 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN2N Learning: Network to Network Compression via Policy Gradient Reinforcement Learning
Dec 17, 2017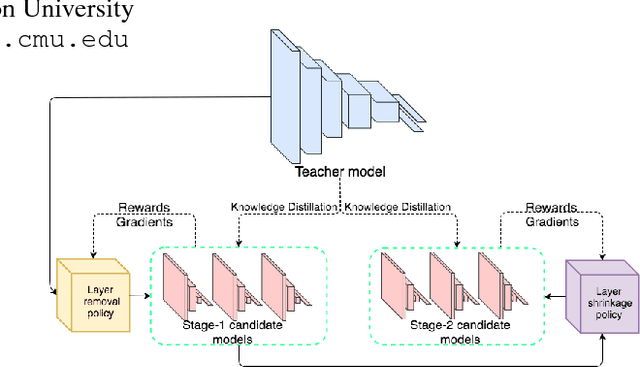
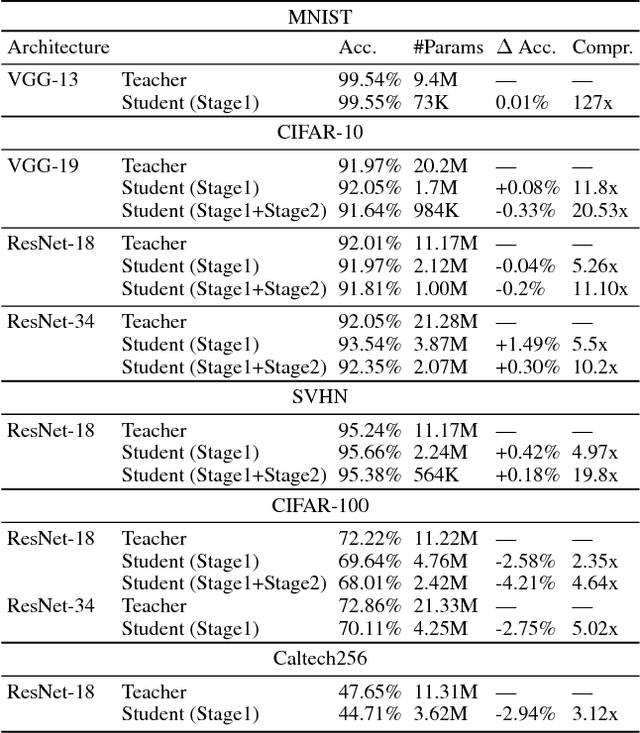
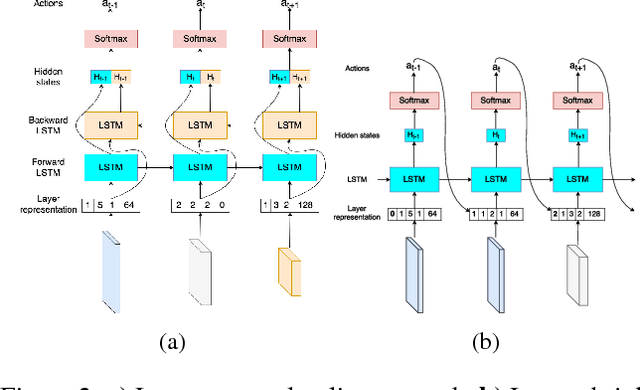
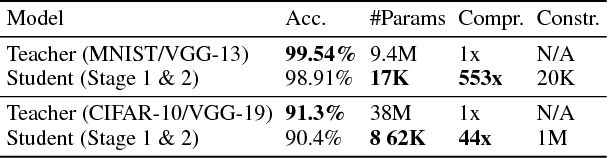
While bigger and deeper neural network architectures continue to advance the state-of-the-art for many computer vision tasks, real-world adoption of these networks is impeded by hardware and speed constraints. Conventional model compression methods attempt to address this problem by modifying the architecture manually or using pre-defined heuristics. Since the space of all reduced architectures is very large, modifying the architecture of a deep neural network in this way is a difficult task. In this paper, we tackle this issue by introducing a principled method for learning reduced network architectures in a data-driven way using reinforcement learning. Our approach takes a larger `teacher' network as input and outputs a compressed `student' network derived from the `teacher' network. In the first stage of our method, a recurrent policy network aggressively removes layers from the large `teacher' model. In the second stage, another recurrent policy network carefully reduces the size of each remaining layer. The resulting network is then evaluated to obtain a reward -- a score based on the accuracy and compression of the network. Our approach uses this reward signal with policy gradients to train the policies to find a locally optimal student network. Our experiments show that we can achieve compression rates of more than 10x for models such as ResNet-34 while maintaining similar performance to the input `teacher' network. We also present a valuable transfer learning result which shows that policies which are pre-trained on smaller `teacher' networks can be used to rapidly speed up training on larger `teacher' networks.
Rotational Rectification Network: Enabling Pedestrian Detection for Mobile Vision
Sep 12, 2017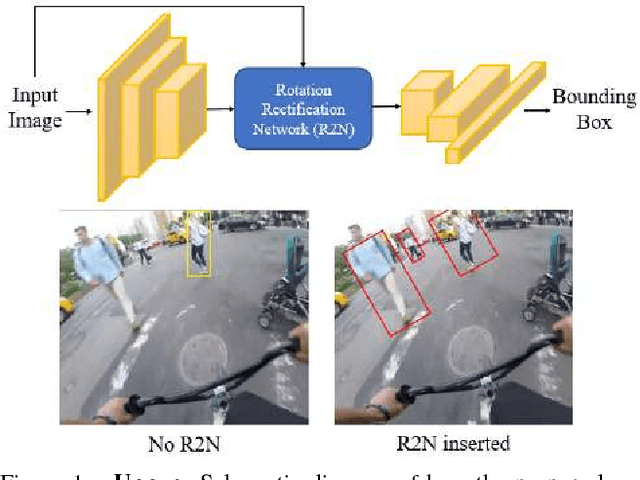
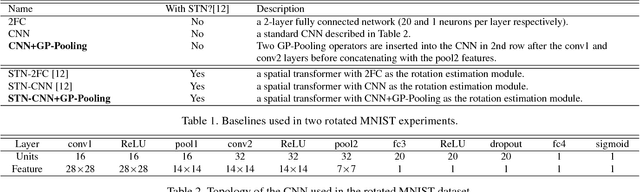
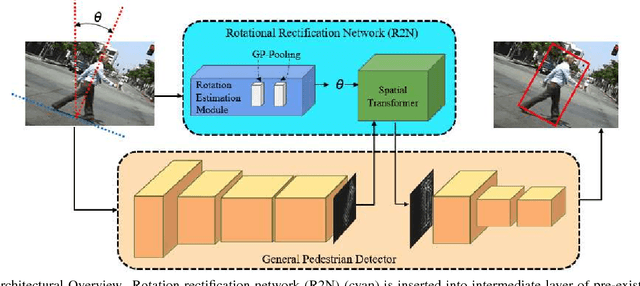
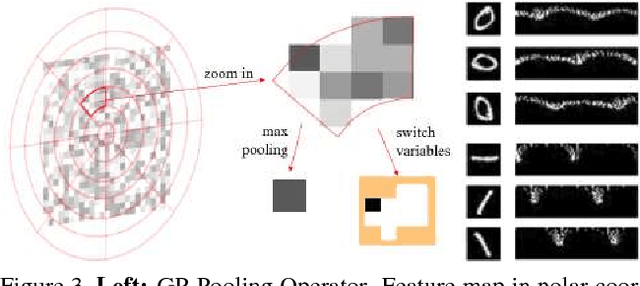
Across a majority of pedestrian detection datasets, it is typically assumed that pedestrians will be standing upright with respect to the image coordinate system. This assumption, however, is not always valid for many vision-equipped mobile platforms such as mobile phones, UAVs or construction vehicles on rugged terrain. In these situations, the motion of the camera can cause images of pedestrians to be captured at extreme angles. This can lead to very poor pedestrian detection performance when using standard pedestrian detectors. To address this issue, we propose a Rotational Rectification Network (R2N) that can be inserted into any CNN-based pedestrian (or object) detector to adapt it to significant changes in camera rotation. The rotational rectification network uses a 2D rotation estimation module that passes rotational information to a spatial transformer network to undistort image features. To enable robust rotation estimation, we propose a Global Polar Pooling (GP-Pooling) operator to capture rotational shifts in convolutional features. Through our experiments, we show how our rotational rectification network can be used to improve the performance of the state-of-the-art pedestrian detector under heavy image rotation by up to 45%
Visual Compiler: Synthesizing a Scene-Specific Pedestrian Detector and Pose Estimator
Dec 15, 2016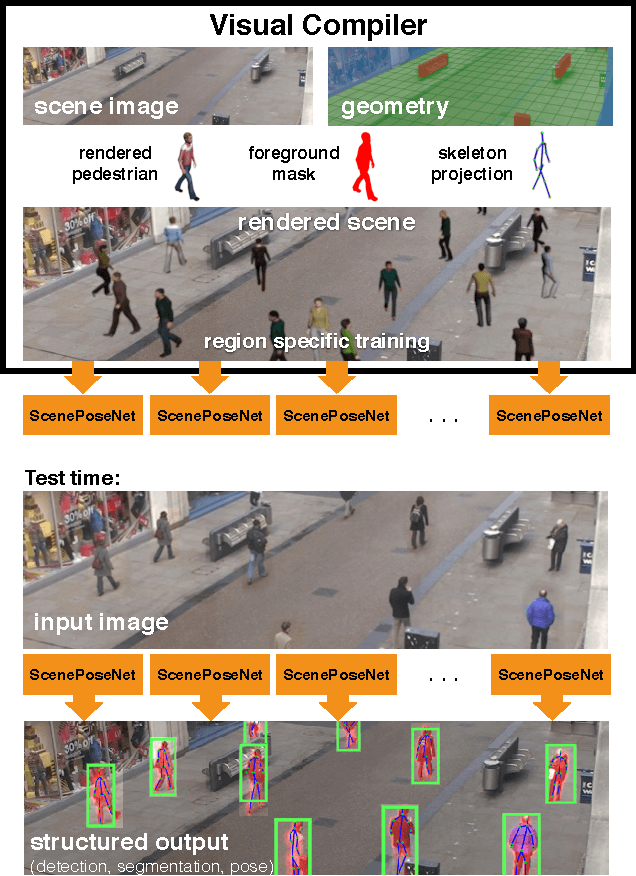


We introduce the concept of a Visual Compiler that generates a scene specific pedestrian detector and pose estimator without any pedestrian observations. Given a single image and auxiliary scene information in the form of camera parameters and geometric layout of the scene, the Visual Compiler first infers geometrically and photometrically accurate images of humans in that scene through the use of computer graphics rendering. Using these renders we learn a scene-and-region specific spatially-varying fully convolutional neural network, for simultaneous detection, pose estimation and segmentation of pedestrians. We demonstrate that when real human annotated data is scarce or non-existent, our data generation strategy can provide an excellent solution for bootstrapping human detection and pose estimation. Experimental results show that our approach outperforms off-the-shelf state-of-the-art pedestrian detectors and pose estimators that are trained on real data.