 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigenFairing: 3D Model Fairing using Image Coherence
Jun 10, 2022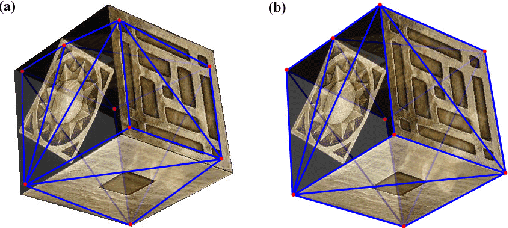
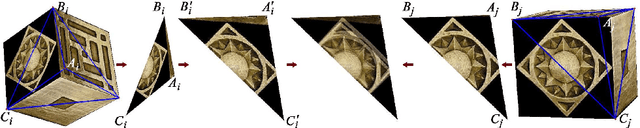

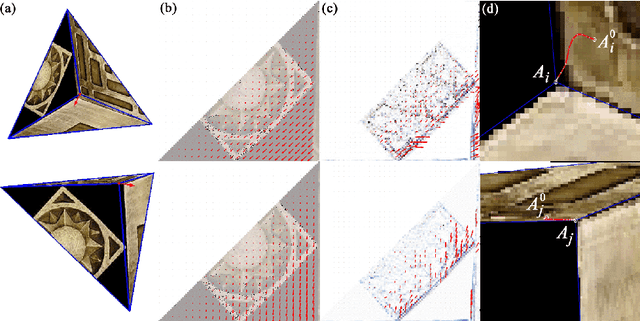
A surface is often modeled as a triangulated mesh of 3D points and textures associated with faces of the mesh. The 3D points could be either sampled from range data or derived from a set of images using a stereo or Structure-from-Motion algorithm. When the points do not lie at critical points of maximum curvature or discontinuities of the real surface, faces of the mesh do not lie close to the modeled surface. This results in textural artifacts, and the model is not perfectly coherent with a set of actual images -- the ones that are used to texture-map its mesh. This paper presents a technique for perfecting the 3D surface model by repositioning its vertices so that it is coherent with a set of observed images of the object. The textural artifacts and incoherence with images are due to the non-planarity of a surface patch being approximated by a planar face, as observed from multiple viewpoints. Image areas from the viewpoints are used to represent texture for the patch in Eigenspace. The Eigenspace representation captures variations of texture, which we seek to minimize. A coherence measure based on the difference between the face textures reconstructed from Eigenspace and the actual images is used to reposition the vertices so that the model is improved or faired. We refer to this technique of model refinement as EigenFairing, by which the model is faired, both geometrically and texturally, to better approximate the real surface.
* British Machine Vision Conference, BMVC 2004, Kingston, UK, September 7-9, 2004
ReshapeGAN: Object Reshaping by Providing A Single Reference Image
May 16, 2019

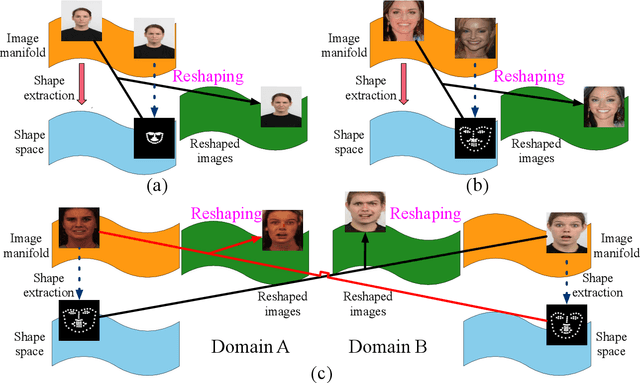
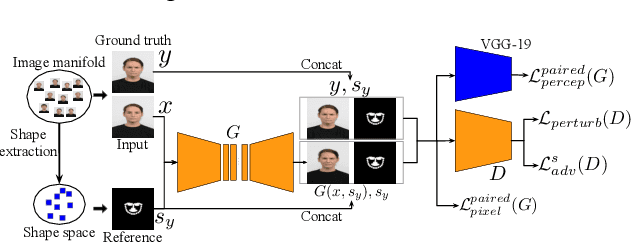
The aim of this work is learning to reshape the object in an input image to an arbitrary new shape, by just simply providing a single reference image with an object instance in the desired shape. We propose a new Generative Adversarial Network (GAN) architecture for such an object reshaping problem, named ReshapeGAN. The network can be tailored for handling all kinds of problem settings, including both within-domain (or single-dataset) reshaping and cross-domain (typically across mutiple datasets) reshaping, with paired or unpaired training data. The appearance of the input object is preserved in all cases, and thus it is still identifiable after reshaping, which has never been achieved as far as we are aware. We present the tailored models of the proposed ReshapeGAN for all the problem settings, and have them tested on 8 kinds of reshaping tasks with 13 different datasets, demonstrating the ability of ReshapeGAN on generating convincing and superior results for object reshaping. To the best of our knowledge, we are the first to be able to make one GAN framework work on all such object reshaping tasks, especially the cross-domain tasks on handling multiple diverse datasets. We present here both ablation studies on our proposed ReshapeGAN models and comparisons with the state-of-the-art models when they are made comparable, using all kinds of applicable metrics that we are aware of.
Face Alignment Robust to Pose, Expressions and Occlusions
Jul 19, 2017
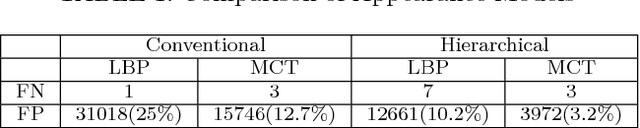
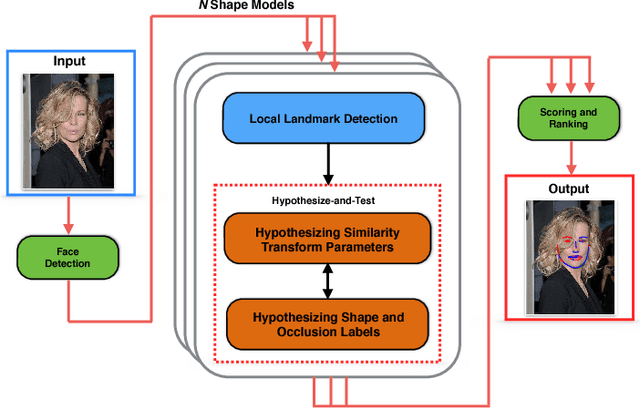
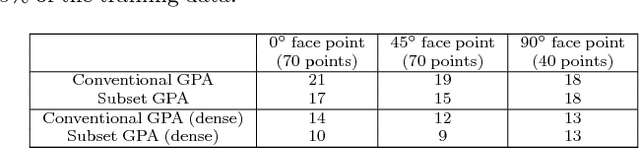
We propose an Ensemble of Robust Constrained Local Models for alignment of faces in the presence of significant occlusions and of any unknown pose and expression. To account for partial occlusions we introduce, Robust Constrained Local Models, that comprises of a deformable shape and local landmark appearance model and reasons over binary occlusion labels. Our occlusion reasoning proceeds by a hypothesize-and-test search over occlusion labels. Hypotheses are generated by Constrained Local Model based shape fitting over randomly sampled subsets of landmark detector responses and are evaluated by the quality of face alignment. To span the entire range of facial pose and expression variations we adopt an ensemble of independent Robust Constrained Local Models to search over a discretized representation of pose and expression. We perform extensive evaluation on a large number of face images, both occluded and unoccluded. We find that our face alignment system trained entirely on facial images captured "in-the-lab" exhibits a high degree of generalization to facial images captured "in-the-wild". Our results are accurate and stable over a wide spectrum of occlusions, pose and expression variations resulting in excellent performance on many real-world face datasets.
Visual Compiler: Synthesizing a Scene-Specific Pedestrian Detector and Pose Estimator
Dec 15, 2016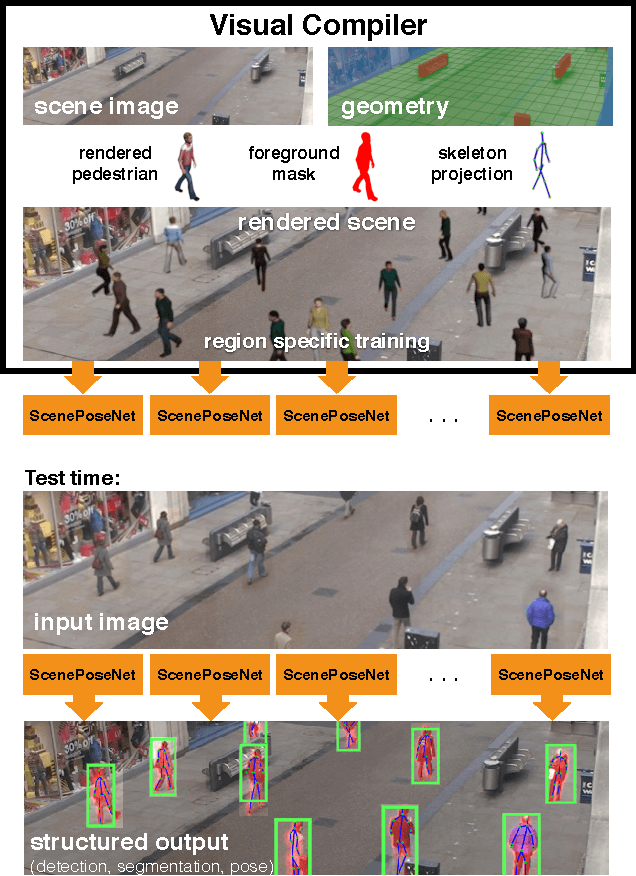

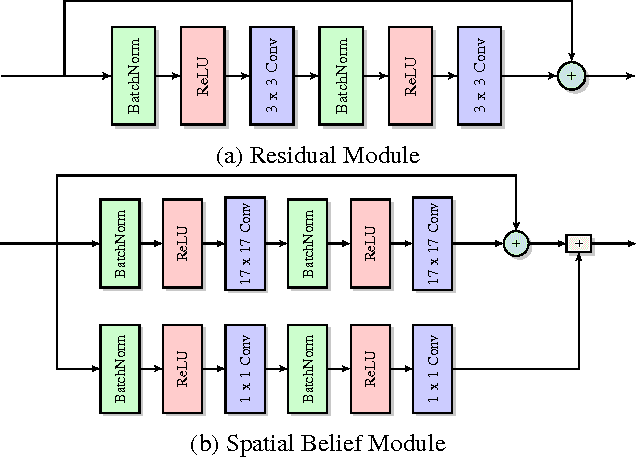

We introduce the concept of a Visual Compiler that generates a scene specific pedestrian detector and pose estimator without any pedestrian observations. Given a single image and auxiliary scene information in the form of camera parameters and geometric layout of the scene, the Visual Compiler first infers geometrically and photometrically accurate images of humans in that scene through the use of computer graphics rendering. Using these renders we learn a scene-and-region specific spatially-varying fully convolutional neural network, for simultaneous detection, pose estimation and segmentation of pedestrians. We demonstrate that when real human annotated data is scarce or non-existent, our data generation strategy can provide an excellent solution for bootstrapping human detection and pose estimation. Experimental results show that our approach outperforms off-the-shelf state-of-the-art pedestrian detectors and pose estimators that are trained on real data.
Panoptic Studio: A Massively Multiview System for Social Interaction Capture
Dec 09, 2016



We present an approach to capture the 3D motion of a group of people engaged in a social interaction. The core challenges in capturing social interactions are: (1) occlusion is functional and frequent; (2) subtle motion needs to be measured over a space large enough to host a social group; (3) human appearance and configuration variation is immense; and (4) attaching markers to the body may prime the nature of interactions. The Panoptic Studio is a system organized around the thesis that social interactions should be measured through the integration of perceptual analyses over a large variety of view points. We present a modularized system designed around this principle, consisting of integrated structural, hardware, and software innovations. The system takes, as input, 480 synchronized video streams of multiple people engaged in social activities, and produces, as output, the labeled time-varying 3D structure of anatomical landmarks on individuals in the space. Our algorithm is designed to fuse the "weak" perceptual processes in the large number of views by progressively generating skeletal proposals from low-level appearance cues, and a framework for temporal refinement is also presented by associating body parts to reconstructed dense 3D trajectory stream. Our system and method are the first in reconstructing full body motion of more than five people engaged in social interactions without using markers. We also empirically demonstrate the impact of the number of views in achieving this goal.
How useful is photo-realistic rendering for visual learning?
Sep 08, 2016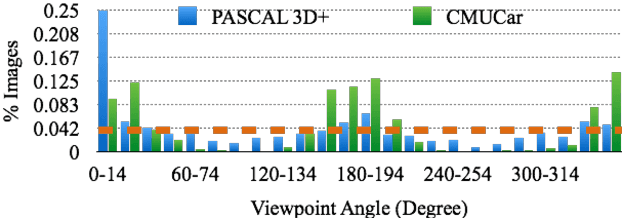
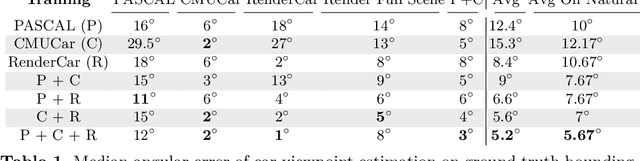


Data seems cheap to get, and in many ways it is, but the process of creating a high quality labeled dataset from a mass of data is time-consuming and expensive. With the advent of rich 3D repositories, photo-realistic rendering systems offer the opportunity to provide nearly limitless data. Yet, their primary value for visual learning may be the quality of the data they can provide rather than the quantity. Rendering engines offer the promise of perfect labels in addition to the data: what the precise camera pose is; what the precise lighting location, temperature, and distribution is; what the geometry of the object is. In this work we focus on semi-automating dataset creation through use of synthetic data and apply this method to an important task -- object viewpoint estimation. Using state-of-the-art rendering software we generate a large labeled dataset of cars rendered densely in viewpoint space. We investigate the effect of rendering parameters on estimation performance and show realism is important. We show that generalizing from synthetic data is not harder than the domain adaptation required between two real-image datasets and that combining synthetic images with a small amount of real data improves estimation accuracy.
Convolutional Pose Machines
Apr 12, 2016
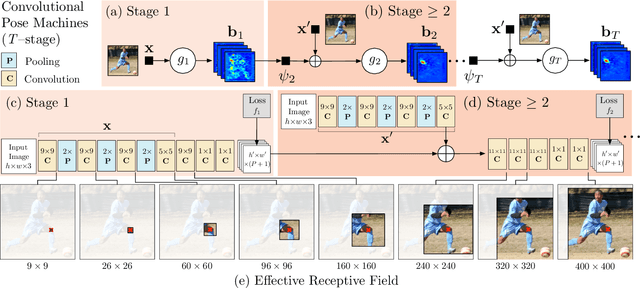

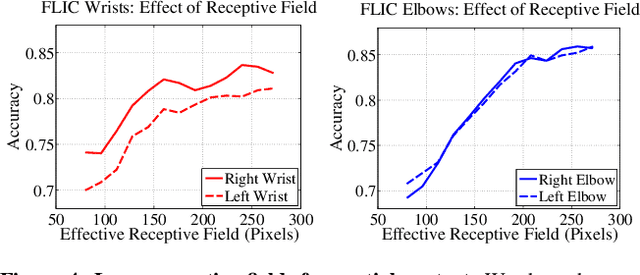
Pose Machines provide a sequential prediction framework for learning rich implicit spatial models. In this work we show a systematic design for how convolutional networks can be incorporated into the pose machine framework for learning image features and image-dependent spatial models for the task of pose estimation. The contribution of this paper is to implicitly model long-range dependencies between variables in structured prediction tasks such as articulated pose estimation. We achieve this by designing a sequential architecture composed of convolutional networks that directly operate on belief maps from previous stages, producing increasingly refined estimates for part locations, without the need for explicit graphical model-style inference. Our approach addresses the characteristic difficulty of vanishing gradients during training by providing a natural learning objective function that enforces intermediate supervision, thereby replenishing back-propagated gradients and conditioning the learning procedure. We demonstrate state-of-the-art performance and outperform competing methods on standard benchmarks including the MPII, LSP, and FLIC datasets.
Emotional Expression Classification using Time-Series Kernels
Jun 08, 2013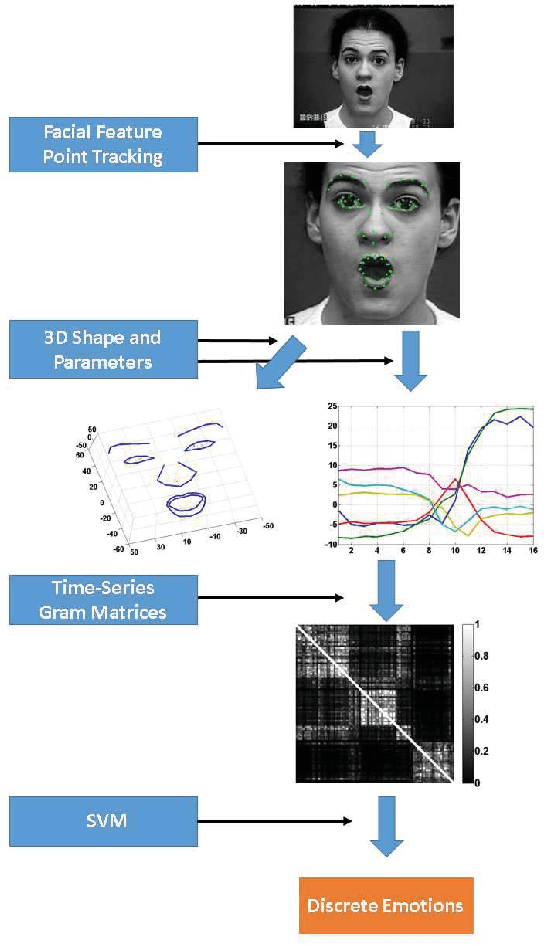

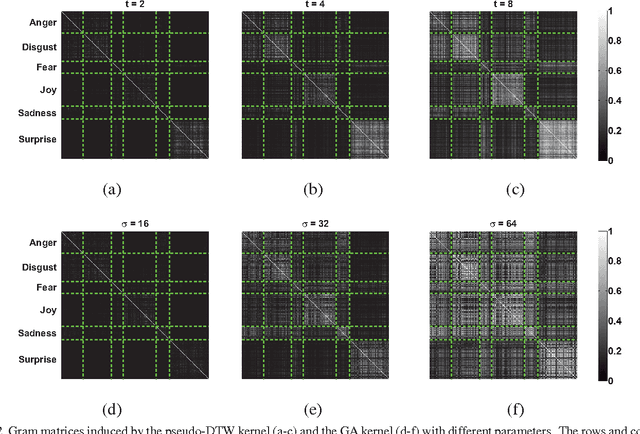
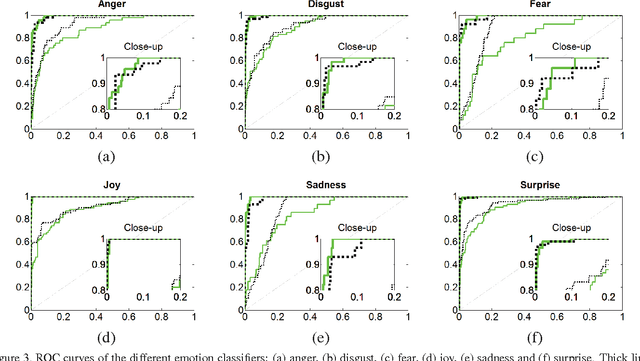
Estimation of facial expressions, as spatio-temporal processes, can take advantage of kernel methods if one considers facial landmark positions and their motion in 3D space. We applied support vector classification with kernels derived from dynamic time-warping similarity measures. We achieved over 99% accuracy - measured by area under ROC curve - using only the 'motion pattern' of the PCA compressed representation of the marker point vector, the so-called shape parameters. Beyond the classification of full motion patterns, several expressions were recognized with over 90% accuracy in as few as 5-6 frames from their onset, about 200 milliseconds.
Maximum Entropy for Collaborative Filtering
Jul 11, 2012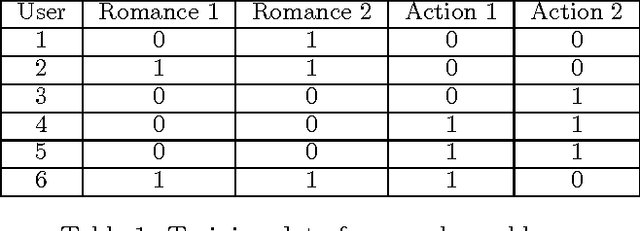
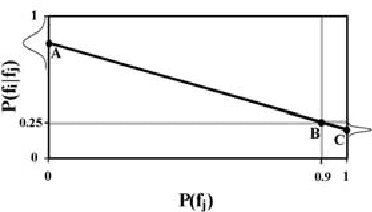


Within the task of collaborative filtering two challenges for computing conditional probabilities exist. First, the amount of training data available is typically sparse with respect to the size of the domain. Thus, support for higher-order interactions is generally not present. Second, the variables that we are conditioning upon vary for each query. That is, users label different variables during each query. For this reason, there is no consistent input to output mapping. To address these problems we purpose a maximum entropy approach using a non-standard measure of entropy. This approach can be simplified to solving a set of linear equations that can be efficiently solved.