 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTT: Stateful Tracking with Transformers for Autonomous Driving
Apr 30, 2024Tracking objects in three-dimensional space is critical for autonomous driving. To ensure safety while driving, the tracker must be able to reliably track objects across frames and accurately estimate their states such as velocity and acceleration in the present. Existing works frequently focus on the association task while either neglecting the model performance on state estimation or deploying complex heuristics to predict the states. In this paper, we propose STT, a Stateful Tracking model built with Transformers, that can consistently track objects in the scenes while also predicting their states accurately. STT consumes rich appearance, geometry, and motion signals through long term history of detections and is jointly optimized for both data association and state estimation tasks. Since the standard tracking metrics like MOTA and MOTP do not capture the combined performance of the two tasks in the wider spectrum of object states, we extend them with new metrics called S-MOTA and MOTPS that address this limitation. STT achieves competitive real-time performance on the Waymo Open Dataset.
3D Open-Vocabulary Panoptic Segmentation with 2D-3D Vision-Language Distillation
Jan 04, 2024



3D panoptic segmentation is a challenging perception task, which aims to predict both semantic and instance annotations for 3D points in a scene. Although prior 3D panoptic segmentation approaches have achieved great performance on closed-set benchmarks, generalizing to novel categories remains an open problem. For unseen object categories, 2D open-vocabulary segmentation has achieved promising results that solely rely on frozen CLIP backbones and ensembling multiple classification outputs. However, we find that simply extending these 2D models to 3D does not achieve good performance due to poor per-mask classification quality on novel categories. In this paper, we propose the first method to tackle 3D open-vocabulary panoptic segmentation. Our model takes advantage of the fusion between learnable LiDAR features and dense frozen vision CLIP features, using a single classification head to make predictions for both base and novel classes. To further improve the classification performance on novel classes and leverage the CLIP model, we propose two novel loss functions: object-level distillation loss and voxel-level distillation loss. Our experiments on the nuScenes and SemanticKITTI datasets show that our method outperforms strong baselines by a large margin.
MultiXNet: Multiclass Multistage Multimodal Motion Prediction
Jun 10, 2020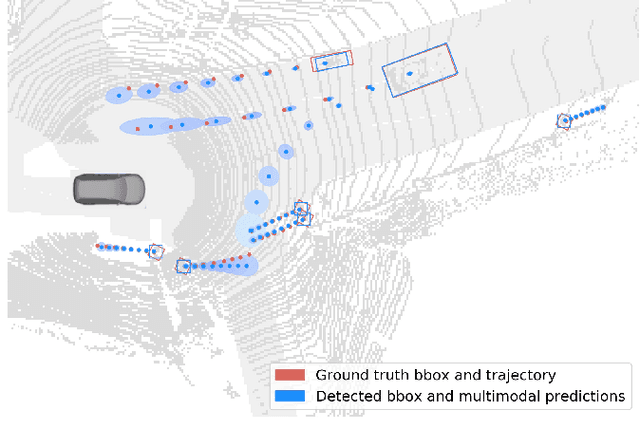
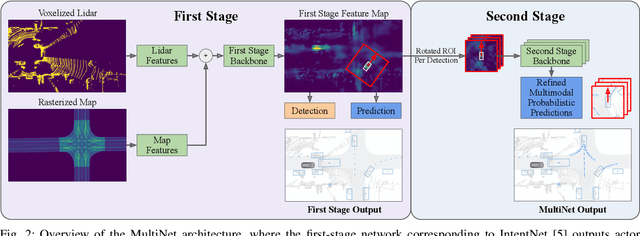
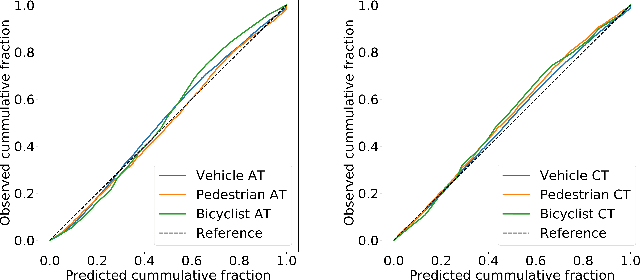
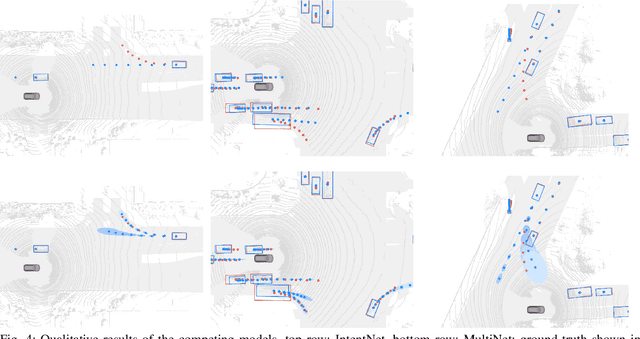
One of the critical pieces of the self-driving puzzle is understanding the surroundings of the self-driving vehicle (SDV) and predicting how these surroundings will change in the near future. To address this task we propose MultiXNet, an end-to-end approach for detection and motion prediction based directly on lidar sensor data. This approach builds on prior work by handling multiple classes of traffic actors, adding a jointly trained second-stage trajectory refinement step, and producing a multimodal probability distribution over future actor motion that includes both multiple discrete traffic behaviors and calibrated continuous uncertainties. The method was evaluated on a large-scale, real-world data set collected by a fleet of SDVs in several cities, with the results indicating that it outperforms existing state-of-the-art approaches.
Image Labeling with Markov Random Fields and Conditional Random Fields
Nov 28, 2018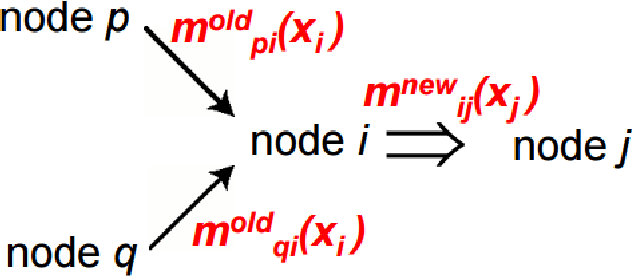

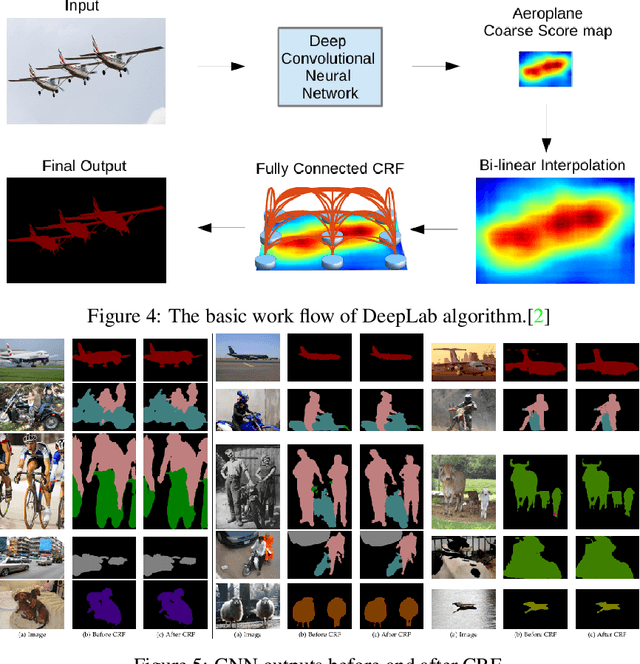
Most existing methods for object segmentation in computer vision are formulated as a labeling task. This, in general, could be transferred to a pixel-wise label assignment task, which is quite similar to the structure of hidden Markov random field. In terms of Markov random field, each pixel can be regarded as a state and has a transition probability to its neighbor pixel, the label behind each pixel is a latent variable and has an emission probability from its corresponding state. In this paper, we reviewed several modern image labeling methods based on Markov random field and conditional random Field. And we compare the result of these methods with some classical image labeling methods. The experiment demonstrates that the introduction of Markov random field and conditional random field make a big difference in the segmentation result.
CycleGAN Face-off
Jul 04, 2018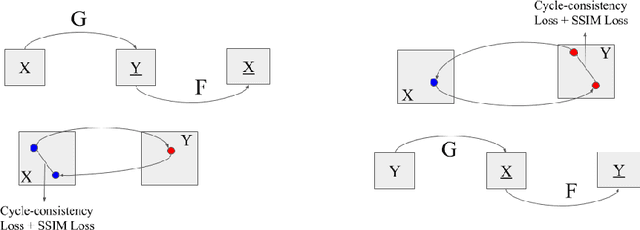
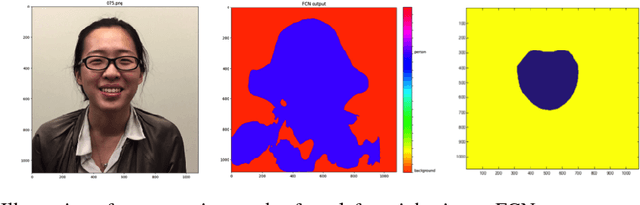
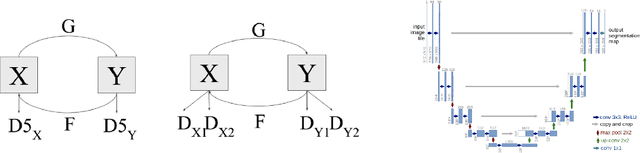

Face-off is an interesting case of style transfer where the facial expressions and attributes of one person could be fully transformed to another face. We are interested in the unsupervised training process which only requires two sequences of unaligned video frames from each person and learns what shared attributes to extract automatically. In this project, we explored various improvements for adversarial training (i.e. CycleGAN[Zhu et al., 2017]) to capture details in facial expressions and head poses and thus generate transformation videos of higher consistency and stability.
Rotational Rectification Network: Enabling Pedestrian Detection for Mobile Vision
Sep 12, 2017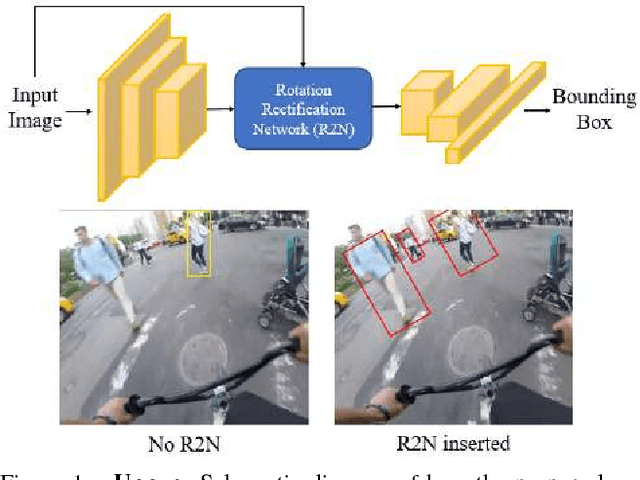
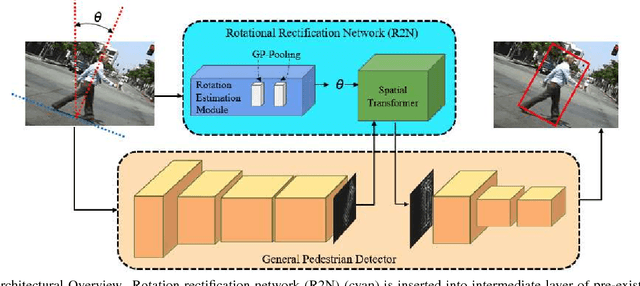
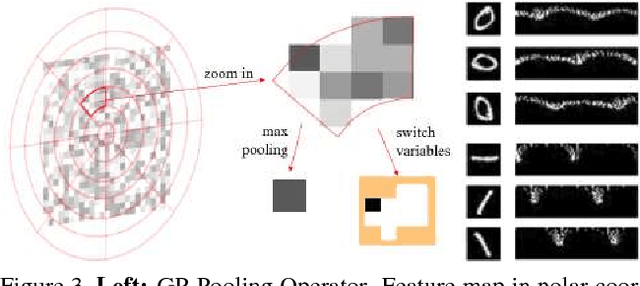
Across a majority of pedestrian detection datasets, it is typically assumed that pedestrians will be standing upright with respect to the image coordinate system. This assumption, however, is not always valid for many vision-equipped mobile platforms such as mobile phones, UAVs or construction vehicles on rugged terrain. In these situations, the motion of the camera can cause images of pedestrians to be captured at extreme angles. This can lead to very poor pedestrian detection performance when using standard pedestrian detectors. To address this issue, we propose a Rotational Rectification Network (R2N) that can be inserted into any CNN-based pedestrian (or object) detector to adapt it to significant changes in camera rotation. The rotational rectification network uses a 2D rotation estimation module that passes rotational information to a spatial transformer network to undistort image features. To enable robust rotation estimation, we propose a Global Polar Pooling (GP-Pooling) operator to capture rotational shifts in convolutional features. Through our experiments, we show how our rotational rectification network can be used to improve the performance of the state-of-the-art pedestrian detector under heavy image rotation by up to 45%
An Enhanced Deep Feature Representation for Person Re-identification
Apr 28, 2016
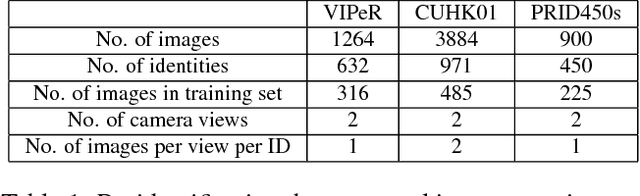
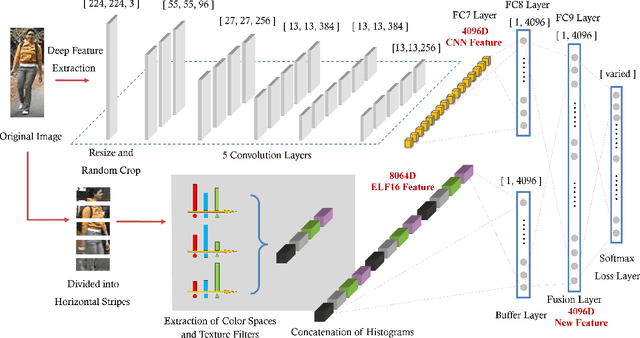
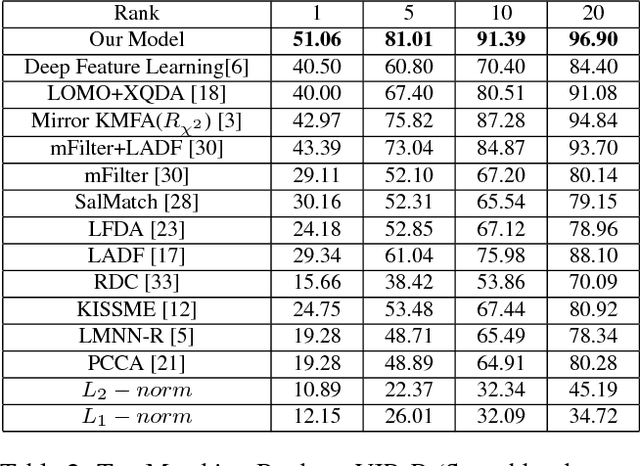
Feature representation and metric learning are two critical components in person re-identification models. In this paper, we focus on the feature representation and claim that hand-crafted histogram features can be complementary to Convolutional Neural Network (CNN) features. We propose a novel feature extraction model called Feature Fusion Net (FFN) for pedestrian image representation. In FFN, back propagation makes CNN features constrained by the handcrafted features. Utilizing color histogram features (RGB, HSV, YCbCr, Lab and YIQ) and texture features (multi-scale and multi-orientation Gabor features), we get a new deep feature representation that is more discriminative and compact. Experiments on three challenging datasets (VIPeR, CUHK01, PRID450s) validates the effectiveness of our proposal.