pieces of the self-driving puzzle is understanding the surroundings of the self-driving vehicle (SDV) and predicting how these surroundings will change in the near future. To address this task we propose MultiXNet, an end-to-end approach for detection and motion prediction based directly on lidar sensor data. This approach builds on prior work by handling multiple classes of traffic actors, adding a jointly trained second-stage trajectory refinement step, and producing a multimodal probability distribution over future actor motion that includes both multiple discrete traffic behaviors and calibrated continuous uncertainties. The method was evaluated on a large-scale, real-world data set collected by a fleet of SDVs in several cities, with the results indicating that it outperforms existing state-of-the-art approaches.
LaserFlow: Efficient and Probabilistic Object Detection and Motion Forecasting
Apr 21, 2020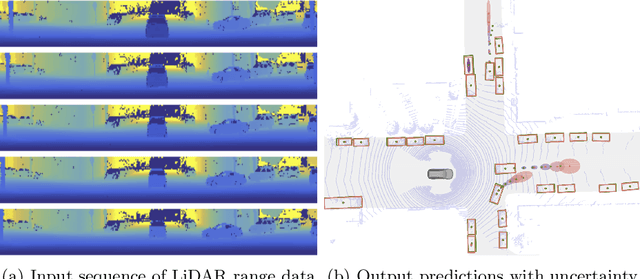
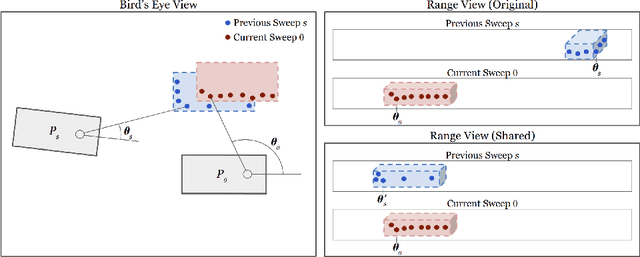
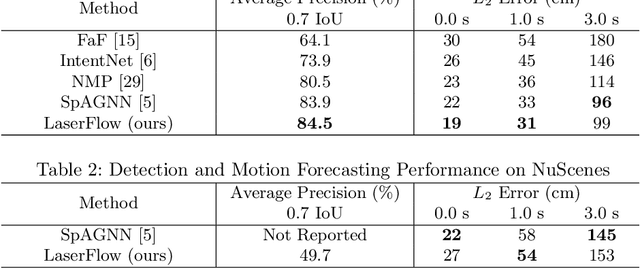
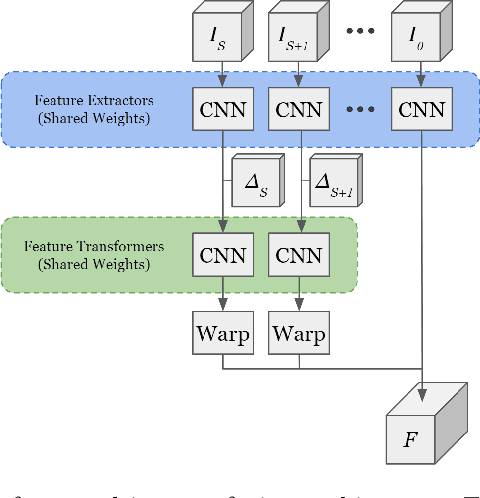
In this work, we present LaserFlow, an efficient method for 3D object detection and motion forecasting from LiDAR. Unlike the previous work, our approach utilizes the native range view representation of the LiDAR, which enables our method to operate at the full range of the sensor in real-time without voxelization or compression of the data. We propose a new multi-sweep fusion architecture, which extracts and merges temporal features directly from the range images. Furthermore, we propose a novel technique for learning a probability distribution over future trajectories inspired by curriculum learning. We evaluate LaserFlow on two autonomous driving datasets and demonstrate competitive results when compared to the existing state-of-the-art methods.
LaserNet: An Efficient Probabilistic 3D Object Detector for Autonomous Driving
Mar 20, 2019

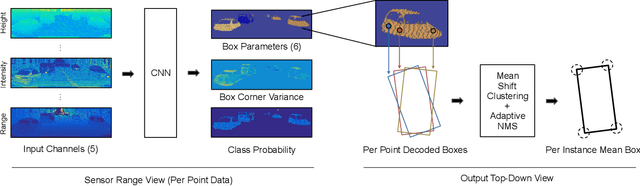
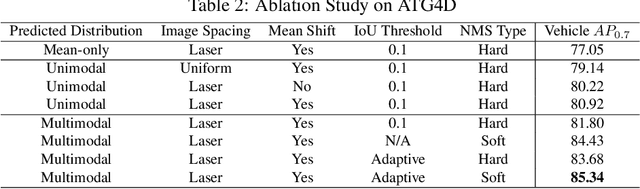
In this paper, we present LaserNet, a computationally efficient method for 3D object detection from LiDAR data for autonomous driving. The efficiency results from processing LiDAR data in the native range view of the sensor, where the input data is naturally compact. Operating in the range view involves well known challenges for learning, including occlusion and scale variation, but it also provides contextual information based on how the sensor data was captured. Our approach uses a fully convolutional network to predict a multimodal distribution over 3D boxes for each point and then it efficiently fuses these distributions to generate a prediction for each object. Experiments show that modeling each detection as a distribution rather than a single deterministic box leads to better overall detection performance. Benchmark results show that this approach has significantly lower runtime than other recent detectors and that it achieves state-of-the-art performance when compared on a large dataset that has enough data to overcome the challenges of training on the range view.